

Java线程池
1、线程池
就是管理线程的池子。
优点有:
(1)、降低资源消耗。通过重复利用已经创建的线程池降低线程的创建与销毁造成的消耗
(2)、提高响应速度。当任务到达时,任务可以不需要等待线程的创建就能立即执行
(3)、提高线程的可管理性。线程是稀缺资源,如果无限制的创建不仅消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一调用、调优和监控。
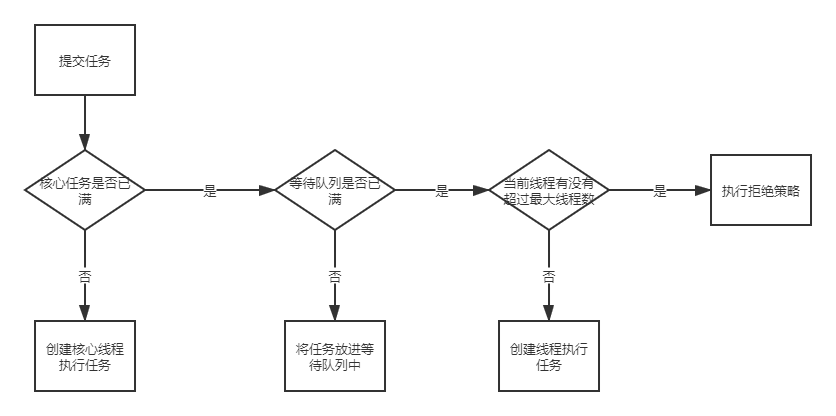
2、线程池的工作流程
3、主要的使用的线程池
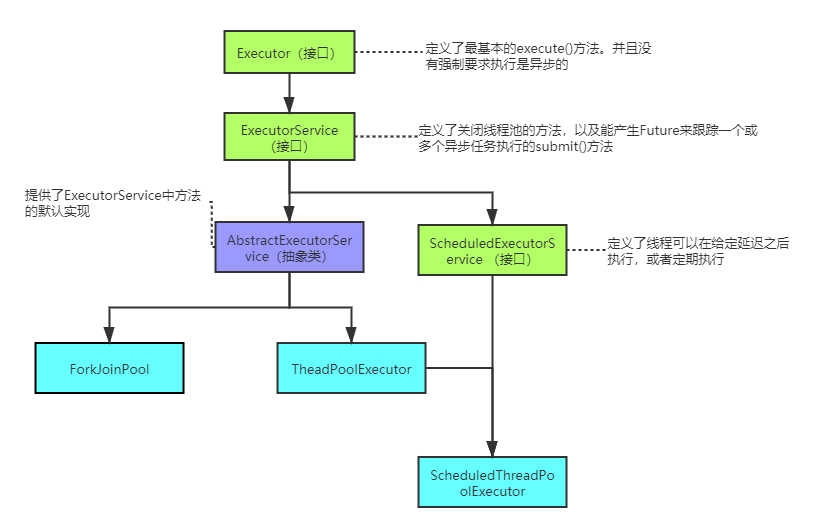
(1)、Executors
创建线程池的工厂类,可以创建Java帮我们封装好的线程池。不过提交任务量特别大的情况下推荐使用TreadPoolExecutor手动创建线程池。因为Executors创建出来的线程池中任务等待队列都是无界队列,可能造成OOM。
1、newSingleThreadPool
只包含一个线程的线程池。默认使用LinkedBlockingQueue来维护一个任务等待队列,非核心线程无任务执行状态存活时间为0ms。
2、newFixedThreadPool
指定线程个数的线程池。默认也是使用linkedBlockingQueue维护一个任务等待队列 ,非核心线程无任务执行状态存活时间为0ms。
3、newCachedTheadPool
核心线程数为0,最大线程数为Integer.MAX_VALUE。里面是一个SynchronousQueue维护任务等待队列,非核心线程无任务执行状态存活时间为60ms。所以当任务很多当前线程池处理不过来时,线程池就会一直不停的创建普通线程。极端情况下会占满内存。
(2)、ThreadPoolExecutor
使用ThradPoolExecutor手动创建线程池可以自定义核心线程、非核心线程数、非核心线程无任务执行状态存活时间等。
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) {.....}
这是ThreadPoolExecutor中的构造方法,有7个参数
1、corePoolSize:核心线程数。每次有任务传进来就会判断核心线程数是否已满,没有即便有空闲线程也会创建一个核心线程来执行。
2、maximumPoolSize:最大线程数。当有任务提交进来,如果核心线程已满,任务队列已满且当前线程数小于最大线程数时就会创建出一个线程执行任务。但是等待队列是一个无界队列这个参数就没有效果。
3、keepAliveTime:非核心线程在设置的这个时间长度没有执行任务就会被销毁。
4、unit:上个时间参数的单位。
5、workQueue:设置等待队列所使用哪种阻塞队列。
6、threadFactory:线程工厂,用于创建线程。
7、handler:拒绝策略。向线程池中提交一个任务时,任务队列已满,且当前线程数等于允许创建最大线程数时,会执行拒绝策略。拒绝策略一般有四种:AbortPolicy(抛出异常)、DiscardPolicy(直接丢弃)、DiscardOldestPolicy(丢弃在队列存在时间最长的任务,也就是即将执行的任务)、CallerRunsPolicy(将任务交给提交任务的那个线程执行)。也可以自定义拒绝策略,实现RejectedExecutionHandler接口,然后重写rejectedExecution方法。
(3)、ScheduleThreadPoolExecutor
用于执行延时任务,或者定时任务。使用的任务队列为DelayWorkQueue。
1 ScheduledExecutorService executorService = new ScheduledThreadPoolExecutor(1, 2 Executors.defaultThreadFactory()); 3 4 //定时任务 5 ScheduledFuture<?> future = executorService.schedule(() -> { 6 System.out.println("5 seconds later"); 7 }, 5, TimeUnit.SECONDS); 8 9 //从第五秒开始执行,并每隔五秒周期执行 10 ScheduledFuture<?> fixedRate = executorService.scheduleAtFixedRate(() -> { 11 System.out.println("每隔5秒的周期任务"); 12 }, 5, 5, TimeUnit.SECONDS);
(4)、ForkJoinPool
ForkJoinPool与ThreadPoolExecutor不同的是:ForkJoinPool中的每个线程都维护了一个队列,当一个线程的本地任务队列全部执行完成后,会尝试向其他线程的任务队列‘偷’任务来执行。当用forkJoinPool来对一个大任务进行分片处理时,ForkJoinPool会用递归的操作来对任务切分直到达到你规定的临界点。
1 //计算长度为1000000的数组中每个元素相加的值 2 public class MyForkJoinPool { 3 private static long sum = 0L; 4 //定义一个长度为一百万的数组,并赋随机值 5 private static int[] nums = new int[1000000]; 6 7 public static void main(String[] args) { 8 9 Random random = new Random(); 10 for (int i = 0; i < nums.length; i++) { 11 nums[i] = random.nextInt(1000); 12 } 13 14 //使用Arrays中的api 15 System.out.println((long)Arrays.stream(nums).sum()); 16 17 18 //使用ForkJoinPool分片计算 19 ForkJoinPool joinPool = new ForkJoinPool(4); 20 AddTask task = new AddTask(0, nums.length, 50000); 21 joinPool.execute(task); 22 System.out.println(task.join()); 23 } 24 25 26 /** 27 * 定义分片任务,如果不需要返回值可以用RecursiveAction 28 */ 29 static class AddTask extends RecursiveTask<Long>{ 30 31 int start; 32 int end; 33 int maxNum; 34 35 AddTask(int start, int end, int maxNum){ 36 this.end = end; 37 this.start = start; 38 this.maxNum = maxNum; 39 } 40 41 @Override 42 protected Long compute() { 43 if (start - end < maxNum){ 44 for (int i = start; i < end; i++) { 45 sum = sum + nums[i]; 46 } 47 return sum; 48 }else { 49 int Middle = start + (end - start)/2; 50 AddTask taskFork1 = new AddTask(start, Middle, 5000); 51 AddTask taskFork2 = new AddTask(start, Middle, 5000); 52 //创建一个新的任务,并挂起当前任务 53 taskFork1.fork(); 54 taskFork2.fork(); 55 56 return taskFork1.join() + taskFork2.join(); 57 58 } 59 } 60 } 61 }
(5)、如何配置核心线程数
如果是cpu密集的任务,一般设置为cpu核心数或cpu核心数 + 1。因为cpu密集性的任务,使用cpu的频率很高,过多的线程会引起大量的线程的上下文切换的消耗。
如果是io密集的任务,可以设置为cpu核心数*2。IO密集性的任务一般执行周期长,可以让cpu在等待IO的时间中,其他的空闲线程执行别的任务,充分利用cpu的时间。
(6)、为什么使用阻塞队列
1、创建线程池消耗比较高,用阻塞队列可以起到一个缓冲的作用。
2、例如LinkedBlocking,在队列满了无法再插入任务进来或者队列为空没有任务可以获取,当前插入或取出线程就会调用await()方法,直至等待其他线程唤醒。
1 public void put(E e) throws InterruptedException { 2 if (e == null) throw new NullPointerException(); 3 final int c; 4 final Node<E> node = new Node<E>(e); 5 final ReentrantLock putLock = this.putLock; 6 final AtomicInteger count = this.count; 7 putLock.lockInterruptibly(); 8 try { 9 while (count.get() == capacity) { 10 notFull.await(); 11 } 12 enqueue(node); 13 c = count.getAndIncrement(); 14 if (c + 1 < capacity) 15 notFull.signal(); 16 } finally { 17 putLock.unlock(); 18 } 19 if (c == 0) 20 signalNotEmpty(); 21 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号