真正“搞”懂HTTP协议03之时间穿梭
上一篇我们简单的介绍了一下DoD模型和OSI模型,还着重的讲解了TCP的三次握手和四次挥手,让我们在空间层面,稍稍宏观的了解了HTTP所依赖的底层模型,那么这一篇,我们来追溯一下HTTP的历史,看一看HTTP在历史上经历了哪些发展和过程,才让这个协议一直经久不衰。
最开始,在20世纪60年代,也就是1950年到1960年之间,那时候我爹还没出生呢……但是美国国防部高等研究计划署(ARPA)建立了ARPA网,他有四个分布在各地的节点,被认为是互联网的始祖。信息时代的号角也在此刻吹响,人们即将迎来快速发展的网络时代。
在70年代,我爹五六岁的时候,基于对 ARPA 网的实践和思考,研究人员发明出了著名的 TCP/IP 协议。由于具有良好的分层结构和稳定的性能,TCP/IP 协议迅速战胜其他竞争对手流行起来,并在 80 年代中期进入了 UNIX 系统内核,促使更多的计算机接入了互联网。
你看,这些东西存活了这么久,可以说是经历了无数的实践和总结,是我们最需要去学习和学懂的底层的不变的知识。这也是为什么网络基础是大学计算机专业一门十分重要的学科的原因。
换句话说,这些东西是我们作为程序员所需要学习的那些不变的知识。
从一篇论文开始
在1989年的一个夏天,这时候我还没出生,时任欧洲核子研究中心的蒂姆·伯纳斯 - 李(Tim Berners-Lee)在一个明媚的下午,终于完成了他耗费心血的一篇论文,提出了在互联网上构建超链接文档系统的构想。在这篇论文中,他确立了三项核心技术:URI、HTML和HTTP。
而这个时候,想必HTTP的发明者也不一定可预见HTTP会在未来发展到如此地步。
HTTP/0.9:宏伟的蓝图
在20世纪90年代,这个时候我刚出生没多久,互联网世界非常的简陋,计算机的处理能力也不行,存储能力就更别提了,最主要的是体积还大的不行。能在网上看看新闻都是天大的奇迹了。这个时候的网速当然也十分有限,所以在网络上使用的协议也都是以纯文本传输,也就能看看纯文字的内容,嗯~~废了这么大劲,我还不如去看报纸,确实,这时候报纸要远比网页好看,毕竟报纸还能有黑白图片。
基于这样的背景,此时的HTTP设计的也十分简陋,采用了纯文本的格式,并且只有GET方法从服务器获取HTML文档,并且在响应请求后立即关闭连接,仅仅只是这样。
但,正是因为最开始的HTTP如此简单,才在未来赋予了它无限的可能。因为,把简单的变复杂,远比把复杂的变简单要容易很多。
那么我们简单总结下这个时候的HTTP的特点:
- 只有请求行,没有请求头和请求体(这样说不太准确,我们后面再聊)。
- 服务器也不会返回任何头信息,只返回客户端想要的数据就可以了。
- 返回的文本内容是用ASCII字符流来传输的。
HTTP/1.0:不标准的标准
虽然HTTP0.9这么简单,但是它已经可以满足当时的需求了。不过,随着世界的发展,在1994年底出现了拨号上网服务,同年网景推出了一款浏览器,从此万维网就不再是单纯的限制于学术交流,而是进入了高速发展的阶段。并且在这个时期,还出现了JPEG的图片格式,以及MP3格式等。也就是说,大众对于媒体展示的需求越发的缤纷了起来。
基于澎湃的技术发展和用户需求,HTTP0.9肯定无法满足大众的需要,最基本的就是网页中不只有纯粹的HTML文本了,还有图片,音频,视频等等。因此ASCII编码肯定满足不了各种媒体的编码方式。
于是HTTP1.0就引入了请求头和响应头,通过这样的方式来让客户端和服务器进行协商,在发起请求的时候,浏览器会告诉服务器我期望你返回给我什么类型的文件,采取什么样的压缩方式等等。
在客户端发送请求行与服务器协商的时候,可能有些需求服务器是处理不了的,于是就需要服务器返回给客户端一个状态,告知客户端处理的结果,这样就引入了状态码。
同时为了减轻服务器的访问压力,HTTP1.0还提供了Cache的缓存机制。
你看,所有的技术发展,都是由客户需求推动的。
HTTP1.0是我们能在RFC中最早可查阅的关于HTTP的一份规范性文档,哦抱歉,说是规范有点不太贴切,HTTP1.0还并不算是一个规范,在原文中叫做memo,也就是算是一个备忘录。我们可以在RFC的目录中筛选一下,找到这个:
我们可以看到,到目前为止,关于HTTP的第一份文档就是在1996年五月份的这份RFC1945,它在最开始有这么一段话:
This memo provides information for the Internet community. This memo does not specify an Internet standard of any kind.
Distribution of this memo is unlimited.
大致意思就是说,这个备忘录提供了一些关于在网络上通信的讨论。并且本备忘录不定义任何类型的互联网标准,并且本协议允许随意传播。然后,我们还可以在下面的文章内容中找到一个关于RFC1945所囊括的范围是什么的一句话:
This document defines both the 0.9 and 1.0 versions of the HTTP protocol.
本文档定义了0.9和1.0两个HTTP版本。换句话说,在RFC1945中,也就是到了HTTP1.0的时候,才真正的形成了一份类似文档的备忘录,但是,它还算不上是标准。可以从文档内容看得出来1.0比0.9多了好多好多东西。
HTTP/1.1:我是真标准
而随着互联网的继续发展,网景的 Netscape Navigator 和微软的 Internet Explorer 开始了著名的“浏览器大战”,都希望在互联网上占据主导地位。这场大战的商业意义和纠纷我们暂且不提,但是它确实,实实在在的推动了Web的发展,在1999年,HTTP1.1版本正式出现,此刻的HTTP协议才算是一个真正的标准,所有要用到HTTP的应用或者设备都必须遵守该协议。
那我想问你个问题,基于RFC的文档,是直接从1.0就到了1.1么?中间没有别的了?首先1.0版本的RFC编号是1945,而1.1版本的编号想必大家耳熟能详就是2616,当然RFC可不仅仅只是为HTTP服务的,所以通过编号的跨度好像也不能解答我上面的问题。
但是,这张图可以:
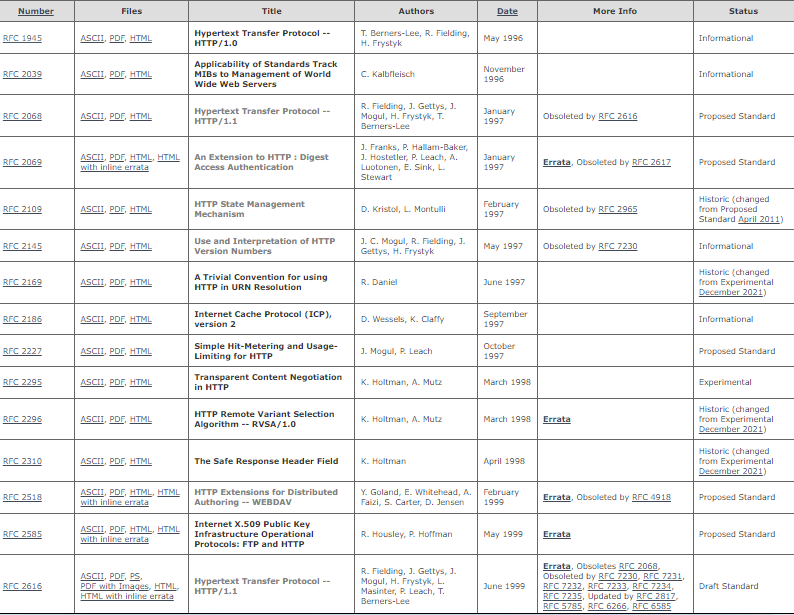
从上图我们着重看一下RFC1945、RFC2068、RFC2616,换句话说,当1.0版本的备忘录出现之后,到RFC2616的1.1版本,中间还有个RFC2068,当然,我们从上图中也可以看到RFC2068已经被RFC2616覆盖了,并且2616也被7230等后续文档所完善和覆盖。
而且,在某一个文档真正标准化之前,实际上还有很多关于某些特性的讨论,不多说,大家有兴趣可以在文末的连接中自己取证。
HTTP1.1在原有的HTTP1.0的基础上做了不少的性能改进,虽然说是一个小范围的改变,但是这些改变所带来的影响可不小。我们下面就就简单的看看HTTP1.1相对于1.0版本都做了哪些核心的优化。
1、增加持久连接
HTTP/1.0每进行一次HTTP通信,都需要经历建立连接、传输数据、断开连接的操作。换句话说,我发送一点点HTTP数据,就要额外的发送十几个包,后面我会用实际的过程带大家看为啥会是十几个包。这实在是有点难受。
但是为啥当时这样就可以呢?因为当时传输数据的体积小,页面也没啥引用的外部连接,全是HTML文本,所以也不会有什么太大的问题,但是随着发展,页面的体积和引用越来越大,这种方式显然已经无法支撑日益发展的需求了。
那么HTTP/1.1为了解决这个问题,增加了持久连接的方法,它的特点是在一个TCP连接上可以传输多个HTTP请求,只要浏览器或者服务器没有明确断开,那么TCP连接就会一直保持。
持久连接在HTTP/1.1中是默认开始的,如果你不想开启持久连接,可以在HTTP的请求头中加上Connection:close。
目前浏览器中对同一个域名,默认允许同时建立6个TCP持久连接,注意!是浏览器默认允许。
2、不成熟的HTTP管线化
我们想象一下,在TCP这条马路上,只能一条单行道,所有跑在这条马路上的车都无法超越前面的车,假如前面的车追尾了,后面所有的车都只能等待前面的事故处理完才能继续同行。
换句话说,假如前一个HTTP请求因为某些原因没有返回结果,那么就会阻塞后面所有的请求,这就是著名的队头阻塞问题。
在HTTP/1.1中,试图通过管线化的技术来解决队头阻塞的问题,在HTTP/1.1中的管线化,会将多个HTTP请求整批提交给服务器的技术,也就是说,虽然马路还是单行道,但是我可以把车叠在一起,一下子发送一批。但是马路上跑的时候可以这样,到了收费站,你还是要下来挨个排队收费。
3、支持虚拟主机
在HTTP/1.0中,每个域名绑定了一个唯一的IP地址,因此一个服务器只能支持一个域名。但是随着虚拟主机技术的发展,需要实现在一台物理主机上绑定多个虚拟主机,每个虚拟主机都有自己单独的域名,这些单独的域名都公用同一个IP。
因此,HTTP/1.1增加了Host字段,用来表示当前的域名地址,这样服务器就可以根据不同的Host值做不同的处理。
4、支持对动态生成的内容
在HTTP/1.0中需要在响应头中完整的设置数据的大小,这样浏览器才能根据设置数据的大小来接受数据。但是随着服务器端的技术发展,很多页面都是动态生成的,在传输数据之前无法知道完整的数据大小,这样肯定不行的,浏览器根本不知道什么时候数据传输完毕。
HTTP/1.1就完美的解决了这个问题,通过把数据包分割成若干个任意大小的数据块,每个数据块都会附上当前数据块的长度,最后发送一个长度为0作为结束的标志,这样就提供了对动态内容的支持。
5、客户端Cookie
想象一下为什么我们需要cookie呢?cookie的作用是什么?你还记得HTTP是无状态的了么?每次发送响应,然后就没有然后了,那当我们需要记录用户状态时怎么做呢?HTTP/1.1就引入了客户端Cookie机制,让客户端可以存储一段数据,传递给服务器,这样服务器就能从保存的数据中读取一定的信息。来实现一定程度的状态保持和用户识别。
当然,因为Cookie可以在客户端存储数据的特性,也在一定情况下当作缓存来使用,可以通过浏览器的API来获取Cookie,但是其实这样做是不安全的,你也可以通过响应头来限制客户端访问Cookie。
当然,还可以设置Cookie的过期时间,设置Cookie的作用域等等。这个我们后面再具体说。
6、安全机制
HTTP/1.1相比于HTTP/1.0增加很多安全机制,这些安全机制都融合进了HTTP的字段使用中,比如SameSite、Referer、Origin,比如Cookie的HttpOnly等等。我们先知道这回事。
HTTPS:给你的钱包上个锁
HTTP/1.1已经新增了很多安全机制,那HTTP就真的安全了么?答案显然是否定的,因为HTTP本身的特性:明文传输。所以HTTP自己根本无法解决传输数据的安全性问题,获取HTTP传输的数据非常容易。
这就导致了你在网络上的任何访问都可能引起你实际的损失和个人信息的透明。在一些购物、政府场景下,对于信息的安全要求更是极高,但是我也说了,HTTP自身是解决不了的。那咋整?
基于这样的前提,HTTPS诞生了,但是实际上来说,HTTPS就是HTTP,只不过在HTTP的上一层不再是TCP了,而是SSL/TLS,换句话说,就是在HTTP和TCP中间又加了一层:
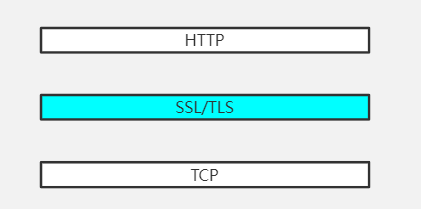
所以你看,其实HTTPS就是HTTP,它的一切都是HTTP赋予的,只不过,HTTP的报文要经过SSL/TLS层的加工处理后才交给TCP。SSL和TLS其实是一个东西,最开始的时候是SSL,后来标准化了之后就叫做TLS了。
HTTP/2:HTTP的极限
现在绝大多数网站所使用的还是HTTP/1.1,这个毋庸置疑。在现在的阶段,HTTP/2在Top1000的网站上也得到了不错的应用,比如谷歌、苹果等等。而在未来,可能会在真正实行的时候直接大力推广使用HTTP/3了,当然,真正的想在应用中广泛使用HTTP/3也不会那么快。
那么我们来简单看下,相比于HTTP/1.1,它有哪些划时代的增强吧。
HTTPS帮助我们解决了HTTP数据传输的安全性问题,并且标准已经十分成熟。所以无论是2也好,还是3也罢,后续的努力,都是在为了性能所奋斗。
一个核心优化就是二进制报文传输,虽然这样不利于阅读,但是在机器的理解和识别上却变得十分简单快速。并且基于二进制又引入了流的概念,我们可以把整个HTTP报文分割成一个又一个小的包,然后每个包会赋予一个唯一的ID,这些包按照次序组装起来就是HTTP的报文了。这个东东有一个大名鼎鼎的称呼,叫做多路复用。
除了多路复用,HTTP/2还可以设置请求的优先级、压缩头字段、服务器推送等等。
最后,我为什么会起这样一个标题呢?因为在使用TCP作为传输协议的基础上,想要再在应用层层面提升性能已经是无计可施了,因为TCP的一些自身特性,以及设备僵化等等原因,其实HTTP/2可以说是性能的极限了。所以,基于这样的原因,才有了HTTP/3。
HTTP/3:面向未来的协议
为什么会有HTTP/3呢?HTTP/3又做了什么事情进一步优化HTTP协议的性能呢?
出现HTTP/3的主要问题还是为了解决HTTP/2无法解决的性能问题,那HTTP/2为啥无法解决呢?因为HTTP/2是基于TCP的,虽然HTTP/2在应用层的层面解决了队头阻塞的问题,但是到了TCP这里,你还是要在TCP这条马路上传输数据包啊,TCP还是会队头阻塞,所以,你要想真正的解决队头阻塞的问题,就只能完全舍弃有问题的这个协议。
但是我之前也说了,TCP是存在设备僵化的,也就是现在全球的设备都在使用TCP,你想让每一个电脑都换成新发明的协议么?显然这不现实,那咋整呢?嗯,一个办法是要么搞一个新协议,这个新协议可以兼容TCP,一个办法是换一个没有TCP协议的问题的协议。
嗯,所以HTTP/3就不再使用TCP作为传输层协议了,而是使用UDP,UDP是无连接的,根本就不需要三次握手四次挥手啥的,所以天然就比TCP快很多。这也是为什么新的HTTP/3没有选择去创造一个兼容TCP的协议,因为你只要是需要面向连接的协议,那就跑不出这样的围墙,所以干脆我就不用你了。
但是用UDP协议还是有很多问题。那咋整呢,于是在UDP和HTTP/3之间加了一层QUIC,在UDP的基础上实现了就像TCP那样的可靠传输,所以HTTP/3基于UDP和QUIC,抛弃了TCP的缺点,保证了TCP的优点。这就是面向未来的协议啦。
当然,现在的HTTP/3还有很多不稳定、不确定、待商榷的内容,但是终有一天吧,我们想要的,我们都能做到。
小结
- 本篇啊,我们简单的过了一下HTTP的过去、现在和未来,那你知道为什么我在到了某一个阶段就不再附上时间节点了么?
- 从过去到未来,我们最想要解决的HTTP的性能问题是什么?
- 多路复用是咋复用的?
参考资料:
本文来自博客园,作者:Zaking,转载请注明原文链接:https://www.cnblogs.com/zaking/p/16842600.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号