字符编码
字符编码
1.什么是字符编码
是把字符集中的字符编码为指定集合中某一对象(例如:比特模式、自然数序列、8位组或者电脉冲),以便文本在计算机中存储和通过通信网络的传递
2.为什么有字符编码
因为计算机起源于美国,为了方便操控计算机,能够让计算机识别因为字符所以就有了字符编码,ASCII表在此也就诞生了
3.字符编码的发展
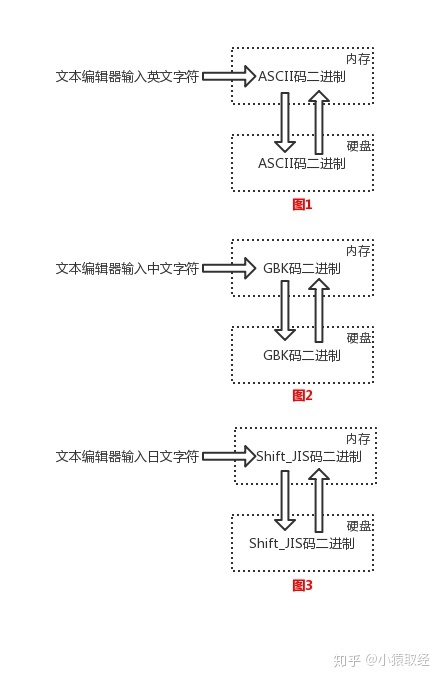
3.1 现代计算机起源于美国,所以最先考虑仅仅是让计算机识别英文字符,于是诞生了ASCII表,为了让计算机能够识别中文和英文,中国人定制了GBK,每个国家都各自的字符,为让计算机能够识别自己国家的字符外加英文字符,各个国家都制定了自己的字符编码表此时,美国人用的计算机里使用字符编码标准是ASCII、中国人用的计算机里使用字符编码标准是GBK、日本人用的计算机里使用字符编码标准是Shift_JIS,如下图所示。
3.2 为了能够识别所有的字符编码,我们定制了一个万国的字符编码unicode
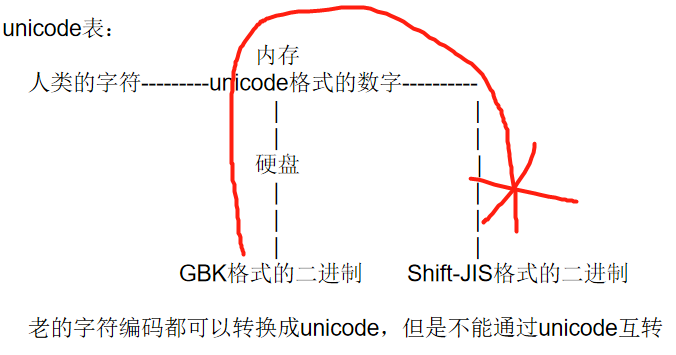
英文字符可以被ASCII识别
英文字符--->unciode格式的数字--->ASCII格式的数字
中文字符、英文字符可以被GBK识别
中文字符、英文字符--->unicode格式的数字--->gbk格式的数字
日文字符、英文字符可以被shift-JIS识别
日文字符、英文字符--->unicode格式的数字--->shift-JIS格式的数字
``
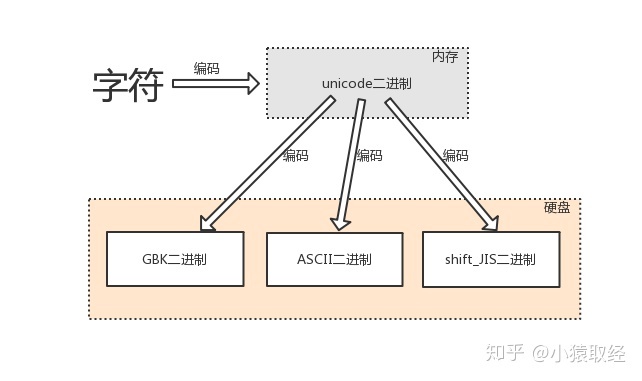
编码:由字符转换成内存中的unicode,以及由unicode转换成其他编码的过程,都称为编码encode
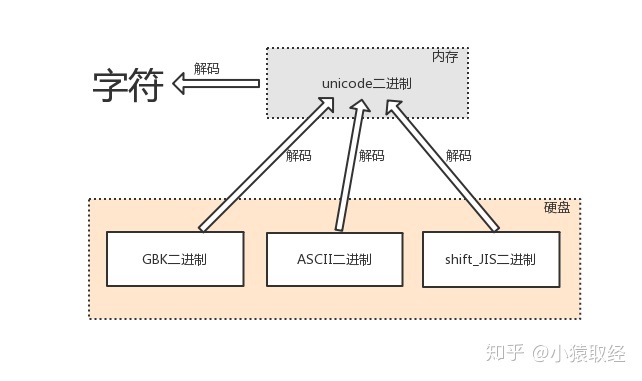
解码:由内存中的unicode转换成字符,以及由其他编码转换成unicode的过程,都称为解码decode
## 4.utf-8
是一种针对Unicode的可变长符编码,也是一种前缀码,又称万国码
但是为什么在内存中不用utf-8呢?只有Unicode编码才能运行其他国家硬盘中的代码,而UTF-8的代码无法进行该操作是因为多国字符编码遗留下来的原因
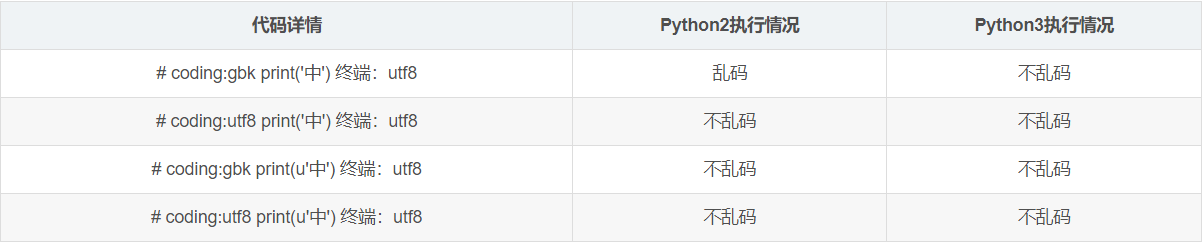
## 5 分析python 版本字符编码
python2和python3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号