Python基础篇 (7)---字典元组集合的内置方法
本章内容
• 字典的内置方法
• 元组的内置方法
• 集合的内置方法
• 补充:垃圾回收机制
字典的内置方法
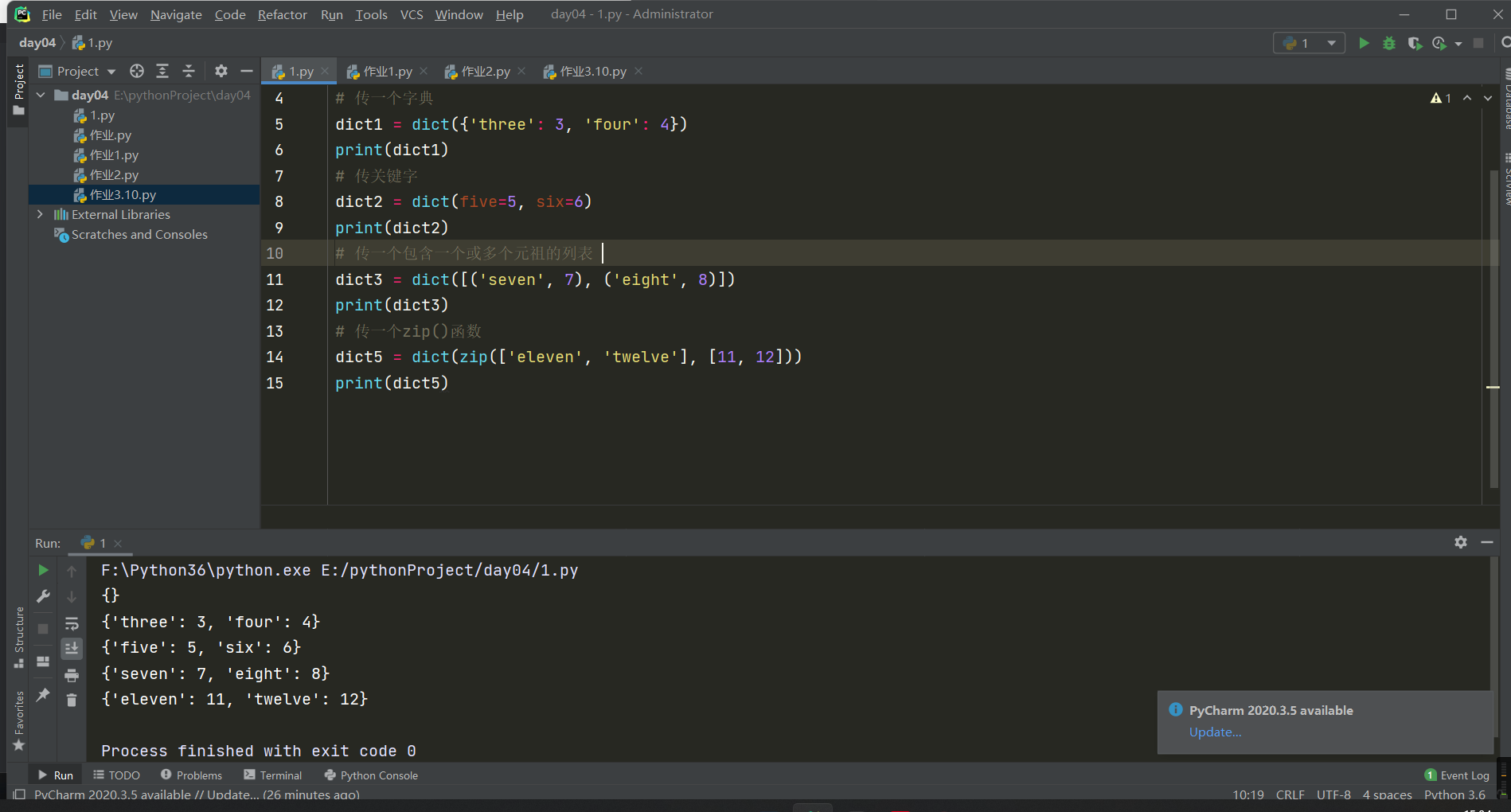
1.类型转换
# dict()用于创建一个字典
dict0 = dict() # 传一个空字典
print(dict0)
# 传一个字典
dict1 = dict({'three': 3, 'four': 4})
print(dict1)
# 传关键字
dict2 = dict(five=5, six=6)
print(dict2)
# 传一个包含一个或多个元祖的列表
dict3 = dict([('seven', 7), ('eight', 8)])
print(dict3)
# 传一个zip()函数
dict5 = dict(zip(['eleven', 'twelve'], [11, 12]))
print('dict5)
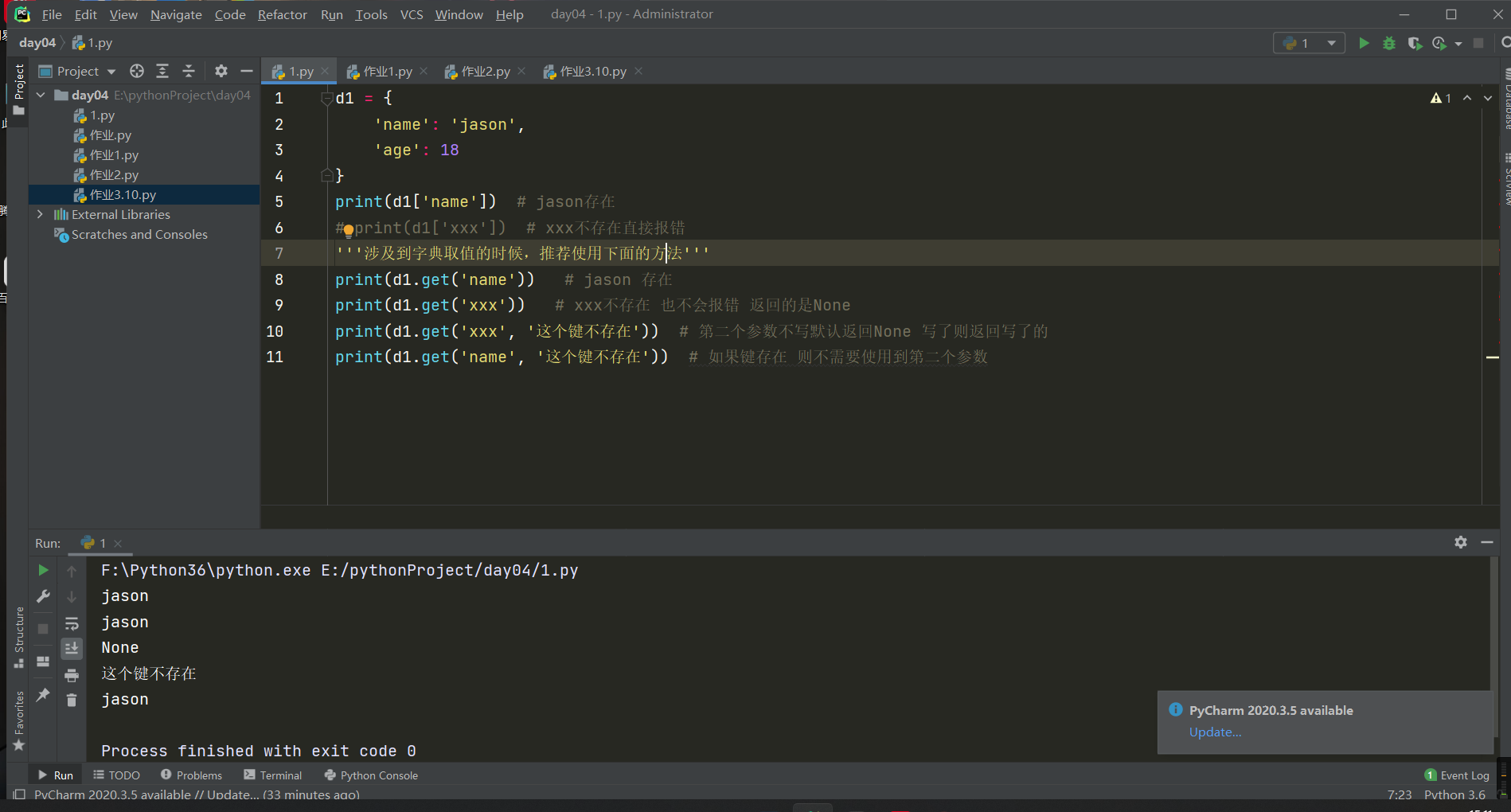
2.按key取值
d1 = {
'name': 'jason',
'age': 18
}
print(d1['name']) # jason存在
print(d1['xxx']) # xxx不存在直接报错
'''涉及到字典取值的时候,推荐使用下面的方法'''
print(d1.get('name')) # jason 存在
print(d1.get('xxx')) # xxx不存在 也不会报错 返回的是None
print(d1.get('xxx', '这个键不存在')) # 第二个参数不写默认返回None 写了则返回写了的
print(d1.get('name', '这个键不存在')) # 如果键存在 则不需要使用到第二个参数
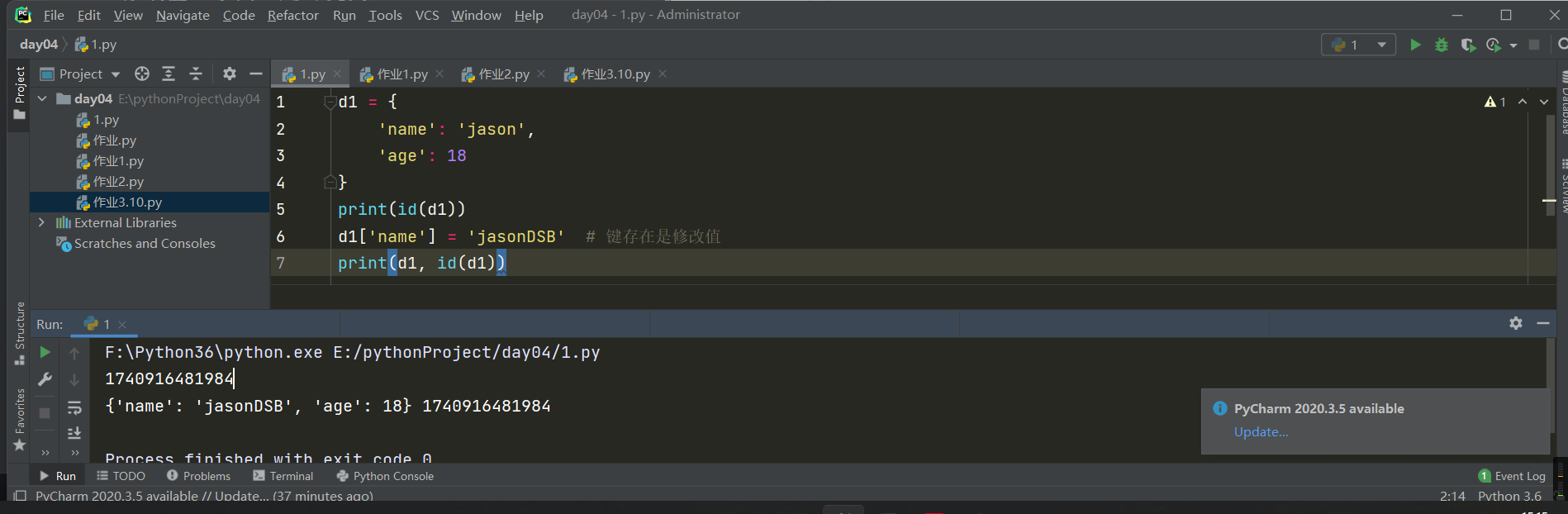
3.修改值,字典是可变类型
d1 = {
'name': 'jason',
'age': 18
}
print(id(d1)) # 1740916481984
d1['name'] = 'jasonDSB' # 键存在是修改值
print(d1, id(d1)) # {'name': 'jasonDSB', 'age': 18} 1740916481984
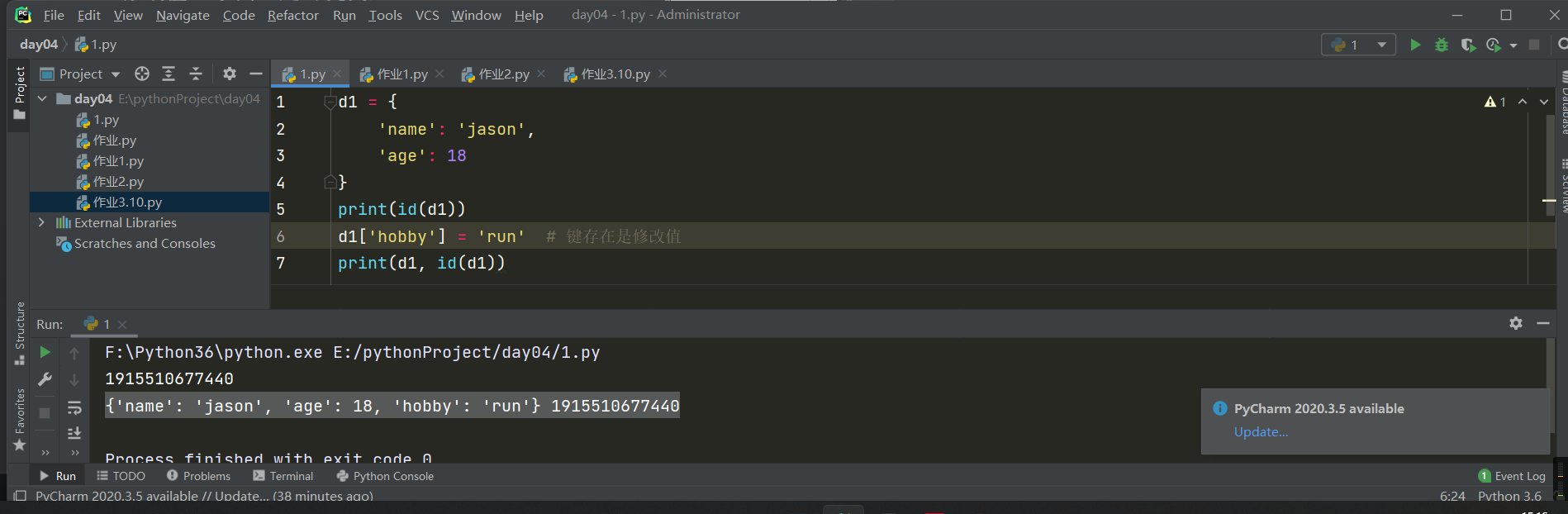
4.增加键值
d1 = {
'name': 'jason',
'age': 18
}
print(id(d1)) # 1915510677440
d1['hobby'] = 'run' # 键不存在是 增加值
print(d1, id(d1)) # {'name': 'jason', 'age': 18, 'hobby': 'run'} 1915510677440
5.len---统计字典中键值对的个数
d1 = {
'name': 'jason',
'age': 18
}
print(len(d1)) # 2
6.成员运算 只能判断key
d1 = {
'name': 'jason',
'age': 18
}
print('jason' in d1) # False
print('name' in d1) # True
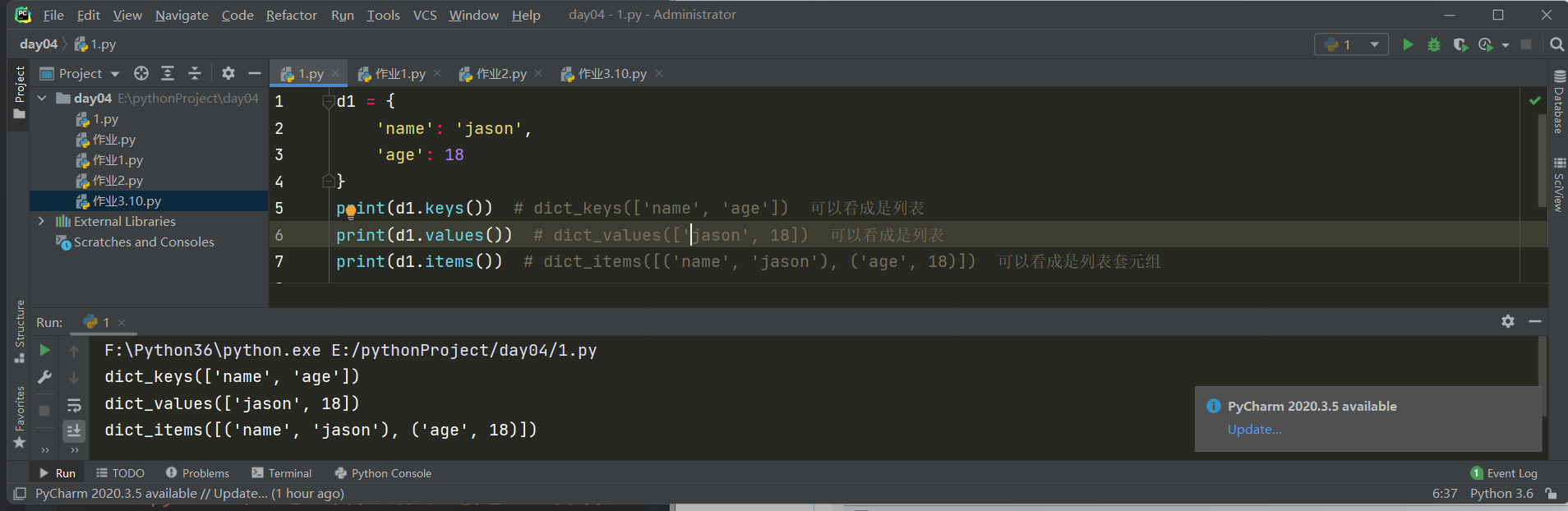
7.keys,values,items---获取所有键,所有值,所有键值对
d1 = {
'name': 'jason',
'age': 18
}
print(d1.keys()) # dict_keys(['name', 'age']) 可以看成是列表
print(d1.values()) # dict_values(['jason', 18]) 可以看成是列表
print(d1.items()) # dict_items([('name', 'jason'), ('age', 18)]) 可以看成是列表套元组
************需要了解**************
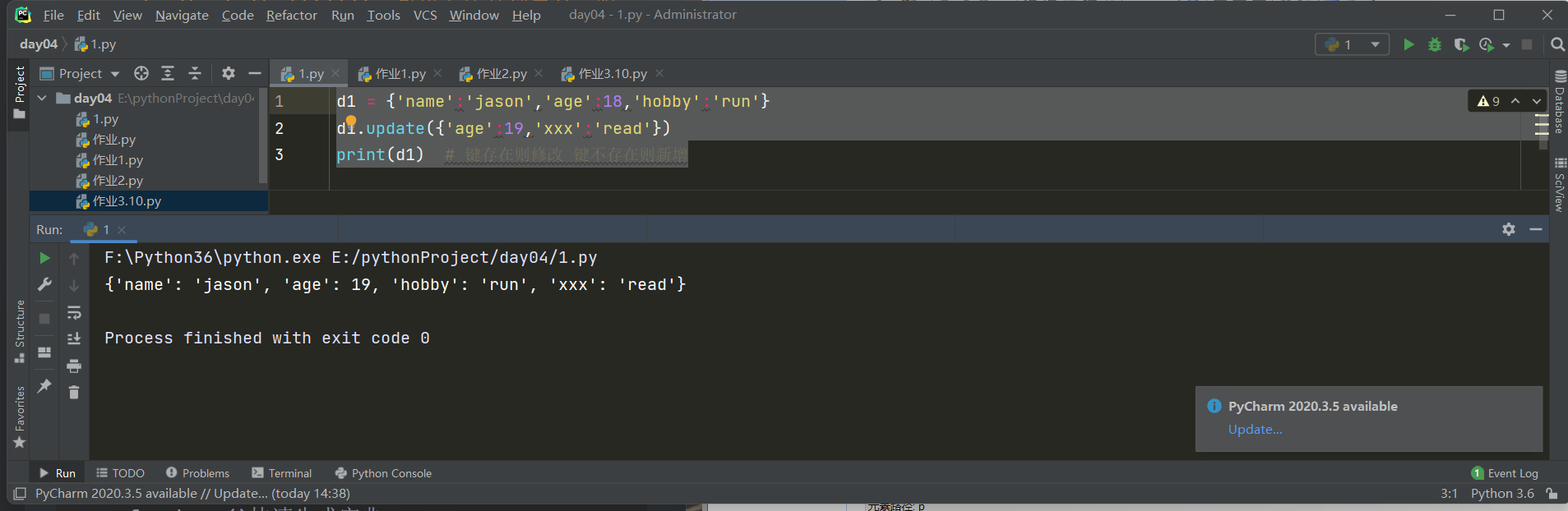
1.update更新字典
d1 = {'name':'jason','age':18,'hobby':'run'}
d1.update({'age':19,'xxx':'read'})
print(d1) # 键存在则修改 键不存在则新增
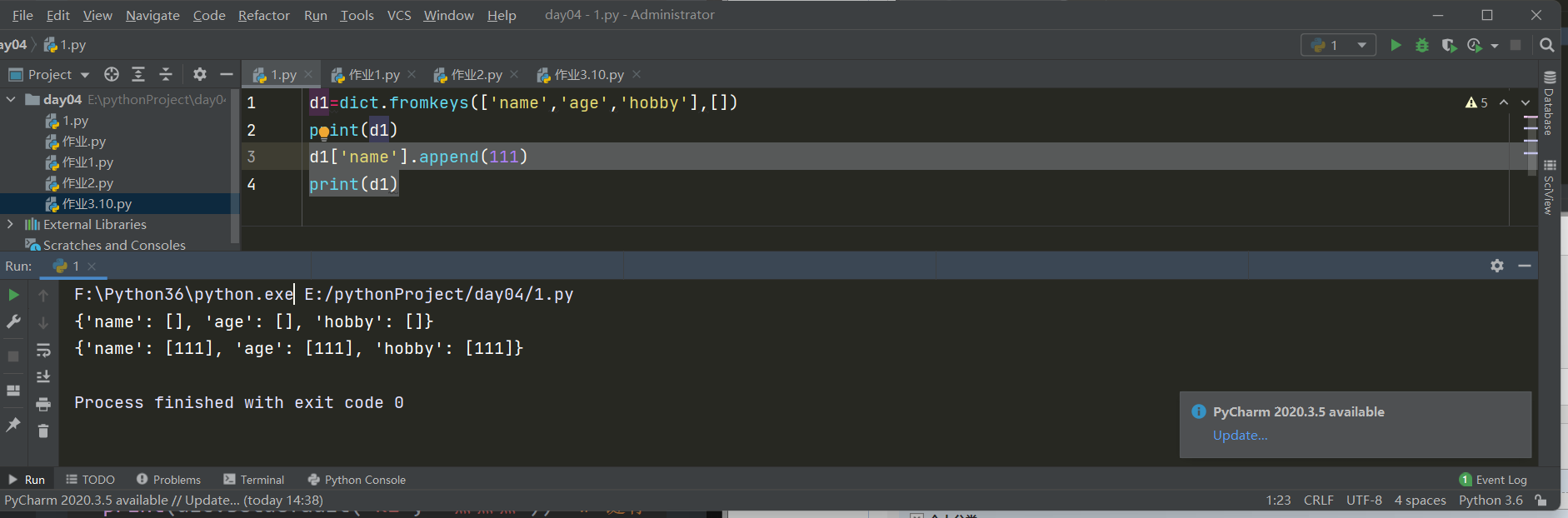
2.fromkeys()快速生成字典
d1=dict.fromkeys(['name','age','hobby'],[])
print(d1) # {'name': [], 'age': [], 'hobby': []}
'''笔试题'''
d1['name'].append(111) # 三个键指向的是同一个列表
print(d1) # {'name': [111], 'age': [111], 'hobby': [111]}
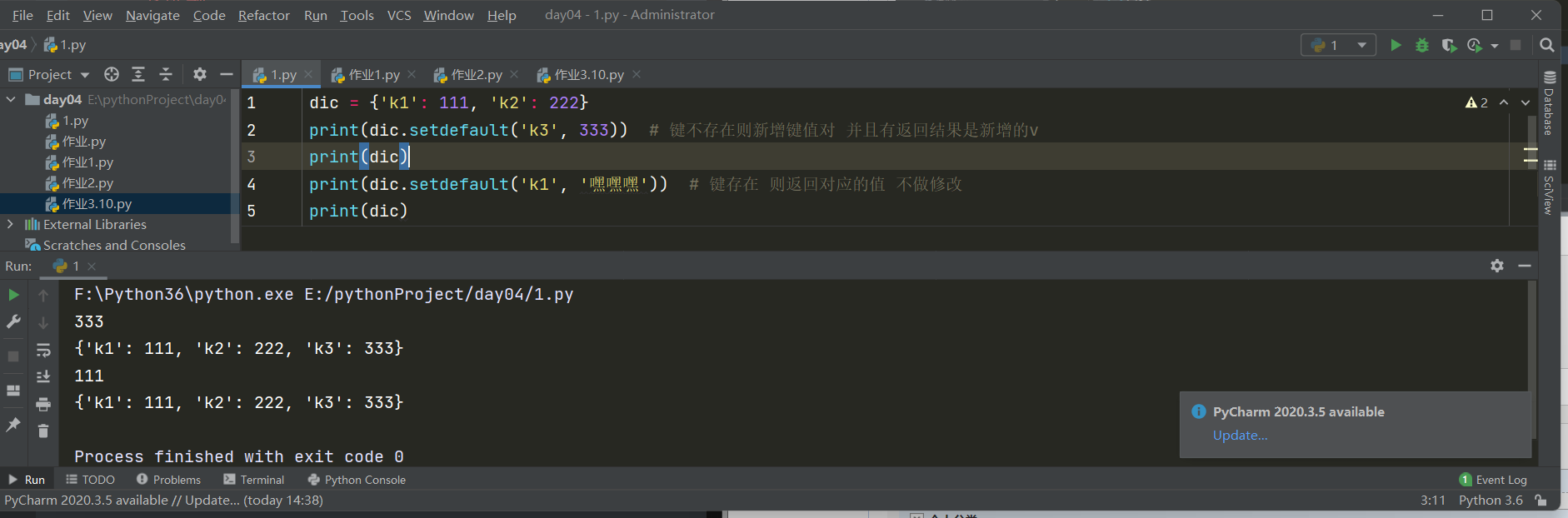
3.setdefault()
dic = {'k1': 111, 'k2': 222}
print(dic.setdefault('k3', 333)) # 键不存在则新增键值对 并且有返回结果是新增的v
print(dic)
print(dic.setdefault('k1', '嘿嘿嘿')) # 键存在 则返回对应的值 不做修改
print(dic)
1.类型转换
支持for循环的数据类型都可以转成元组 # 整型,浮点型,布尔型不能转成元组 print(tuple(11)) # 报错 print(tuple(11.11)) # 报错 print(tuple(True)) # 报错 # 字符串,列表,字典,集合可以转成元组 print(tuple('jason')) print(tuple([11,22,33,44])) print(tuple({'name':'jason'})) print(tuple({11,22,33,44}))
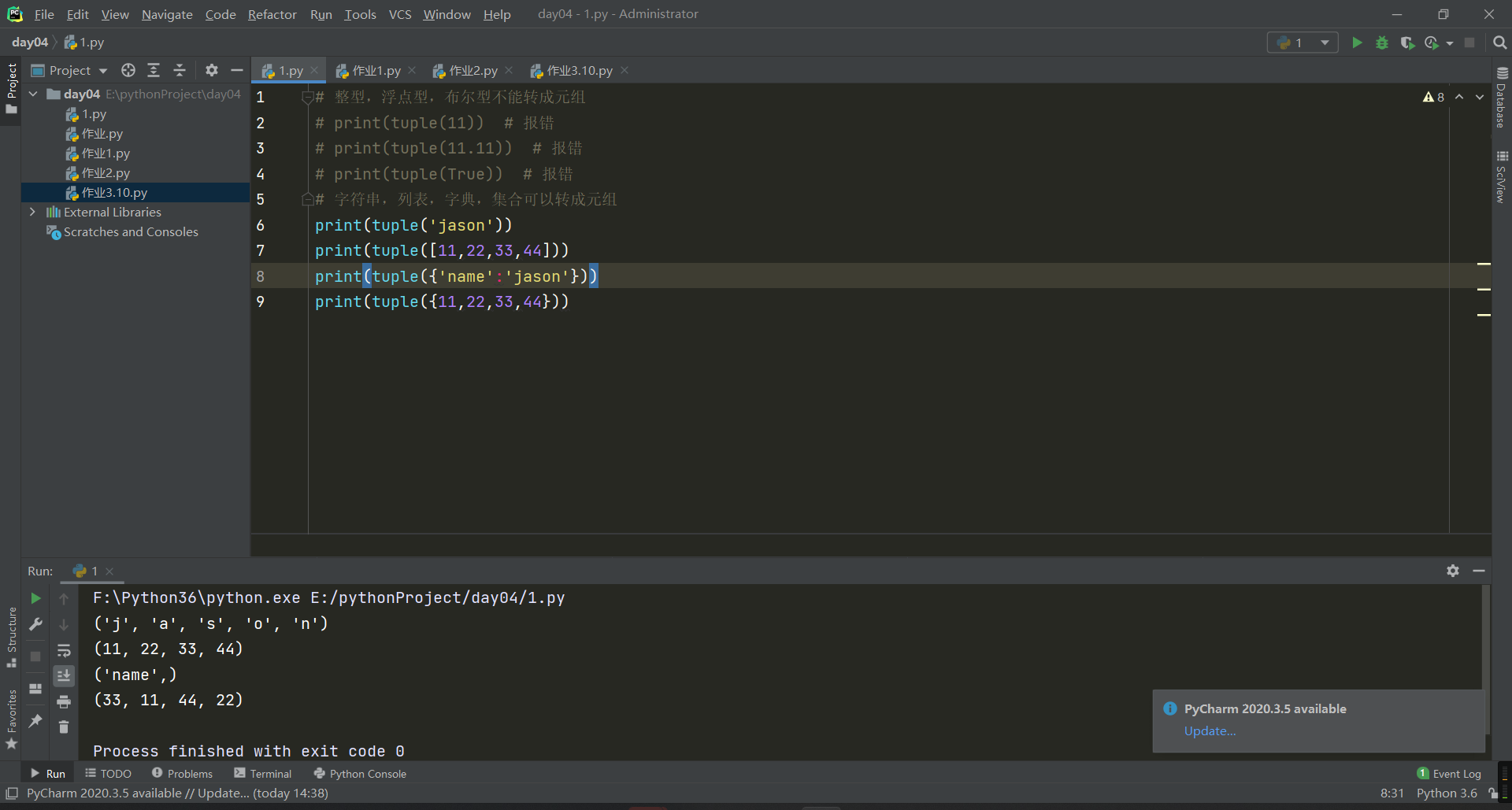
2.元组的特性
"""当元组内只有一个元素的时候 一定要在元素的后面加上逗号"""
t1 = (11)
print(type(t1)) # <class 'int'>
t2 = (11,)
print(type(t2)) # <class 'tuple'>
"""
一般情况下 我们会习惯性的将所有可以存储多个数据的类型的数据
如果内部只有一个元素 也会加逗号
(1,)
[1,]
{1,}
{'name':'jason',}
"""
3.内置方法
t1 = (11, 22, 33, 44, 55, 66)
1.索引取值
print(t1[0]) # 11
print(t1[-1]) # 66
2.切片操作
print(t1[1:4]) # (22, 33, 44)
print(t1[-1:-4:-1]) # (66, 55, 44)
print(t1[-4:-1]) # (33, 44, 55)
3.间隔
print(t1[1:4:2]) # (22, 44)
4.统计元组内元素的个数
print(len(t1)) # 6
5.成员运算
print(11 in t1) # True
6.统计某个元素出现的次数
print(t1.count(22)) # 1
7.元组内元素不能"修改": 元组内各个索引值指向的内存地址不能修改
t1[0] = 111 # 报错
集合的内置方法
1.类型转换
"""集合内元素只能是不可变类型"""
# 整型,浮点型,布尔型是不能转成集合
print(set(11)) # 报错
print(set(11.11)) # 报错
print(set(True)) # 报错
# 列表,字典,字符串,元组是可以转成集合的
print(set('jason'))
print(set([11,22,33,44]))
print(set({'name':'jason'}))
print(set((11,22,33)))
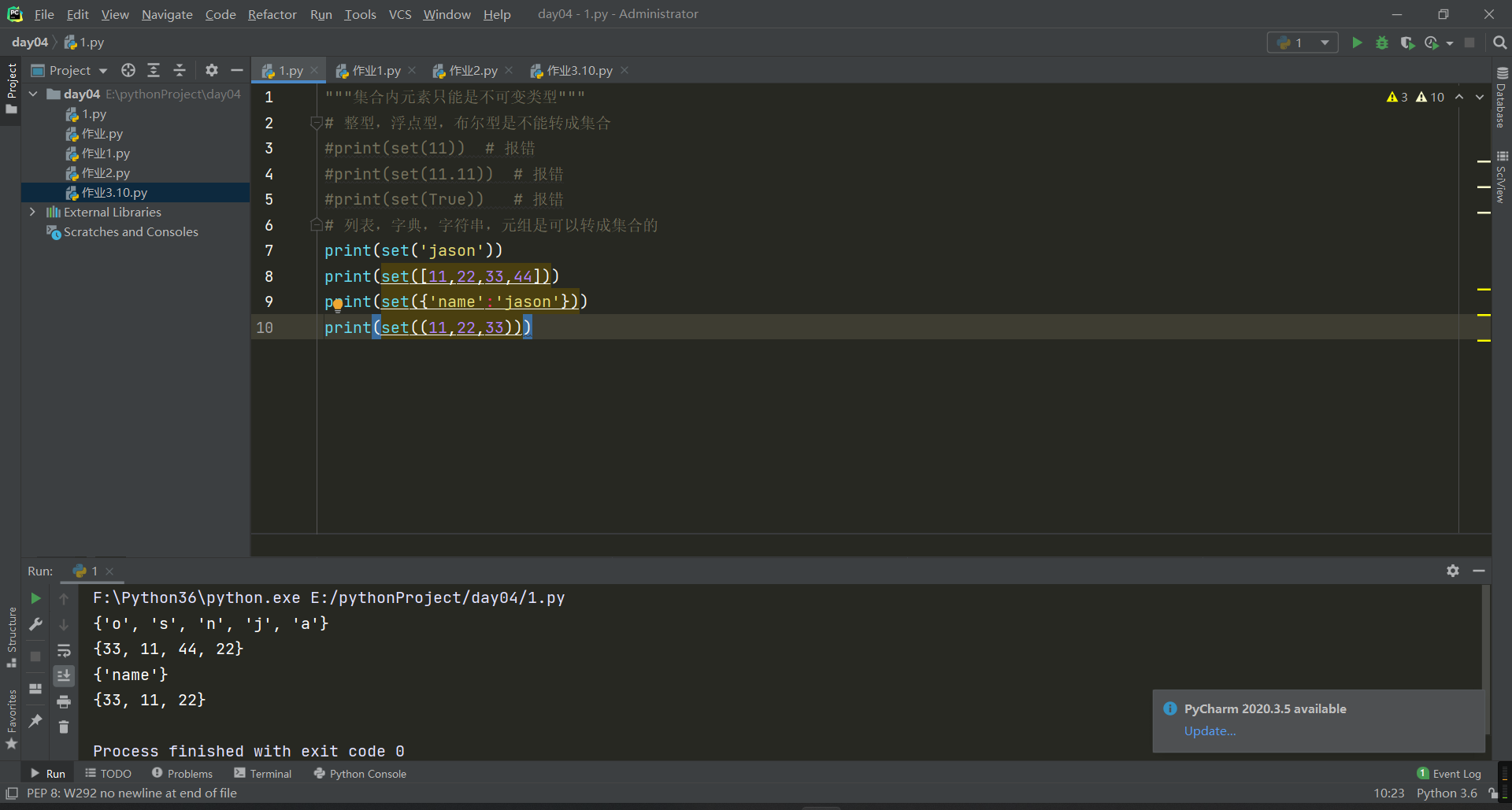
2.两大功能---去重和关系运算
1.去重
'''
集合内不能出现重复的元素(自带去重特性)
如果出现了 会被集合自动去重
'''
s1 = {1,1,1,1,1,1,2,2,2,2,2,1,2,3,2,2,1,2,3,2,3,4,3,2,3}
print(s1) # {1, 2, 3, 4}
l = ['a', 'b', 1, 'a', 'a']print(l) # ['a', 1, 'b']
2.关系运算
s1 = {'run','read','eat','sleep','drink'} # 小王的爱好
s2 = {'run','read','basketball','football'} # 小李的爱好
# 1. 求2个人的共同爱好
print(s1 & s2) # {'read', 'run'}
# 2. 求小王的单独爱好
print(s1 - s2) # {'drink', 'sleep', 'eat'}
# 3. 求2个人的所有爱好
print(s1 | s2) # {'read', 'sleep', 'basketball', 'football', 'eat', 'run', 'drink'}
# 4. 求2个人的各自爱好
print(s1 ^ s2) #{'sleep', 'basketball', 'drink', 'football', 'eat'}
垃圾回收机制
引用计数---内存中数据身上绑定的变量名的个数。
# 如:
age=18 #变量值18被变量名age绑定了,所以变量值18的计数+1
m=age # 此时变量名age的内存地址(变量名18)被m指向了,所以变量值18的计数又+1
# 如果
del m # 解除了m和18的绑定,变量值18的计数-1
del age # # 解除了age和18的绑定,变量值18的计数-1 就等于0了
# 值18的引用计数一旦变为0,其占用的内存地址就应该被解释器的垃圾回收机制回收
'''
python会将引用计数为0的数据清除
'''
标记清除
'''
做法是当应用程序可用的内存空间被耗尽的时,
就会停止整个程序,然后进行两项工作,
第一项则是检查引用计数并给计数为0的数据打上标记,
第二项则是清除引用计数为0的值
'''
分代回收
'''
根据值存在的时间长短 将值划分为三个等级
'''
现在有5个值进入等级1中,假设等级1检测机制每隔5秒检查1次
----检查多次后 只有3个值的引用计数不为0----
活下来的3个值进入的等级2中,假设等级二的检查机制为1min一次
----检查多次后,只有1个值的引用计数还不为0-----
最后活下来的值进入了等级3,等级3的检查机制为5min一次
----检查多次后最后一个值的引用计数可能还大于0或者等于0被清理----
'''
回收依然是使用引用计数作为回收的依据
'''

 浙公网安备 33010602011771号
浙公网安备 33010602011771号