Codeforces 14xx 合集
CF1400
A. String Similarity
不能再水的送分题?有挺多个做法。
首先我们观察到每个要求都包含 \(s_n\),那我们把所有 \(w_i\) 都搞成 \(s_n\) 就一定满足要求。
#include <bits/stdc++.h>
using namespace std;
int t;
int n;
char s[200];
int main() {
scanf("%d", &t);
while (t--) {
scanf("%d", &n);
scanf("%s", s + 1);
for (int i = 1; i <= n; i++) printf("%d", s[n] - '0');
printf("\n");
}
return 0;
}
还有其它的构造方法,比如:\(w_i=s_{2i-1}\)。这样倒过来构造也对。
B - RPG Protagonist
直接贪心是不对的,我们观察题目性质,发现 \(cnt_s\) 很小,这就在提示我们枚举。
有一个贪心还是对的,就是钱少的那个显然买的越多越好。我们不妨设 S 是钱少的那个。
那么我们可以枚举第一个人买了多少 S,这样第二个买了多少也就知道,他们分别还剩多少钱也就清楚了,很容易算出还可以买多少 W。
#include <bits/stdc++.h>
using namespace std;
int t;
int p, f;
int cs, cw;
int s, w;
int ans;
int main() {
cin >> t;
while (t--) {
ans = 0;
cin >> p >> f;
cin >> cs >> cw;
cin >> s >> w;
if (s > w) swap(s, w), swap(cs, cw);
int i = min(p / s + f / s, cs);
for (int j = 0; j <= i && s * j <= p; j++) {
int tmpp = p - s * j;
int tmpf = f - s * (i - j);
if (tmpf < 0) continue;
ans = max(ans, i + min(tmpp / w + tmpf / w, cw));
}
cout << ans << "\n";
}
return 0;
}
C - Binary String Reconstruction
一道不错的模拟题,可是放在2C这个位置是不是有点水?
首先我们显然可以确定 \(w_i\) 是不是 \(0\),因为如果 \(s_{i+x}=0\) 或 \(s_{i-x}=0\) 则 \(w_i\) 一定是 \(0\)。否则令 \(w_i=1\)。
再判断一下是否有 \(s_i=1\) 但是 \(w_{i-x}=0\) 且 \(w_{i+x}=0\) 的情况,如果出现则答案为 \(-1\)。出现这种情况的原因是 \(s_{i-2x}=0\) 且 \(s_{i+2x}=0\)。
#include <bits/stdc++.h>
using namespace std;
int t;
int n, x;
char s[100010], w[100010], ans[100010];
int main() {
cin >> t;
while (t--) {
scanf("%s", s + 1);
cin >> x;
n = strlen(s + 1);
for (int i = 1; i <= n; i++) {
if (i - x > 0 && s[i - x] == '0') w[i] = '0';
else if (i + x <= n && s[i + x] == '0') w[i] = '0';
else w[i] = '1';
}
bool flag = 1;
for (int i = 1; i <= n; i++) {
if (s[i] == '1') {
int cnt = 0;
if (i + x <= n && w[i + x] != '0') cnt++;
if (i - x > 0 && w[i - x] != '0') cnt++;
if (!cnt) flag = 0;
}
}
if (!flag) {
puts("-1");
continue;
}
for (int i = 1; i <= n; i++) cout << w[i];
cout << "\n";
}
return 0;
}
D - Zigzags
看到数据范围很容易想到枚举两个位置。关键是枚举哪两个位置,其实枚举任意两个位置都是可的但是代码复杂度各不相同。
我是尝试枚举 \(i,k\),同时我们统计每个位置之后的每种数有多少个,记为 \(cnt_{i,v}\)。
然后开始枚举,先枚举 \(i\),然后枚举 \(k\),在扩展的时候记录 \(i\rightarrow k\) 这一段内每种数字的个数,记作 \(num_v\),每扩展一个 \(k\),我们需要知道在 \((i,k)\) 和 \((k,n]\) 范围内的共同数字的个数,记为 \(cur\)。那么显然数字 \(a_k\) 和之前的都不能算了,所以要减去 \(num_{a_k}\)。如果 \(a_i=a_k\) 则更新答案。接下来又多了个 \(a_k\),令 \(cur+=cnt[k][a[k]]\),同时 \(num_{a_k}\) 要自增 \(1\)。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
template <typename T> void read(T &x) {
T f = 1;
char ch = getchar();
for (; !isdigit(ch); ch = getchar()) if (ch == '-') f = -1;
for(x = 0; isdigit(ch); ch = getchar()) x = x * 10 + ch - '0';
x *= f;
}
int t;
int n;
int a[3010], cnt[3010][3010], num[3010];
ll ans;
int main() {
read(t);
while (t--) {
ans = 0;
read(n);
for (int i = 1; i <= n; i++) read(a[i]);
for (int i = 1; i <= n + 5; i++) for (int j = 1; j <= n + 5; j++) cnt[i][j] = 0;
for (int i = n - 1; i >= 1; i--) {
for (int j = 1; j <= n; j++) cnt[i][j] = cnt[i + 1][j];
cnt[i][a[i + 1]]++;
}
for (int i = 1; i <= n; i++) {
ll cur = 0;
for (int j = i + 1; j <= n; j++) {
cur -= num[a[j]];
if (a[i] == a[j]) ans += cur;
cur += cnt[j][a[j]];
num[a[j]]++;
}
for (int j = i + 1; j <= n; j++) num[a[j]]--;
}
printf("%lld\n", ans);
}
return 0;
}
赛后发现枚举 \(j,k\) 要简单好多。不过我相信枚举 \(j,k\) 的题解会很多,我这篇题解只是给枚举 \(i,k\) 的但是不知道自己哪里错了的人查错的。另外这也是一种思路。
E - Clear the Multiset
老套路题了,这种题貌似真的很多。考虑一个区间,我们有两种消的办法:
- 全部用方法二
- 先用方法一消到最小值,然后递归去求
肯定不会有人脑抽先用几次方法一再用方法二吧。。。
那么直接按照上面的模拟就好。因为区间不会重复,所以不需要记忆化。
对于第二种消法,我们只需找到一个最小值,根据这个去分区间就行。然后递归求解时记得加一个当前已被消了多少。关于时间复杂度,我们可以把这个递归过程看做一棵树,这个树最多有 \(n\) 层,每层以为区间不重叠所以是 \(O(n)\) 的,总的时间复杂度即为 \(O(n^2)\)。还可以通过 rmq,笛卡尔树等做到 \(O(n\log{n})\),\(O(n)\)。
#include <bits/stdc++.h>
using namespace std;
int n;
int a[5010];
int solve(int l, int r, int lst) {
if (l > r) return 0;
if (l == r) return a[l] > lst;
int mi = l;
for (int i = l + 1; i <= r; i++) if (a[i] < a[mi]) mi = i;
return min(r - l + 1, solve(l, mi - 1, a[mi]) + solve(mi + 1, r, a[mi]) + a[mi] - lst);
}
int main() {
cin >> n;
for (int i = 1; i <= n; i++) cin >> a[i];
cout << solve(1, n, 0);
return 0;
}
F - x-prime Substrings
AC自动机好题。赛时我一直以为是前缀和乱搞,赛后看题解发现是AC自动机觉得很妙。
观察到 \(x\) 很小,我们跑一遍暴力发现所有 x-prime 数的长度的和最大也不超过 \(5000\)(实测应该是 \(x=19\) 时最大)。那问题就变成了总长度不超过 \(5000\) 的模式串和一个文本串问最少从文本串中删去几个字符可以使得文本串不包含任意一个模式串。
多串匹配问题想到AC自动机。这种问题又可以想到动态规划。设 \(dp_{i,j}\) 代表匹配到文本串第 \(i\) 位且当前在AC自动机上的状态 \(j\)。首先下个位置肯定可以删掉,所以 \(dp_{i+1,j}\) 可以为 \(dp_{i,j}+1\)。然后考虑不删下一个字符,则加上下一个字符后一定不能是某个模式串结尾,这可以在 \(fail\) 树上 \(dp\) 求得某个状态是不是某个模式串的结尾。如果不是,则其可以为 \(dp_{i,j}\)。最后的答案就是 \(min(dp_{n,所有状态})\)。
#include <bits/stdc++.h>
using namespace std;
char s[1010];
int n, x;
int t[25], cnt;
int trie[5010][10], tot = 1;
int fail[5010];
queue<int> q;
int dp[1010][5010];
bool End[5010];
bool check() {
for (int i = 1; i <= cnt; i++) {
int now = 0;
for (int j = i; j <= cnt; j++) {
if (i == 1 && j == cnt) continue;
now += t[j];
if (x % now == 0) return false;
}
}
return true;
}
void dfs(int now) {
if (now == 0) {
if (!check()) return;
int p = 1;
for (int i = 1; i <= cnt; i++) {
if (!trie[p][t[i]]) trie[p][t[i]] = ++tot;
p = trie[p][t[i]];
} End[p] = true;
return;
}
for (int i = 1; i <= 9; i++) {
if (i <= now) {
t[++cnt] = i;
dfs(now - i);
cnt--;
}
}
}
int main() {
scanf("%s%d", s + 1, &x);
n = strlen(s + 1);
dfs(x);
fail[1] = 0;
for (int i = 1; i <= 9; i++) trie[0][i] = 1;
q.push(1);
while (!q.empty()) {
int p = q.front();
q.pop();
End[p] |= End[fail[p]];
for (int i = 1; i <= 9; i++) {
if (trie[p][i]) {
fail[trie[p][i]] = trie[fail[p]][i];
q.push(trie[p][i]);
} else {
trie[p][i] = trie[fail[p]][i];
}
}
}
memset(dp, 0x3f, sizeof(dp));
dp[0][1] = 0;
for (int i = 0; i < n; i++) {
for (int j = 1; j <= tot; j++) {
dp[i + 1][j] = min(dp[i + 1][j], dp[i][j] + 1);
if (!End[trie[j][s[i + 1] - '0']]) {
dp[i + 1][trie[j][s[i + 1] - '0']] = min(dp[i + 1][trie[j][s[i + 1] - '0']], dp[i][j]);
}
}
}
int ans = 0x3f3f3f3f;
for (int i = 1; i <= tot; i++) ans = min(ans, dp[n][i]);
printf("%d", ans);
return 0;
}
G - Mercenaries
2020-08-27来补了qwq。
这道题正面不好考虑,尝试用容斥原理来做。
首先对于第一个限制是好求的,我们先求出满足第一个限制的个数。考虑枚举个数 \(s\)。记个数为 \(s\) 时的候选集合大小为 \(cnt_s\),那么答案就会加上 \(C_{cnt_s}^s\)。如何求出 \(cnt_s\)?我们发现就是求有多少个区间 \([l_i,r_i]\) 包含其,那么直接静态区间加,单点求和—差分+前缀和做就好了。
这样子我们得到的全集的大小 \(|S|\)。答案为 \(|S|-|\cup_{k=1}^mS_i|\),其中 \(S_i\) 代表 \(S\) 中同时包含 \(a_i,b_i\) 的方案。后面的东西容斥做就好了。
发现即为 \(\sum(-1)^{k-1}\sum_{U \subseteq M,f(U)=k}\sum_{s=L(U)}^{R(U)}C_{cnt_s-k}^{s-k}\),其中 \(M\) 是所有限制二的选择的集合,\(f(U)\) 代表 \(U\) 内所有涉及的士兵的个数,\(L(U)\) 为 \(U\) 内所有士兵 \([l,r]\) 的并集的下界,\(R(U)\) 即为上界。\(C_{cnt_s-k}^{s-k}\) 则代表要选 \(s\) 个士兵,已经选好了 \(k\) 的士兵,要在剩下 \(cnt_s-k\) 中选 \(s-k\) 个。求并集直接把所有的 \(l\) 取 \(max\),所有 \(r\) 取 \(min\)。我们发现知道了 \(L(U),R(U)\) 后这个东西和 \(U\) 没有具体的关系,所以可以预处理。而 \(k\) 最大其实也就 \(2m\)。所以我们得到了一个预处理 \(O(nm)\),查询 \(O(2^mm)\) 的算法。还有个问题,查询时如何搞出 \(U\) 内的所有士兵?其实不需要用set,直接开一个标记数组,最后把打上标记的数再删除标记即可,时间复杂度 \(O(m)\)。另外预处理阶乘及其逆元可能需要 \(O(n\log{MOD})\) 的时间。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const ll mod = 998244353;
const int MAXN = 300010;
ll n, m, a[MAXN], b[MAXN], l[MAXN], r[MAXN], cnt[MAXN], fac[MAXN], ifac[MAXN], vis[MAXN], num[MAXN][41], stk[41], top, ans;
ll ksm(ll x, ll y) {
ll ret = 1;
while (y) {
if (y & 1) ret = (ret * x) % mod;
x = (x * x) % mod;
y >>= 1;
}
return ret;
}
ll C(ll x, ll y) {
if (x < 0 || y < 0 || x < y) return 0;
return fac[x] * ifac[x - y] % mod * ifac[y] % mod;
}
int main() {
cin >> n >> m;
for (int i = 1; i <= n; i++) cin >> l[i] >> r[i], cnt[l[i]]++, cnt[r[i] + 1]--;
for (int i = 1; i <= n; i++) cnt[i] += cnt[i - 1];
for (int i = 1; i <= m; i++) cin >> a[i] >> b[i];
fac[0] = ifac[0] = 1;
for (int i = 1; i <= n; i++) fac[i] = fac[i - 1] * i % mod, ifac[i] = ifac[i - 1] * ksm(i, mod - 2) % mod;
for (int i = 1; i <= (m << 1); i++) {
for (int j = 1; j <= n; j++) {
num[j][i] = (num[j - 1][i] + C(cnt[j] - i, j - i)) % mod;
}
}
for (int i = 1; i <= n; i++) ans = (ans + C(cnt[i], i)) % mod;
for (int state = 1, flag; state < (1 << m); state++) {
top = 0;
flag = 1;
for (int i = 0; i < m; i++) {
if ((state >> i) & 1) {
flag *= -1;
if (!vis[a[i + 1]]) stk[++top] = a[i + 1];
if (!vis[b[i + 1]]) stk[++top] = b[i + 1];
vis[a[i + 1]] = vis[b[i + 1]] = 1;
}
}
ll L = l[stk[1]], R = r[stk[1]];
for (int i = 2; i <= top; i++) {
L = max(L, l[stk[i]]);
R = min(R, r[stk[i]]);
}
for (int i = 0; i < m; i++) if ((state >> i) & 1) vis[a[i + 1]] = vis[b[i + 1]] = 0;
if (L <= R) ans = (ans + flag * (num[R][top] - num[L - 1][top]) + mod) % mod;
}
cout << ans << "\n";
return 0;
}
CF1443
A Kids Seating
要你构造 \(n\) 个数,每个数的范围是 \([1,4n]\),使得其中任意两个数 \(a,b\) 不满足 \(\gcd(a,b)=1\) 且不满足 \(\gcd(a,b)=a\) 且不满足 \(\gcd(a,b)=b\)
一道一眼构造题。我们发现如果只取偶数的话就不可能出现 \((a,b)=1\) 的情况,而又他的范围那么大,所以如果取 \(2n+2,2n+4,...,4n\) 这 \(n\) 个数一定不会出现后两种情况。这样就构造完了。
#include <bits/stdc++.h>
using namespace std;
int t;
int n;
int main() {
scanf("%d", &t);
while (t--) {
scanf("%d", &n);
for (int i = 4 * n; i > 4 * n - 2 * n; i -= 2) {
printf("%d ", i);
} printf("\n");
}
return 0;
}
B Saving the City
给你两个数 \(a,b\) 和一个长度为 \(n\) 的01字符串。对于一个1的连通块你需要花费 \(a\) 去炸掉它并且你可以花费 \(b\) 去把一个0变成1,求你炸掉所有1的最小花费是多少。
从左往右推,把两个1的连通块之间的0的个数记为 \(x\),如果 \(x\times b<a\) 的话就把这一段填成1,答案加上 \(x \times b\),否则则需一段新的1连通块,答案加上 \(a\)。注意一开始必须有一个1的连通块,即如果存在1的话答案至少为 \(a\)。
#include <bits/stdc++.h>
using namespace std;
int t;
int a, b;
char s[100010];
int n;
long long ans;
int main() {
scanf("%d", &t);
while (t--) {
ans = 0;
scanf("%d%d", &a, &b);
scanf("%s", s + 1);
n = strlen(s + 1);
bool have = false;
int now = 0;
for (int i = 1; i <= n; i++) {
if (s[i] != s[i - 1]) {
if (s[i] == '1') ans += have ? min(now * b, a) : a, have = true;
now = 1;
} else now++;
}
printf("%lld\n", ans);
}
return 0;
}
C The Delivery Dilemma
给你两个数列:\(\{a\},\{b\}\),要你求出 \(\min_{P\subseteq \{1,2,...,n\}}\{\max\{\max_{i \in P}a_i,\sum_{i \notin P}b_i\}\}\)
此题不需要二分答案,直接排序加枚举即可。我们发现在枚举 \(P\) 的时候如果对于一个 \(i \notin P\) 且 \(a_i \le \max_{i \in P}a_i\) 那这个 \(i\) 也包含进来一定更优。所以我们可以先对 \(a\) 排序,枚举前 \(i\) 个人是送外卖的,然后维护一个后缀和就可以了。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const ll inf = 0x3f3f3f3f3f3f3f3f;
struct node{
int a, b;
friend bool operator < (node x, node y) {
return x.a < y.a;
}
}Dish[200010];
int t;
int n;
ll sum, ans;
int main() {
scanf("%d", &t);
while (t--) {
ans = inf;
sum = 0;
scanf("%d", &n);
for (int i = 1; i <= n; i++) scanf("%d", &Dish[i].a);
for (int i = 1; i <= n; i++) scanf("%d", &Dish[i].b);
sort(Dish + 1, Dish + 1 + n);
for (int i = n; i >= 1; i--) {
ans = min(ans, max((ll)Dish[i].a, sum));
sum += Dish[i].b;
}
ans = min(ans, sum);
printf("%lld\n", ans);
}
return 0;
}
D Extreme Subtraction
考虑一个位置至少有几次操作是从最后到它这个位置的?如果 \(a_{i-1}<a_i\) 那么显然是 \(a_{i}-a_{i-1}\),那么 \(a[i...n]\) 这一段数至少减 \(a_{i}-a_{i-1}\),如果把所有这些要减的加在一起,比某个 \(a_x\) 大了那么就是NO,否则就是YES。
为什么不用从后往前做一遍?看一下这张图就懂了。
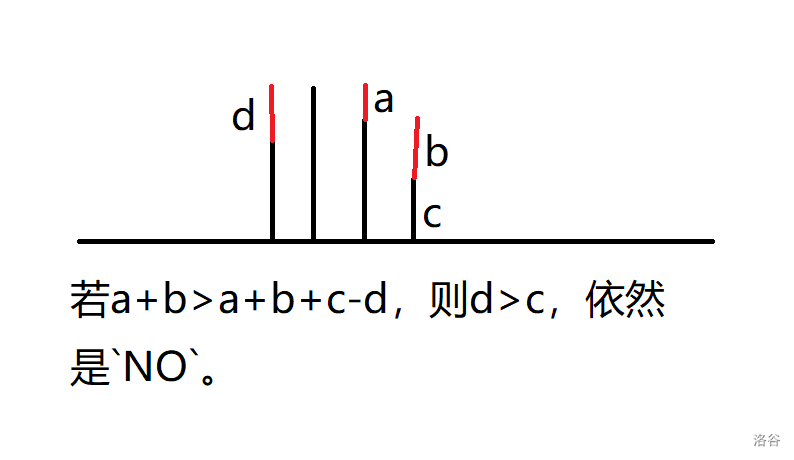
这一类题因为是区间同时减去某数所以有一段的差分数组不变,多往差分上去想。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int inf = 0x3f3f3f3f;
int q;
int n;
int a[100010];
int now;
int main() {
scanf("%d", &q);
while (q--) {
scanf("%d", &n);
for (int i = 1; i <= n; i++) scanf("%d", &a[i]);
now = 0;
bool ans = true;
for (int i = 1; i < n; i++) {
if (now > a[i]) {
ans = false;
break;
}
if (a[i] < a[i + 1]) now += a[i + 1] - a[i];
}
if (now > a[n]) ans = false;
if (ans) puts("YES");
else puts("NO");
}
return 0;
}
E Long Permutation
挺水的一题,可惜赛时不知道F更水,然后花了挺多时间搞这题害的最后没时间写F了/kk/kk/kk。
看到这道题让你实现的就是跳到字典序比当前大一的排列上,而字典序最大为 \(2 \times 10^{10}\),这对于排列的个数来说其实是很小的。保守点说,排列变化的肯定是最后 \(20\) 个数。那么对于前 \(n-20\) 个数维护一个前缀和,后 \(20\) 个数暴力统计就可以做第一问。对于第二个操作,根据排名求排列有个逆康托展开的算法,具体就是挨个确定每个位置是什么数,如果暴力做的话复杂度上限是 \(20^3\),然而到不了所以这题可以过,如果要追求效率的话可以做到 \(20 \times \log^2{20}\) 或者 \(20 \times \log{20}\).
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
int n, q;
ll now = 1;
ll a[200010], cnt[200010];
bool vis[200010];
ll ans;
int main() {
scanf("%d%d", &n, &q);
for (int i = 1; i <= n; i++) a[i] = i, cnt[i] = a[i] + cnt[i - 1];
while (q--) {
int opt, l, r;
scanf("%d", &opt);
if (opt == 1) {
scanf("%d%d", &l, &r);
ans = 0;
if (n > 20) {
if (l < n - 20 && r >= n - 20) {
ans = cnt[n - 21] - cnt[l - 1];
l = n - 20;
for (int i = l; i <= r; i++) {
ans += a[i];
}
} else if (r < n - 20) {
ans = cnt[r] - cnt[l - 1];
} else {
for (int i = l; i <= r; i++) {
ans += a[i];
}
}
} else {
for (int i = l; i <= r; i++) {
ans += a[i];
}
}
printf("%lld\n", ans);
} else {
scanf("%d", &l);
now += l;
ll tmp = now;
ll cur = 1;
int pos;
for (pos = n; pos; pos--) {
if (cur >= now) {
break;
}
cur *= (n - pos + 1);
}
for (int i = pos + 1; i <= n; i++) vis[i] = false;
for (int i = pos + 1; i <= n; i++) {
cur /= (n - i + 1);
for (int j = pos + 1; j <= n; j++) {
if (vis[j]) continue;
ll num = 0;
for (int k = pos + 1; k < i; k++) {
if (a[k] < j) {
num++;
}
}
if (cur * (j - pos - num) >= now) {
now -= cur * (j - pos - num - 1);
a[i] = j;
vis[j] = true;
break;
}
}
}
now = tmp;
}
}
return 0;
}
F Identify the Operations
首先我们发现要想某个数加入 \(b\) 就得把它旁边两个中的一个删掉,然后这是两种情况,所以每次操作最多两种情况,答案肯定是 \(2\) 的倍数。考虑什么情况不是 \(2\)?记录每个数在 \(a\) 中出现的位置 \(p\),如果 \(a_{p_{b_i}+1}\) 是在 \(b\) 中 \(i\) 的后面出现的数,那么一定不能删。如果 \(p_{b_i}=n\) 那么后面的数也没得删,前面同理。于是我们从后往前推,对于每个 \(b_i\) 打上标记,这样就可以 \(O(1)\) 判断了。
为什么只有一开始的位置才影响答案?因为如果想要把旁边的删掉一定要把你这个位置的删掉,而你这个位置在之前有不能删,所以旁边的一定还存在。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const ll mod = 998244353;
const int inf = 0x3f3f3f3f;
int T;
int n, m;
int a[200010], b[200010], pos[200010];
bool vis[200010];
ll ans;
int main() {
scanf("%d", &T);
while (T--) {
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i++) scanf("%d", &a[i]), pos[a[i]] = i, vis[i] = false;
for (int i = 1; i <= m; i++) scanf("%d", &b[i]);
ans = 1;
for (int i = m; i >= 1; i--) {
ll cur = 2;
if (pos[b[i]] == 1 || vis[a[pos[b[i]] - 1]]) cur--;
if (pos[b[i]] == n || vis[a[pos[b[i]] + 1]]) cur--;
ans = (ans * cur) % mod;
vis[b[i]] = true;
}
printf("%lld\n", ans);
}
return 0;
}
CF1496
ABC略
D. Let's Go Hiking
找到所有山峰(注意这里 \(1,N\) 也算)往两边路径最大值,如果有相同那么后手只需和先手选择同样高度的山峰对应的山谷即可获胜。
否则找到唯一的山峰,考虑往两边的路径大小不同,那么后手可以在高的部分调整奇偶性,先手还是必败。否则奇数时必胜。
E. Garden of the Sun
考虑 \(m=3k\) 的情况,把 \(j=2,5,8...\) 全部画X,然后再稍微调整之间的连线即可。
这同样可以做 \(m=3k+2\) 的情况。
\(m=3k+1\) 时最后会多出一行不好考虑。重新在 \(1,4,7...\) 位置画X,然后按上述做法做即可。
F. BFS Trees
数据范围这么小考虑枚举 \(i,j\)。
求出 \(dis[i][j]\) 代表最短路+1。
若 \(dis[i][k]+dis[k][j]=dis[i][j]+1\) 则 k 必在 i,j 最短路上。
如果这样的 k 比 dis[i][j] 多说明有两条以上最短路。
i只会从一条进入,而 j 一定从每条都出去,所以答案是 0 。
然后考虑其他点的贡献,枚举父亲,算出可能有几种情况,乘再一起即为答案。
判断父亲的条件 : \(dis[i][k]=dis[i][fa]+1\and dis[j][k]=dis[j][fa]+1\)。
因为只是算这个点的父亲,所以答案互不影响,可以直接相乘。
A Strange Birthday Party
因为每个人都是等价的所以考虑对 \(k_i\) 排序,从小到大考虑。对于每一个人在所有能选(编号小于等于 \(k_i\))的物品里选一个最小的花费,但是这样不一定是最后的最优解,考虑反悔,即这个人不选这个最优而是给 \(c_{k_i}\) 元钱,那么再添加一个 \(c_{k_i}\) 元的物品即可。为什么每次都只能选最小或不选?因为所选礼物的集合是无序的,则若其选了非最小后面的人选了最小和其选了最小,后面的人选了他刚开始选的那个是等价的。
B Strange Definition
考虑什么情况下两个数相邻,这里有一个结论:对于一个质数 \(p\),\(x\) 中含有 \(a\) 个 \(p\),而 \(y\) 中含有 \(b\) 个 \(p\),若 \(a\equiv b\pmod 2\) 则其有可能成为相邻的。证明:假设 \(a\le b\),则两者的 \(\frac{lcm}{gcd}=b-a\),若为偶数则是完全平方数,否则不是。那么我们对于每个数分解质因数并将其幂次模 \(2\) 得到一个新数,将所有得到的新数一样的数放在一个集合里,这个集合内的数必然都是相邻的。考虑经过一回合后会发生什么。对于一个拥有偶数个数的集合将全部的数乘在一起再将各质因子的幂次模 \(2\) 得到的数一定是 \(1\),那么经过一轮之后所有集合大小是偶数的集合都会并到值为 \(1\) 的集合中,而大小为奇数的集合则不会发生改变。那么我们去模拟这个过程,对于 \(w=0\) 的询问输出一开始的最大的集合大小,然后进行合并,对于 \(w>0\) 的询问输出值为 \(1\) 的集合大小和大小为奇数的集合的大小的最大值即可。因为这里要对 \(n=300000\) 个数质因数分解,所以要用 \(O(V)-O(\log{V})\) 的分解方式(虽说卡卡常应该也不用)。
C Strange Shuffle
这里提供一种大常数 \(\Theta(3\sqrt{n})\) 的做法(主要原因是我太弱了,不会二分的做法)。首先发现一些这道题的性质:对于两个到 \(p\) 距离相同的点的和均保持为 \(2k\),这可以归纳证明,这里不再赘述。那么我们得到 \(p\) 位置的值一直为 \(k\),而显然 \(p+i>p-i\) 的。再考虑下一个性质:对于 \(i\) 次操作一定会形成 \(i\) 个大于 \(k\) 的数,这些数是从 \(p+1\) 开始连续的一段。这也是很显然的,可以把过程看为一个传递。还有一个性质做题时不需要就是 \(p+1,p+2...n,1,2...p-1\) 是不增的,还是考虑归纳,\(b_{i+1}=\lceil \frac{a_i}{2}\rceil + \lfloor \frac{a_{i+2}}{2}\rfloor\ge \lceil\frac{a_{i−1}{2}\rceil + \lfloor\frac{a_{i+1}{2}\rfloor=b_i\)。
然后回来看这题怎么做,直接我们发现如果询问 \(B\) 次那么就会得到一段长度为 \(B\) 的大于 \(k\) 的段,然后把序列分为 \(\frac{n}{B}\) 段,每段中必有一个大于 \(k\),我们想要找到一个大于 \(k\) 的点,然后花费 \(O(B)\) 往前找,那么总复杂度为 \(\Theta(2B+\frac{n}{B})\),\(B=\sqrt{\frac{n}{2}}\) 时最优。然而实测这样子可能会有问题,将 \(B\) 调成 \(\sqrt{n}\) 后才能过/kk(蒟蒻也不知道锅在哪了)
D Strange Housing
简单构造。如果图不连通显然无解。我们可以将这个图黑白染色,黑点对应选的点而白点对应不选的点。要满足任意两个黑点没有边相连,任意一个白点必然和一个黑点相连。图连通的时候考虑这么构造:随便找一个点将其染成黑色,然后对于其相连的点染成白色。然后对于这些被染色的白点将其相连的未被染色的点染成黑色,对于这些被染黑的点将其相邻的点都染成白色,然后对于这些白点再去做之前的步骤。考虑为什么这样是对的?首先显然所有点都会被染色,而因为一旦将一个点染成黑色就会把其周围的点都染成白色所以不可能有两个黑色的点相连。而对于每一个白色的点必然都是被一个黑点染成白色的所以也必然与一个黑点相连过,因为一个黑点被染色后其周围的点都会被染成白色所以这些点也就没有机会被染成黑色了,那这个黑点也就不会再被改成白色。所以这个黑点不会消失,这个白点也一定与这个黑点相连。
E Strange Permutation
一年之后过来更新 1e。可能第一次自己做出 3000+ 的题,但是也没有一次过,NOI 赛制可能就萎了。
类似子序列自动机啥的,记一个 \(f[i,j]\) 代表长度为 \(i\) 的排列至多有能量 \(j\) 啥的有多少方案。这个可以 dp。然后考虑求答案的时候就有一个 \(O(n)\) 的做法。考虑使得每次能量减一,这样就可以 \(O(poly(c))\) 做了。那么二分一段使得这一段不变,那么搞一个比不变小的部分的前缀和即可。分类讨论后发现还有一种情况,就是不完全不变,然后下一个位置比不变还大,这个也可以二分出位置,于是就做完了,复杂度 \(O(nc^{2}+qc\log c)\)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号