MySQL查询
开始下面的MySQL具体使用语法之前,先解决困扰我很久的一个问题:
通常说的MySQL,Oracle,SQL Server等等,都是数据库管理工具,只是用来管理数据的。在实际的开发过程中,数据通常是通过Web提供的数据驱动来连接数据库进行增删改查的。
以MySQL为例,在Mysql下的data文件夹下对应有创建的数据库和表数据,
所以,其实,数据其实是存储在不熟数据库的机器的硬盘中的。
.sql文件:
一: .sql结尾的文件可以直接导入到mysql客户端,执行该文件中的sql语句。
sql文件中的注释以--开头;
连接数据库:
mysql -uroot -p 回车然后输入密码
创建数据库:
==> create database 库名 charset=utf8;
使用数据库:
==> use 库名;
显示当前使用的数据库是哪个:
==> select databases();
创建数据表:
格式:
create table 表名(
字段名1 类型 约束 ,
字段名2 类型 约束 ,
......
字段名1 类型 约束
);
create table students(
id int unsigned primary key auto_increment not null,
name varchar(20) default '',
age tinyint unsigned default 0,
height decimal(5,2),
gender enum('男','女','中性','保密') default '保密',
cls_id int unsigned default 0,
is_delete bit default 0
);
create table classes(
id int unsigned auto_increment primary key not null,
name varchar(30) not null
);
以查看创建某表时的语句;
==>show create table 表名;
插入数据:(一次插入多条数据)
insert into students values
(0,'小明',18,180.00,2,1,0),
(0,'小月月',18,180.00,2,2,1),
(0,'彭于晏',29,185.00,1,1,0),
(0,'刘德华',59,175.00,1,2,1),
(0,'黄蓉',38,160.00,2,1,0),
(0,'凤姐',28,150.00,4,2,1),
(0,'王祖贤',18,172.00,2,1,1),
(0,'周杰伦',36,NULL,1,1,0),
(0,'程坤',27,181.00,1,2,0),
(0,'刘亦菲',25,166.00,2,2,1),
(0,'金星',33,162.00,3,3,1),
(0,'静香',12,180.00,2,4,0),
(0,'郭靖',12,170.00,1,4,0),
(0,'周杰',34,176.00,2,5,0);
往classes表中插入数据:
insert into classes values (0,"python_01期"),(0,"python_02期");
查询语句:
1: 普通查询
1.1:查询所有字段:
select * from students;
select * from classes;
1.2:查询指定字段:
select name,age from students;
1.3:给字段起别名
select name as 姓名,age as 年龄 from students;
1.4:表名.字段名
select students.name ,students.age from students;
select s.name ,s.age from students as s;
1.5:去重查询
select distinct name from students;
2: 条件查询(where;使用小括号提高运算优先级)
2.1:比较运算符查询
2.1.1: 大于(>) 查询
SELECT * FROM students where age >18;
2.1.2: 小于(<) 查询
SELECT * FROM students where age <18;
2.1.3: 大于等于(>=) 查询
2.1.4: 小于等于(<=) 查询
2.1.5: 不等于(!=) 查询
2.2:逻辑运算符查询
2.2.1: and
SELECT * FROM students where age>18 and age <28;
2.2.1: or
SELECT * FROM students where age>18 or height>=180;
2.2.1: not
不在 18岁以上的女性,select * from students where not(age>18 and gender='女');
年龄不是小于或者等于18,并且是女性,select * from students where (not age<=18) and gender ='女';
2.3:模糊查询(like[%代替一个或者多个字符; _代表一个字符], rlike[正则表达式]) : 效率比较低
2.3.1: like
查询姓名中以小开头的: select * from students where name like '小%';
查询姓名中包含小字的: select * from students where name like '%小%';
查询名字有2个字的学生的信息:select * from students where name like '__';
查询名字 至少有2个字的学生的信息:select * from students where name like '__%';
2.3.2: rlike
查询姓名中以周开头的人: select * from students where name rlike '^周.*';
查询姓名中以周开头并且以伦结尾的人: select * from students where name rlike '^周.*伦$';
2.4:范围查询
2.4.1: in(表示在一个非连续的范围)
查询年龄为,18,24,12的人: SQL1:select name,age from students where age=18 or age=24 or age=12; ==》不推荐
SQL2: select name,age from students where age in (18,24,12); 推荐
2.4.2: not in(表示不在一个非连续的范围)
查询年龄不为,18,24,12的人: select name,age from students where age not in (18,24,12);
2.4.3: between ....and ....(表示在一个连续的范围,包含两边的范围)
查询年龄为,18,24,12的人: select name,age from students where age between 18 and 28;
2.4.4: not between ....and ....(表示不在一个连续的范围,包含两边的范围)
查询年龄不为,18,24,12的人: select name,age from students where age not between 18 and 28;
2.5:空判断
a=None => a没有指向
a='' =>a指向一个字符串对象,不过字符串为空,是有空间的。
2.5.1: is null(判断为空)
查找身高字段为空的人的名字和年龄身高信息: select name,age,height from students where height is null;
2.5.2: not null(判断不为空)
查找身高字段为空的人的名字和年龄身高信息: select name,age,height from students where height is not null;
2.6:聚合函数
2.6.1: 计数(count)
select count(*) as 女性人数 from students where gender='女';
2.6.2: 最大值
select max(age) from students ;
2.6.3: 最小值
select min(age) from students ;
2.6.4: 求和
select sum(age) from students ;
2.6.5:平均值
select avg(age) from students ;
select sum(age)/count(*) from students ;
2.6.6: 四舍五入
round(原来的数字,x表示小数位数)
求年龄平均值,并且只保留两位小数: select round(sum(age)/count(*),2) from students ;
2.7:分组: group by
2.7.1:group by
求不同性别下的人数;
select gender,count(*) from students group by gender;
==> 此处的count(*) 是对分组后的每组数据进行统计计算,不是对原数据进行计算;如果多重分组,写为:group by A, B
==>此处的count(*) 可以换成前面的聚合函数;
2.7.2:group_concat
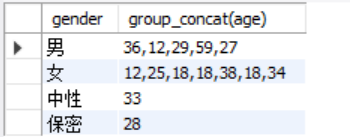
查询同种性别的姓名:select gender,group_concat(name) from students group by gender;
==> group_concat 中也可以输出字符串
select gender,group_concat(name,"_",age,"_",height) from students group by gender;
==> group_concat(列名) =》可以显示该分组下对应的该列的所有的值:
2.7.3:where:是对原表进行条件限制,放在group by的前面
求男性的人数:select gender,count(*) from students where gender='男' group by gender;
select gender,count(*) from students group by gender having gender='男';
2.7.4:having: 对分组的结果进行过滤,不能单独使用,使用时要放在group by的后面
查询平均年龄超过30岁的性别,以及名字,该性别组的平均年龄 :select gender,group_concat(name),avg(age) from students group by gender having avg(age)>30;
查询每种性别人数超过2的人员信息:select gender,group_concat(name) from students group by gender having count(*)>2;
2.8:排序: order by
升序排序: by asc, 默认可以省略asc
降序排序:by desc
2.8.1:orderby,单个字段
如果不指定order by 什么,sql语句默认是按照主键排序:
==> select * from students where (age between 18 and 34) and gender='男' order by age;
2.8.2:orderby,多个字段
order by 字段1 asc/desc, 字段2 asc/desc
==> 只有前面一个条件对应有相同的值,那么才会继续按照条件2排序,
==> 如果条件1对应的没有相同的值,那么条件2其实没有意义。
==> select * from students where (age between 18 and 34) and gender='女' order by height desc,id desc;
select gender,count(*) from students group by gender;
==> 此处的count(*) 是对分组后的每组数据进行统计计算,不是对元数据进行计算;
==》如果SQL语句中有group by, 那么select后面要显示的信息一定是对分组后的数据的处理。
======> order by 后面可以直接跟列的别名
2.9:分页: limit
==> 如果SQL语句中要使用limit,那么limit一定要放在SQL语句的最后。
2.9.1:limit 数字
限制查询两条结果:
==> select * from students where gender='女' limit 2;
2.9.2:limit 数字1[要开始显示数据位置的下标,整体下标是从0开始,具体要显示的开始数据的下标看具体的查询要求],数字2[要显示的数据的条数]
限制查询5条结果,从下标为2开始,即从第三个数开始:
==> select * from students where gender='女' limit 2,5;
规律:limit (第N页-1)*每页个数, 每页个数.
==> 但是不能直接将公式放入SQL语句,SQL语句不识别.
在SQL Server中可以使用top:查询前N条数据。
SELECT TOP N * FROM TABLE1
3:连接查询

select * from students inner join classes => 这个SQL语句语法上是没问题的,这个语句的意思是:
每显示students中的一条数据,都要把classes中的数据全都显示一遍。
3.1:inner join: 内连接(相关联的表里都有数据才会显示)
显示全部同学以及班级信息
==> select * from students inner join classes on students.cls_id=classes.id;
显示全部同学以及对应的班级名
==> 将班级名字放在第一列: select c.name, s.* from students as s inner join classes as c on s.cls_id=c.id;
==> select students.*,classes.name from students inner join classes on students.cls_id=classes.id;
给表取别名(查询结果和上个SQL语句是一模一样的)
==> select s.*,c.name from students as s inner join classes as c on s.cls_id=c.id;
查询 有能够对应班级的学生以及班级的信息,按照班级, 学生ID排序
==》select s.*,c.name from students as s inner join classes as c on s.cls_id=c.id order by c.name;
3.2:left join 左连接: 哪个表在左边,以哪个表为基准,左边的表在右边的表中找不到数据的,就显示null
显示全部同学,以及其对应的班级信息
==> select * from students as s left join classes as c on s.cls_id=c.id;
查询没有对应班级信息的学生:巧妙使用having(having是对查询到得结果集进行二次过滤)
==》 select * from students as s left join classes as c on s.cls_id=c.id having c.id is null;
也可以使用where: 从原表里做条件判断,用where
==》select * from students as s left join classes as c on s.cls_id=c.id where c.id is null;
4:自关联
比如表里存储:
省份 ID 省份名称 市ID,市区名称,以及区信息,等等
查询所有的省:
select * from table where 市ID is null;
查询山东省有多少市:
思路1: 可以先查询青岛市ID(select Id from table where 省份名称="山东"), 然后以此ID作为条件再查: select * from table where 市区ID = 前面查到的ID;
方法2:将一张表作为2张表来使用
select * from areas as province inner join areas as city on city.pid=province.aid having province.atit ="山东省"

方法3, 子查询:

5:子查询
查询身高最高的学生的信息:
select * from students where height = (select max(height) from students)
B站UP主的课程视频:https://www.bilibili.com/video/BV1zJ411M7TB/?spm_id_from=autoNext
删除数据:
delet from tablename where 条件;
更新数据:
update tablename set columnname=value;
插入数据:
insert into tablename set (列名1,列名2...) values(value1,value2...)
总结:
有时候一个查询要求可以用不同的SQL语句来实现,但是不同的是,不同的SQL语句的执行效率不同。
关联询的查询效率要高于子查询。
数据库设计:
遵循一些规则:
第一范式:强调列的原子性,即列不能再拆分成其他几列。
第二范式:必须要有主键(主键可以为多列),并且除主键外的字段都必须全部 直接 依赖于主键
。。。。。。等等
重点函数的用法:
===>limit:
limit n : 表示要显示出几条数据。
limit m,n: 表示从第m+1条数据开始查询,显示n条数据; =》默认其实从第1条开始查询,第一条数据下标是0;
===>distinct: 去重
distinct(列名)
日期函数的用法: 以下函数分别获取日期中的天,月,年
DAY()
MONTH()
YEAR()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号