Minimind-一个开源LLM项目的代码分析2:模型训练
这一章我们讲解模型训练涉及到的几个重要方法:pretrain,SFT,LoRA,DPO。项目作者提供了两种训练策略。如下图所示
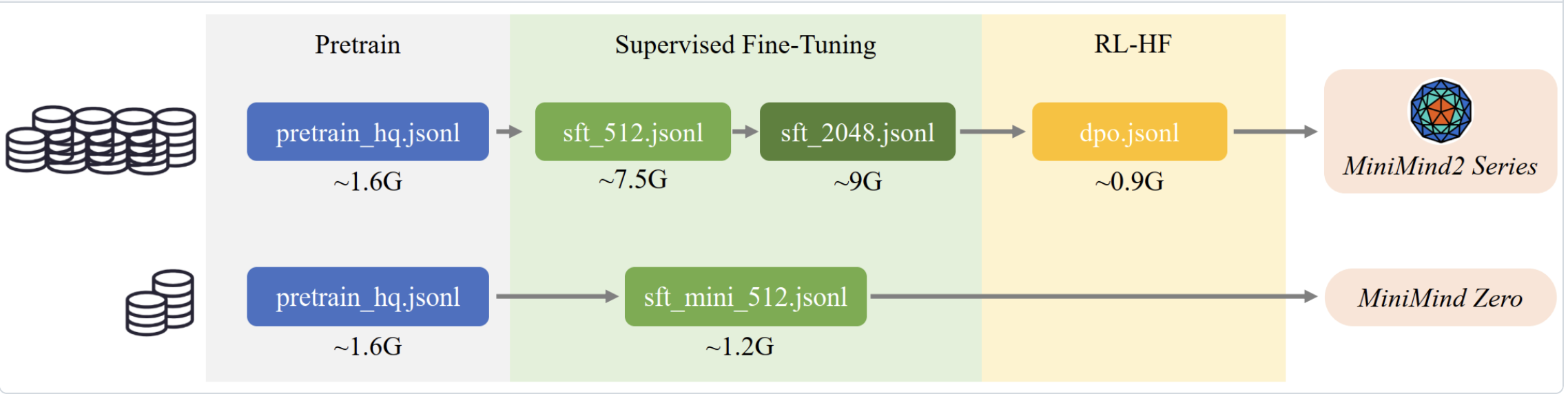
- 一种是完整的训练流程,先通过1.6G大小的数据集pretrain预训练一个基础模型,然后通过16.5G数据集SFT微调得到一个强力的基线模型,最后通过0.9G数据集做RL-HF进一步提升模型性能。
- 一个在预训练结束后,只采用一个迷你数据集监督微调,得到一个弱一点的模型。
因此,我们在本文介绍四个训练/微调环节: pretrain,SFT,DPO,LORA。
Tokenizer
tokenizer 是一个 无监督压缩模型,把 Unicode 字符串映射成整数序列(token id),目标是:在给定“词表大小”的约束下,让整个语料用尽量短的 token 序列重构回来。在Minimind已经存储在minimind/model/tokenizer.json中,使用时直接加载即可。MiniMind 故意把 vocab 压到 6400 左右,这样 26M 参数模型里,embedding 和 lm head 不会吃掉太多容量,主干 Transformer 还能有足够参数。
Pretrain
LLM首先要学习的并非直接与人交流,而是让网络参数中充满知识的墨水,“墨水” 理论上喝的越饱越好,产生大量的对世界的知识积累。 预训练就是让Model先埋头苦学大量基本的知识,例如从Wiki百科、新闻、书籍整理大规模的高质量训练数据。 这个过程是“无监督”的,即人类不需要在过程中做任何“有监督”的校正,而是由模型自己从大量文本中总结规律学习知识点。 模型此阶段目的只有一个:学会词语接龙。例如输入"秦始皇"四个字,它可以接龙"是中国的第一位皇帝"。在MiniMInd中,代码位于minimind/trainer/train_pretrain.py. MiniMind预训练使用的数据集为pretrain_hq.jsonl,这是一个1.55GB的文件,里面包含了非常多条数据,这里查看其中的第一条数据作为示例:
{'text': '<|im_start|>鉴别一组中文文章的风格和特点,例如官方、口语、文言等。需要提供样例文章才能准确鉴别不同的风格和特点。<|im_end|> <|im_start|>好的,现在帮我查一下今天的天气怎么样?今天的天气依据地区而异。请问你需要我帮你查询哪个地区的天气呢?<|im_end|> <|im_start|>打开闹钟功能,定一个明天早上七点的闹钟。好的,我已经帮您打开闹钟功能,闹钟将在明天早上七点准时响起。<|im_end|> <|im_start|>为以下场景写一句话描述:一个孤独的老人坐在公园长椅上看着远处。一位孤独的老人坐在公园长椅上凝视远方。<|im_end|> <|im_start|>非常感谢你的回答。请告诉我,这些数据是关于什么主题的?这些数据是关于不同年龄段的男女人口比例分布的。<|im_end|> <|im_start|>帮我想一个有趣的标题。这个挺有趣的:"如何成为一名成功的魔术师" 调皮的标题往往会吸引读者的注意力。<|im_end|> <|im_start|>回答一个问题,地球的半径是多少?地球的平均半径约为6371公里,这是地球自赤道到两极的距离的平均值。<|im_end|> <|im_start|>识别文本中的语气,并将其分类为喜悦、悲伤、惊异等。\n文本:“今天是我的生日!”这个文本的语气是喜悦。<|im_end|>'}
每一条数据都是一个字典格式,只包含一个键值对,key是固定的'text',value是用于预训练的“一段文本”,这是一个以 <|im_start|>和<|im_end|>为对话边界token的多轮指令-回答对话数据集片段。训练过程中,模型的目标是根据前面的文本预测下一个token,loss直接采用交叉熵,如下图所示。
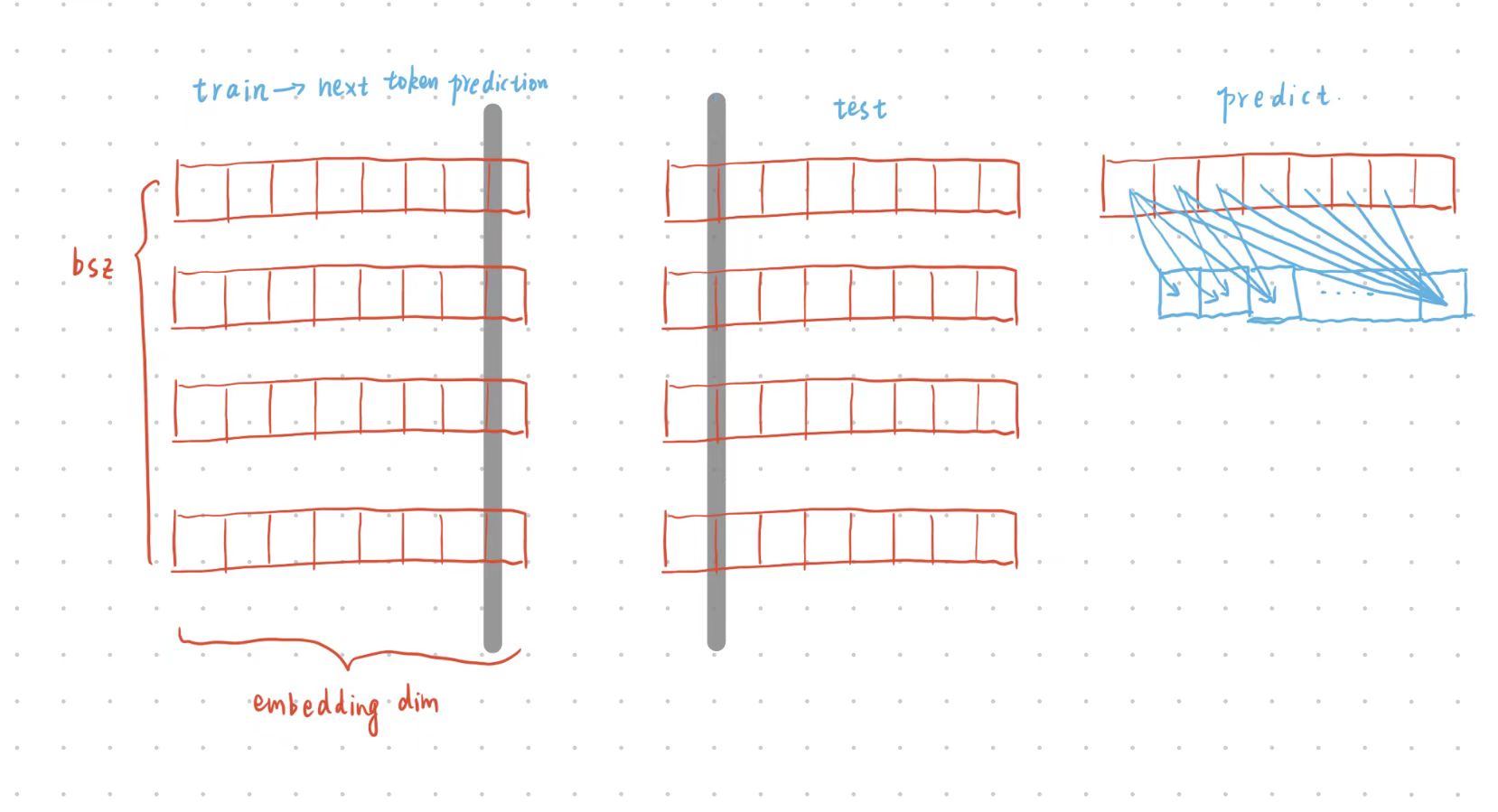
我们可以从pretrain数据集的构建更清楚的看到这一点:
import json
import torch
from torch.utils.data import Dataset
class PretrainDataset(Dataset):
def __init__(self, data_path, tokenizer, max_length=512):
super().__init__()
self.tokenizer = tokenizer # 分词器,用于将文本转为token ID
self.max_length = max_length # 每条样本的最大token长度
self.samples = self.load_data(data_path) # 加载数据
def load_data(self, path):
"""从文件中加载数据,每一行为一条JSON格式的样本"""
samples = []
with open(path, 'r', encoding='utf-8') as f:
for line_num, line in enumerate(f, 1):
# 读取每一行,解析成python dict
data = json.loads(line.strip()) #json->python dict
samples.append(data)
return samples
def __len__(self):
"""返回样本数量"""
return len(self.samples)
def __getitem__(self, index):
"""
返回第 index 个样本:
- X: 模型输入(input_ids[:-1]) # 前n-1个token
- Y: 目标输出(input_ids[1:]) # 后n-1个token
- loss_mask: 哪些token位置参与loss计算(去除padding部分)
"""
sample = self.samples[index]
# 将样本中的文本字段进行tokenize
encoding = self.tokenizer(
str(sample['text']), # 转为字符串(确保数据类型一致)
max_length=self.max_length, # 限制最大长度
padding='max_length', # 不足部分补pad
truncation=True, # 超出部分截断
return_tensors='pt' # 返回PyTorch tensor形式(包含batch维度)
)
# 获取input_ids张量,并去除batch维度(变成一维)
input_ids = encoding.input_ids.squeeze() # shape: [max_length]
# 计算loss_mask:pad的位置不参与loss
loss_mask = (input_ids != self.tokenizer.pad_token_id) # shape: [max_length],bool类型
# 语言模型是自回归的,使用前一个token预测下一个
X = torch.tensor(input_ids[:-1], dtype=torch.long) # 输入:[0, ..., n-2]
Y = torch.tensor(input_ids[1:], dtype=torch.long) # 目标:[1, ..., n-1]
loss_mask = torch.tensor(loss_mask[1:], dtype=torch.long) # loss_mask对齐目标Y,表示对非padding部分做交叉熵
return X, Y, loss_mask
在训练过程中,利用X做一次前向传播,得到预测的logits,然后和Y计算交叉熵损失,loss_mask用于屏蔽掉padding部分的loss贡献。这样模型就能学会根据前文预测下一个token,从而逐渐掌握语言的结构和知识。(minimind/trainer/train_pretrain.py)
def train_epoch(epoch, wandb):
"""单个 epoch 的训练过程。
依赖于外部的全局对象:model/optimizer/scaler/ctx/args/train_loader/iter_per_epoch/lm_config 等。
"""
loss_fct = nn.CrossEntropyLoss(reduction='none') # 不做 batch 内平均,后面用 mask 手动聚合
start_time = time.time()
for step, (X, Y, loss_mask) in enumerate(train_loader): # 数据集应返回 (input_ids, labels, loss_mask)
# 1) 搬到设备
X = X.to(args.device) # [B, L]
Y = Y.to(args.device) # [B, L]
loss_mask = loss_mask.to(args.device) # [B, L],为 0/1,屏蔽 padding 或不计 loss 的位置
# 2) 动态学习率(每 step 更新一次)
lr = get_lr(epoch * iter_per_epoch + step, # 当前全局步数(epoch 内 step + 之前的步数)
args.epochs * iter_per_epoch, # 总步数
args.learning_rate)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# 3) 前向计算(AMP 自动混合精度或 CPU nullcontext)
with ctx: # ctx = autocast() on CUDA,否则 nullcontext()
res = model(X) # 期望返回对象含 logits 以及额外 aux_loss(见模型定义)
# CE 需要 [N, vocab] vs [N],故把 [B, L, V] → [-1, V],labels [B, L] → [-1]
loss = loss_fct(
res.logits.view(-1, res.logits.size(-1)), # [B*L, vocab]
Y.view(-1) # [B*L]
).view(Y.size()) # reshape 回 [B, L]
# 应用 mask:只对有效 token 求平均
loss = (loss * loss_mask).sum() / loss_mask.sum()
# 加上模型的辅助损失(例如 MoE load balance 等),由模型内部给出
loss += res.aux_loss
# 梯度累计:把总 loss 均分到 accumulation_steps 次 backward 中
loss = loss / args.accumulation_steps
# 4) 反向传播(AMP 下用 GradScaler 以避免 fp16 溢出)
scaler.scale(loss).backward()
# 后续处理:梯度累积、梯度裁剪、优化器步进、学习率更新等
SFT
SFT 的全称是Supervised Fine-Tuning即:监督微调 “监督” = 有标签的数据(比如人工写好的问答、对话),“微调” = 在预训练模型的基础上,再次训练,让它学会特定任务。与pretrain不同,预训练使用大规模无监督文本(维基百科、网页、书籍……)格式通常就是一句话接一句话,模型目标是预测下一个 token
而SFT 数据 有明确的指令-回答(instruction-response)对,来源于人工标注或整理。我们以minimind使用的sft_mini_512为例,查看一条数据:
{
'conversations':
[
{
'role': 'user', 'content': '请告诉我在中国古代的“四大发明”是什么?'
},
{
'role': 'assistant', 'content': '中国古代的“四大发明”是指造纸术、印刷术、火药和指南针。这四项发明对世界文明的发展产生了深远的影响:\n\n1. **造纸术**:据史书记载,东汉时期的蔡伦改进了造纸工艺,使得纸张的生产更加便捷、成本更低,质量也更加优良。这一发明极大地促进了文化的传播和保存。\n\n2. **印刷术**:中国古代的印刷术最早可以追溯到唐代的雕版印刷,到了宋代发展出了活字印刷技术。印刷术的发明极大地促进了知识的传播,降低了书籍的成本,对教育和文化的发展起到了重要的推动作用。\n\n3. **火药**:火药最初是在唐代被发现的,最初可能用于医疗或炼金术。到了宋代,人们开始将火药用于军事目的,发明了各种火器。火药的发明改变了战争的面貌,对世界军事技术的发展产生了重大影响。\n\n4. **指南针**:指南针最初在中国被用于风水测量,后来逐渐发展成为航海导航的重要工具。这一发明极大地促进了海上航行技术的发展,对于新航路的开辟和世界地理大发现起到了关键作用。\n\n这四项发明不仅在中国历史上占有重要地位,而且对全世界的科技进步和文明发展都产生了深远的影响。'
}
]
}
可以看到,这是一段多轮对话数据,包含用户(user)和助手(assistant)两方的发言。SFT训练的目标是让模型学会根据用户的提问,生成合适的回答。因此数据集的组织形式,是按照问和答划分的。训练时,模型输入是用户的问题,目标输出是助手的回答。模型通过学习大量这样的问答对,逐渐掌握如何理解用户意图并生成有意义的回答。
import json
import torch
from torch.utils.data import Dataset
class SFTDataset(Dataset):
def __init__(self, jsonl_path, tokenizer, max_length=1024):
super().__init__()
self.tokenizer = tokenizer # 分词器
self.max_length = max_length # 最大输入长度(会进行截断或填充)
self.samples = self.load_data(jsonl_path) # 加载数据样本
self.bos_id = tokenizer('<|im_start|>assistant', add_special_tokens=False).input_ids# [1, 1078, 538, 501], [1]是<|im_start|>这个特殊token的id,[1078, 538, 501]是assistant的分词id
self.eos_id = tokenizer('<|im_end|>', add_special_tokens=False).input_ids# [2]
def __len__(self):
return len(self.samples) # 返回样本数量
def load_data(self, path):
"""从 jsonl 文件加载对话数据"""
samples = []
with open(path, 'r', encoding='utf-8') as f:
for line_num, line in enumerate(f, 1):
data = json.loads(line.strip()) # 每行为一个 JSON 对象
samples.append(data)
return samples
def _create_chat_prompt(self, conversations):
"""
将对话轮构造成符合 ChatML 格式的字符串:
每一轮用户/助手对话被标注为 'user' / 'assistant'
最终用 tokenizer 的 apply_chat_template 统一构造 prompt。
"""
messages = []
for i, turn in enumerate(conversations):
role = 'user' if i % 2 == 0 else 'assistant' # 偶数轮为用户,奇数轮为助手
messages.append({"role": role, "content": turn['content']})
# 返回字符串形式的 prompt,而非直接 tokenize
return self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=False
)
def _generate_loss_mask(self, input_ids):
"""
构建损失掩码,只有 assistant 的回答部分才参与 loss 计算。
找出每一段 assistant 的响应,在其 <|im_start|>assistant 和 <|im_end|> 之间设置 loss_mask 为 1。
"""
loss_mask = [0] * len(input_ids)
i = 0
while i < len(input_ids):
# 找 assistant 开头标志
if input_ids[i:i + len(self.bos_id)] == self.bos_id:
start = i + len(self.bos_id) # 答案起点
end = start
while end < len(input_ids):
# 查找 assistant 的回答终止符 <|im_end|>
if input_ids[end:end + len(self.eos_id)] == self.eos_id:
break
end += 1
# 为 assistant 回答部分(从 start + 1 到 end 之间)设置 loss mask
for j in range(start + 1, min(end + len(self.eos_id) + 1, self.max_length)):
loss_mask[j] = 1
# 跳过到下一个 segment
i = end + len(self.eos_id) if end < len(input_ids) else len(input_ids)
else:
i += 1
return loss_mask
def __getitem__(self, index):
sample = self.samples[index]
# 构建 ChatML 格式 prompt(字符串)
prompt = self._create_chat_prompt(sample['conversations'])
# 分词并截断,确保长度 <= max_length
input_ids = self.tokenizer(prompt).input_ids[:self.max_length]
# 右侧填充 pad_token 直到 max_length 长度
input_ids += [self.tokenizer.pad_token_id] * (self.max_length - len(input_ids))
# 生成动态 loss mask,仅对 assistant 响应位置计算 loss
loss_mask = self._generate_loss_mask(input_ids)
# 构建训练样本:
# 模型输入为前 n-1 个 token,预测目标为第 2 到第 n 个 token
X = torch.tensor(input_ids[:-1], dtype=torch.long) # 输入序列
Y = torch.tensor(input_ids[1:], dtype=torch.long) # 目标标签(shifted)
loss_mask = torch.tensor(loss_mask[1:], dtype=torch.long) # 对齐 Y 的位置(从第一个预测 token 开始)
return X, Y, loss_mask
即:模型输入是前n-1个token,目标输出是后n-1个token。loss_mask用于屏蔽掉不需要计算loss的位置(用户提问部分+padding部分)。训练过程中,模型通过学习大量这样的问答对,逐渐掌握如何理解用户意图并生成有意义的回答。(minimind/trainer/train_sft.py)
DPO
DPO的目标是让训练后模型更偏好人类认为更好的答案(chosen),而不是差的答案(rejected),并且这种偏好是在对比参考模型(refrence model)的基础上学来的。这里的参考模型,一般指的是微调前的模型,比如做了预训练和SFT之后的模型。 DPO旨在以一种更简单、更稳定的方式替代传统RLHF中复杂的奖励建模过程。它的核心在于:使用一个直接可微的损失函数,来优化模型对人类偏好的响应倾向,而无需训练单独的奖励模型或使用复杂的强化学习方法(如PPO)。 具体来说,DPO在一对偏好样本上进行优化:它增加人类偏好响应中token的对数概率,同时减少非偏好响应中的对数概率,从而促使模型产生更符合人类意图的输出。
从数学角度看,这一过程相当于为模型引入了一个隐式奖励函数,该函数通过log-ratio的差值衡量当前策略相对于参考策略对人类偏好的一致程度,并直接用于梯度优化。
设:
- \(\pi\) 是当前模型(policy model)
- \(\pi_\text{ref}\) 是参考模型(reference model)
- \(x\) 是输入 prompt
- \(y^+\) 是人类偏好的回答(
chosen) - \(y^-\) 是次优回答(
rejected) - \(\beta\) 是温度超参(调节梯度幅度)
DPO loss 如下:
其中 \(\sigma\) 是 sigmoid 函数。
在上述公式的log差值项中,前一个表示模型对于人类偏好chosen回复\(y^+\)的对数概率,后一个表示模型对于rejected回复\(y^-\)的对数概率,DPO loss的目标是最大化两者的差值,也就是鼓励模型\(\pi\)相较于\(\pi_\text{ref}\)更加偏好\(y^+\)而非\(y^-\)。其中除以\(\pi_\text{ref}\)的作用是作为一个正则化因子,确保训练后的模型过度偏离原始模型。 在MiniMind的代码实现中,根据对数运算的性质,调换了DPO loss中的对数项顺序,如下:
lora
原理
lora是一个很经典的方法了,不再赘述。翻译一下原文的摘要:
自然语言处理中的一个重要范式是:先在大规模的通用领域数据上进行预训练,再将模型适配到特定任务或领域。随着预训练模型规模的不断增大,对所有参数进行完整微调(full fine-tuning)变得越来越不可行。以 GPT-3 175B 为例——如果为每个下游任务都部署一份拥有 1750 亿参数的独立微调模型,开销是难以承受的。
我们提出了一种低秩适配方法(Low-Rank Adaptation, LoRA)。该方法冻结预训练模型的权重,并在 Transformer 架构的每一层中注入可训练的低秩分解矩阵,从而显著减少下游任务所需的可训练参数量。与使用 Adam 对 GPT-3 175B 进行完整微调相比,LoRA 能将可训练参数数量减少至原来的万分之一,同时将显存需求降低 3 倍。
尽管可训练参数更少、训练吞吐量更高,LoRA 在 RoBERTa、DeBERTa、GPT-2 和 GPT-3 等模型上的效果与完整微调持平甚至更优;与传统 adapter 方法不同,LoRA 在推理阶段也不会带来额外的延迟。我们还对语言模型适配过程中的秩缺陷问题进行了实证研究,为 LoRA 的有效性提供了进一步解释。最后,我们发布了一个便于将 LoRA 集成到 PyTorch 模型的工具包,并在 GitHub([ https://github.com/microsoft/LoRA )提供了我们的实现代码和]( https://github.com/microsoft/LoRA )提供了我们的实现代码和) RoBERTa、DeBERTa、GPT-2 的模型检查点。
以往的一些结果(比如《Exploring Aniversal Intrinsic Task Subspace via Prompt Tuning》显示, 尽管预训练模型的参数量很大,但每个下游任务对应的本征维度 (Intrinsic Dimension)并不大,换句话说,理论上我们可以微调非常小的参数量,就能在下游任务取得不错的效果。
LoRA借鉴了上述结果,提出对于预训练的参数矩阵\(W_0\in\mathbb{R}^{n\times m}\),我们不去直接微调\(\color{red}{W_0}\),而是对增量做低秩分解假设(认为参数更新矩阵只需要“少数几个独立方向”就能表达):
其中\(\color{blue}{A,B}\)之一用全零初始化,\(\color{blue}{W_0}\)固定不变,优化器只优化\(\color{blue}{A,B}\)。由于本征维度很小的结论,所以\(\color{blue}{r}\) 我们可以取得很小,常见的是\(\color{red}{r=8}\),极端情况下我们甚至可以取1。所以说,LoRA是一种参数高效的微调方法,至少被优化的参数量大大降低了。
../model/model_lora.py
具体的,为lora实现一个类,该怎么训练就怎么训练即可
import torch
from torch import optim, nn
# ==========================
# 定义 LoRA 网络结构
# ==========================
class LoRA(nn.Module):
def __init__(self, in_features, out_features, rank):
super().__init__()
self.rank = rank # LoRA 的秩(r),控制低秩分解的维度大小
# 低秩分解的两个矩阵 A 和 B
# A: [in_features → rank] 降维
# B: [rank → out_features] 升维
# 整体 ΔW = BA
self.A = nn.Linear(in_features, rank, bias=False)
self.B = nn.Linear(rank, out_features, bias=False)
# 初始化策略:
# A 用小的随机数初始化(正态分布),保证一开始有微小扰动
self.A.weight.data.normal_(mean=0.0, std=0.02)
# B 初始化为全 0,保证训练开始时 LoRA 分支不改变原始模型输出
self.B.weight.data.zero_()
def forward(self, x):
# 前向传播:先降维再升维
# 相当于 ΔW x
return self.B(self.A(x))
# ==========================
# 给现有模型注入 LoRA 模块
# ==========================
def apply_lora(model, rank=8):
# 遍历模型里的所有子模块
for name, module in model.named_modules():
# 这里只在 Linear 层上加 LoRA
# 限制条件:权重是方阵(out_features == in_features)
if isinstance(module, nn.Linear) and module.weight.shape[0] == module.weight.shape[1]:
# 创建一个 LoRA 分支,维度与原始 Linear 一致
lora = LoRA(module.weight.shape[0], module.weight.shape[1], rank=rank).to(model.device)
# 用 setattr 动态给 Linear 层加一个属性:.lora
# 这样以后可以通过 module.lora 调用这个 LoRA 分支
setattr(module, "lora", lora)
# 保存原始的 forward 函数,避免丢失
original_forward = module.forward
# 定义新的 forward:原始输出 + LoRA 分支的输出
# 等价于 y = W x + ΔW x
def forward_with_lora(x, layer1=original_forward, layer2=lora):
return layer1(x) + layer2(x)
# 替换原始 forward
module.forward = forward_with_lora

 浙公网安备 33010602011771号
浙公网安备 33010602011771号