
视频理解模型推理与微调
视频理解模型推理与微调
随着多模态大模型的持续发展,视频理解、多模态检索和智能标注等应用场景逐渐落地。为了进一步探究多模态视频理解模型在实际工程中的应用方式,本文以 Qwen3-VL 系列模型为例,系统梳理其在视频场景下的推理与全参数微调实践。文章首先通过一个完整的视频本地推理示例,详细拆解模型输入的构建流程,包括视频帧采样、patch 划分以及时序与空间维度的合并等关键细节;随后基于真实游戏视频数据,介绍视频指令微调数据集的构建方法,并完成一次全参数微调与效果验证。
1. 视频推理
首先看一个qwen3-vl-4b-instruct模型做视频本地推理的例子,示例代码如下:
from transformers import AutoProcessor, AutoModelForVision2Seq
from qwen_vl_utils import process_vision_info
import warnings
warnings.filterwarnings("ignore", category=FutureWarning, module="transformers")
import os
# 加载模型和处理器
model_path = "Qwen/Qwen3-VL-4B-Instruct"
processor = AutoProcessor.from_pretrained(model_path)
# 加载视觉-文本模型
model, output_loading_info = AutoModelForVision2Seq.from_pretrained(
model_path,
torch_dtype="auto",
device_map="auto",
output_loading_info=True
)
print("output_loading_info", output_loading_info)
# 配置视频处理参数
video = "./1.mp4"
total_pixels = 20480 * 32 * 32 # 总像素限制
min_pixels = 64 * 32 * 32 # 最小像素限制
max_frames = 2048 # 最大帧数
sample_fps = 2 # 采样帧率
max_new_tokens = 2048 # 生成的最大 token 数
prompt = "请描述这个视频的内容"
# 构建对话消息
messages = [
{
"role": "user",
"content": [
{
"video": video,
"total_pixels": total_pixels,
"min_pixels": min_pixels,
"max_frames": max_frames,
'sample_fps': sample_fps
},
{
"type": "text",
"text": prompt
},
]
},
]
# 应用对话模板
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# 处理视觉信息
image_inputs, video_inputs, video_kwargs = process_vision_info(
[messages],
return_video_kwargs=True,
image_patch_size=16,
return_video_metadata=True
)
# 分离视频数据和元数据
if video_inputs is not None:
video_inputs, video_metadatas = zip(*video_inputs)
video_inputs, video_metadatas = list(video_inputs), list(video_metadatas)
else:
video_metadatas = None
# 准备模型输入
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
video_metadata=video_metadatas,
**video_kwargs,
do_resize=False,
return_tensors="pt"
)
inputs = inputs.to('cuda')
# 生成输出
output_ids = model.generate(**inputs, max_new_tokens=max_new_tokens)
# 提取生成的部分(去除输入)
generated_ids = [
output_ids[len(input_ids):]
for input_ids, output_ids in zip(inputs.input_ids, output_ids)
]
# 解码为文本
output_text = processor.batch_decode(
generated_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=True
)
print(output_text)
['视频由多个镜头组成,展现了动漫风格的画面和人物。第一部分是一个男性角色的特写,他有着黑色长发,额头中央有一道红色印记,眼神锐利,手指轻触脸颊,表情严肃。画面中出现字幕:“顾长歌真是嘎嘎坏”,“几百岁的老女人的主意他也打”,“就在顾长歌陷害唐天后”。这暗示了角色顾长歌的狡猾和他所策划的阴谋。\n\n第二部分切换到一个女性角色的特写,她有着长长的黑发,眉目间流露出一丝冷笑,嘴角上扬,似乎在策划或执行某个计划。字幕显示:“他吩咐尹湄”,“让唐天的姐姐唐婉亲自过来赎人”。这表明她被顾长歌指派去执行某个任务。\n\n第三部分是另一个女性角色的特写,她的紫色眼睛非常醒目,眼神中透露出惊讶和震惊。字幕显示:“唐婉有着一门预知祸福的术法神通”,“当她用这种术法”,“对这次赎人之约推演时”,“却意外的撞到了城”。这说明唐婉拥有某种预知能力,但在推演时却意外地遇到了什么,暗示了剧情的转折。\n\n整个视频通过这些特写镜头,展现了角色之间的复杂关系和剧情的发展,充满了紧张和悬念。']
1.1. 模型输入说明
这里着重注意一下模型的输入部分处理。可以看到在构建inputs时,需要有几个输入,分别为[text]、image_inputs、video_inputs、video_metadatas和video_kwargs,以及do_resize=False。
首先text是对话模板,其对应的内容为:
'<|im_start|>user\n<|vision_start|><|video_pad|><|vision_end|>请描述这个视频的内容<|im_end|>\n<|im_start|>assistant\n'
可以看到,text定义了后续输入到模型的模板,其中video_pad即为占位token,后续将由实际的video数据进行补充。
1.2. 视频帧信息准备
image_inputs, video_inputs和video_kwargs为 process_vision_info() 方法处理后的返回。这个方法是将原始视频文件转换为模型可以理解的格式,具体地说,会做以下几件事情:
- 使用opencv读取视频基本信息,包括视频的fps(假设是60 fps), total_frames(假设视频为15s,则为900帧), width(1280)和height(720)
- 按照指定的sample_fps进行帧采样,这里指定为2,也就是每1s采2帧。原视频为15秒900帧的话,在采样后就是30帧,采样间隔就是60/2=30,也就是每30帧取1帧。这样就得到了后续用于推理的帧序列(0, 31, 62, …, 899)
- 动态调整分辨率。在传入的messages参数里除了video的路径外,还包括, min_pixels(指定为64 * 32 * 32 = 65,536), total_pixels(指定为20480 * 32 * 32=20,971,520) 和 sample_fps的信息。sample_fps的作用上面已经提到。total_pixels和min_pixels用于约束调整分辨率。
- 假设原始视频是1280 x 720的分辨率,也就是每帧包含921,600个像素。那30帧 * 921,600 = 27,648,000总像素,大于指定的max_pixels。所以会继续对帧序列进行像素缩放
- 调整到patch_size的整数倍。Patch size是ViT(Vision Transformer)架构的核心设计,它是将图像切分为固定大小的patch,每个patch最终作为1个token输入到transformer中。这里patch size指定为16,也就是每个token本质上是一个16x16的像素区域。所以需要基于patch_size的设置,将每帧调整到patch_size的整数倍
- 对齐到patch_size的整数倍后,最终分辨率为1152 x 640
- 最后将帧列表,也就是抽取的30帧,做了分辨率调整,做了基于patch_size调整后的帧序列,转为PyTorch张量并返回。
最后可以看到video_inputs的结果为单元素的list,这单个元素里为1个tuple,包含2部分:
- 一个shape为([30, 3, 640, 1152]) 的张量,分别代表帧id、RGB通道、缩放后的分辨率640 x 1152
- 另一个为视频的metadata信息,包括fps和frame_indices(采样后的帧序列),以及total_num_frames
所以在后续代码中还有一步是:
if video_inputs is not None:
video_inputs, video_metadatas = zip(*video_inputs)
video_inputs, video_metadatas = list(video_inputs), list(video_metadatas)
这是将video_inputs和video_metadatas拆开,在video_inputs中只保留帧的信息。
1.3. 模型输入信息准备
在视频帧信息准备好之后,还有最后一步,将视频帧信息添加到text模板中,也就是这段代码:
inputs = processor(text=[text], images=image_inputs, videos=video_inputs, video_metadata=video_metadatas, **video_kwargs, do_resize=False, return_tensors="pt")
此时输入数据为:
text = '<|im_start|>user\n<|vision_start|><|video_pad|><|vision_end|>请描述这个视频的内容<|im_end|>\n<|im_start|>assistant\n'
video_inputs = [torch.Tensor([30, 3, 640, 1152])]
video_metadatas = [{"fps":30, "frame_indices":[0, 31, 62, …, 899], "total_num_frames": 900}
经过processor处理后的inputs结果为:
{'input_ids': tensor([[151644, 872, 198, ..., 151644, 77091, 198]]), 'attention_mask': tensor([[1, 1, 1, ..., 1, 1, 1]]), 'pixel_values_videos': tensor([[ 0.2000, 0.2000, 0.2000, ..., -0.1529, -0.2549, -0.3176],
[ 0.1843, 0.1843, 0.1843, ..., 0.1843, 0.1137, 0.0824],
[ 0.1451, 0.1451, 0.1451, ..., -0.1373, -0.0667, -0.0275],
...,
[ 0.4431, 0.4588, 0.4745, ..., 0.2078, 0.2000, 0.2000],
[ 0.4510, 0.4588, 0.4588, ..., 0.2157, 0.2314, 0.2471],
[ 0.5451, 0.5529, 0.5686, ..., 0.3725, 0.3882, 0.3882]]), 'video_grid_thw': tensor([[15, 40, 72]])}
首先看video_grid_thw,这个表示的patch布局,前面提到缩放后的分辨率为640 x 1152,对应到patch=16后的patch布局则为40 x 72。但这里有个问题,为什么采样时帧数为30,这里变成了15?
通过阅读Qwen3VLVideoProcessor的源码[1]可以了解到有一个重要参数是temporal_patch_size=2(也可以在模型的config文件里看到这个参数)。这个参数代表的含义是:模型一次看多少帧作为一个token。也可以理解为每个video token覆盖的连续帧数。在这里指定为2,也就表示每2帧合并成1个时间patch,这样就天然包含了帧序列中运动/变化的信息。这个参数越小,能捕捉到的动作变化就越细,对应消耗的token也越多。所以这就解释了为什么输入模型的patch布局为15 * 40 * 72。
再看pixel_value_videos的shape为torch.Size([43200, 1536]):
- 第一维的43200很好理解,就是这个视频的patch数量,也就是15 * 40 * 72 = 43,200。
- 现在我们已知输入模型的1个vision token(也就是patch token)的组成为:2帧 * patch像素。每个patch对应的像素为:2 * 3(RGB通道) * (16*16) =1536,这就对应到了pixel_value_videos的第二维,也就是每个patch的维度。
最后再看input_ids结果,其shape为([1, 10938]),对其做decode的结果为:
<|im_start|>user
<0.3 seconds><|vision_start|>
<|video_pad|>*10800 (表示出现10800次<|video_pad|>)
<|vision_end|>请描述这个视频的内容<|im_end|>
<|im_start|>assistant
这里我们已知<|video_pad|>是作为后续video patch token的占位符。那为什么上面计算得到的原始vision patch的数量为43200,但到真正转为token ids时就只有10800个vision token了?这涉及到另一个参数为spatial_merge_size(Qwen3-VL-4B-Instruct里默认为2)。这个参数是一个空间下采样/特征合并参数,用来控制“把相邻的小 patch 聚合成一个大 token”的粒度,从而直接决定视觉序列的长度与后续计算量。更直接点说,就是为了减少后续attention的计算量从而节约计算资源。如果取值为2,则表示把2 x 2 个原始patch特征再拼接成1个token,从而减少4倍的序列长度,所以merge后为10800个token id,也就是43200 / 4 = 10800。
最后,在运行model.generate()时,将<|video_pad|>替换为merge后的patch特征,便构造了视频推理模型的输入,开始执行prefill+decode推理流程。
2. 模型全参微调
在理解了视频推理的流程后,继续进行模型微调。首先需要准备一些视频素材并进行打标。
2.1. 视频训练数据准备
这里我们从开源数据集MicroLens[2]中选取了部分王者荣耀视频的数据,并对其做了切分,将视频切分为15s以下的片段,然后人工补充描述。
对于一个示例片段:


让Qwen3-VL-4B-Instruct进行描述:
输入:描述这个视频并进行打标,使用json输出标签
输出为:
{
"video_description": "视频展示了一款多人在线战斗竞技游戏的实时对战场景。画面中,玩家操控角色在游戏地图上进行激烈战斗,使用技能和装备进行攻击和防御。屏幕左下角显示了一位玩家正在直播,他专注地操作着游戏,背景是蓝色条纹窗帘。游戏界面显示了角色的血量、技能冷却、装备状态以及小地图等信息。战斗过程中,角色不断释放技能,造成伤害并获得金币。屏幕右下角有操作按钮,包括技能释放和移动控制。画面中还出现了中文文字提示,如“老夫子跟我们开团吧”和“他凭什么跟我打”,显示了玩家在游戏中的对话和策略。整体氛围紧张刺激,充满竞技性。",
"tags": [
"游戏直播",
"多人在线战斗竞技",
"角色扮演",
"技能战斗",
"游戏界面",
"直播主播",
"竞技对战",
"游戏策略",
"中文文字",
"实时战斗"
]
}
下面我们对这类游戏视频使用以下模式进行打标,例如:
{
"video": "wzry/4/1.mp4",
"conversations": [{
"from": "human",
"value": "<video>\n描述这个视频并进行打标,使用json输出标签"
},
{
"from": "gpt",
"value": {
"video_description": "视频展示的王者荣耀游戏的界面。在画面中,首先展示的是角色信息界面和他们的战绩,角色包括凯、元歌、嬴政。然后又展示了角色澜、狄仁杰和不知火舞。接下来是男主播操作凯的记录,画面左下角的小框是男主播的视频。整体画面中展示了凯和敌方交战的场景,其中凯发动了变身技能和三个敌方单位进行交战。在交战过程中凯终结了狄仁杰。",
"tags": [
"游戏直播",
"王者荣耀",
"凯",
"狄仁杰",
"澜",
"战斗画面"
]
}
}
]
后续按照这个模式准备对应的训练数据。
2.2. 模型训练
首先我们使用小模型进行测试并验证效果,使用Qwen3-VL-4B-Instruct模型,参考官方提供的训练脚本进行训练[3]。
训练模型的命令为:
torchrun \ # ========== 分布式启动 ========== --nproc_per_node=8 \ --master_addr=127.0.0.1 \ --master_port=29500 \ # ========== 训练入口 ========== Qwen3-VL/qwen-vl-finetune/qwenvl/train/train_qwen.py \ # ========== DeepSpeed ========== --deepspeed=Qwen3-VL/qwen-vl-finetune/scripts/zero3.json \ # ========== 模型与数据 ========== --model_name_or_path=Qwen/Qwen3-VL-4B-Instruct \ --dataset_use=wzry_video%100 \ # ========== 输出与实验标识 ========== --output_dir=./output/wzry_video_finetune \ --run_name=wzry_video_qwen3vl_4b \ # ========== 多模态可训练模块 ========== --tune_mm_vision=True \ --tune_mm_mlp=True \ --tune_mm_llm=True \ # ========== 精度与训练轮数 ========== --bf16 \ --num_train_epochs=20 \ # ========== Batch & 累积 ========== --per_device_train_batch_size=2 \ --per_device_eval_batch_size=4 \ --gradient_accumulation_steps=4 \ # ========== 学习率(分模块) ========== --learning_rate=2e-05 \ --mm_projector_lr=4e-05 \ --vision_tower_lr=2e-06 \ # ========== 优化器与调度 ========== --weight_decay=0.01 \ --warmup_ratio=0.03 \ --lr_scheduler_type=cosine \ --max_grad_norm=1.0 \ # ========== 上下文与数据组织 ========== --model_max_length=8192 \ --data_flatten=True \ --data_packing=False \ # ========== 视频采样参数 ========== --video_fps=4 \ --video_max_frames=32 \ --video_min_frames=16 \ # ========== 视频分辨率 / token 控制 ========== --video_max_pixels=1003520 \ --video_min_pixels=401408 \ --max_pixels=602112 \ --min_pixels=100352 \ # ========== 评估与保存 ========== --eval_strategy=no \ --save_strategy=epoch \ --save_steps=2 \ --save_total_limit=3 \ # ========== 日志 ========== --logging_steps=2 \ --report_to=tensorboard \ --gradient_checkpointing=True \ --dataloader_num_workers=4
其中我们介绍几个在视频理解模型里的参数:
1. 多模态参数是否可训练,包括Vision Encoder,多模态投影层和语言模型:
a) --tune_mm_vision=True --tune_mm_mlp=True --tune_mm_llm=True
b) 也就是说,这是个全参微调,适合于GPU资源比较充足的情况,达到更好的效果。否则可以冻结部份参数
2. 视频参数:
a) --video_fps=4 --video_max_frames=32 --video_min_frames=16
b) --video_max_pixels=1003520 --video_min_pixels=401408 --max_pixels=602112 --min_pixels=100352
c) 这几个参数是控制帧采样与单帧分辨率,防止GPU OOM和token帧数太多的情况,将token数resize到合理的空间范围内。和推理时指定的参数类似
所以,在gpu资源有限时,除了常规的减少batch size、model_max_length、切换zero stage、使用lora等,还可以调整上述的例如冻结Vision Encoder层、控制视频参数等来进行进一步的减少gpu的需求。
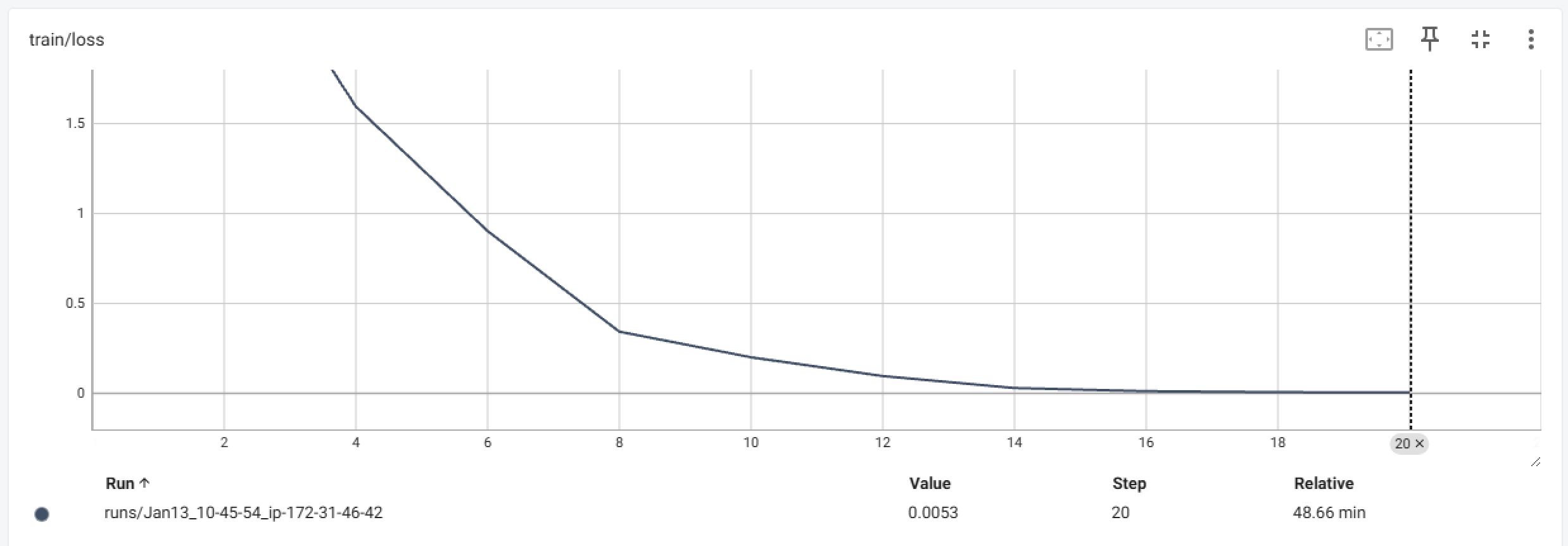
从训练过程来看,收敛良好:
下面测试全参微调后与原始模型的对比效果,使用另一个示例视频:
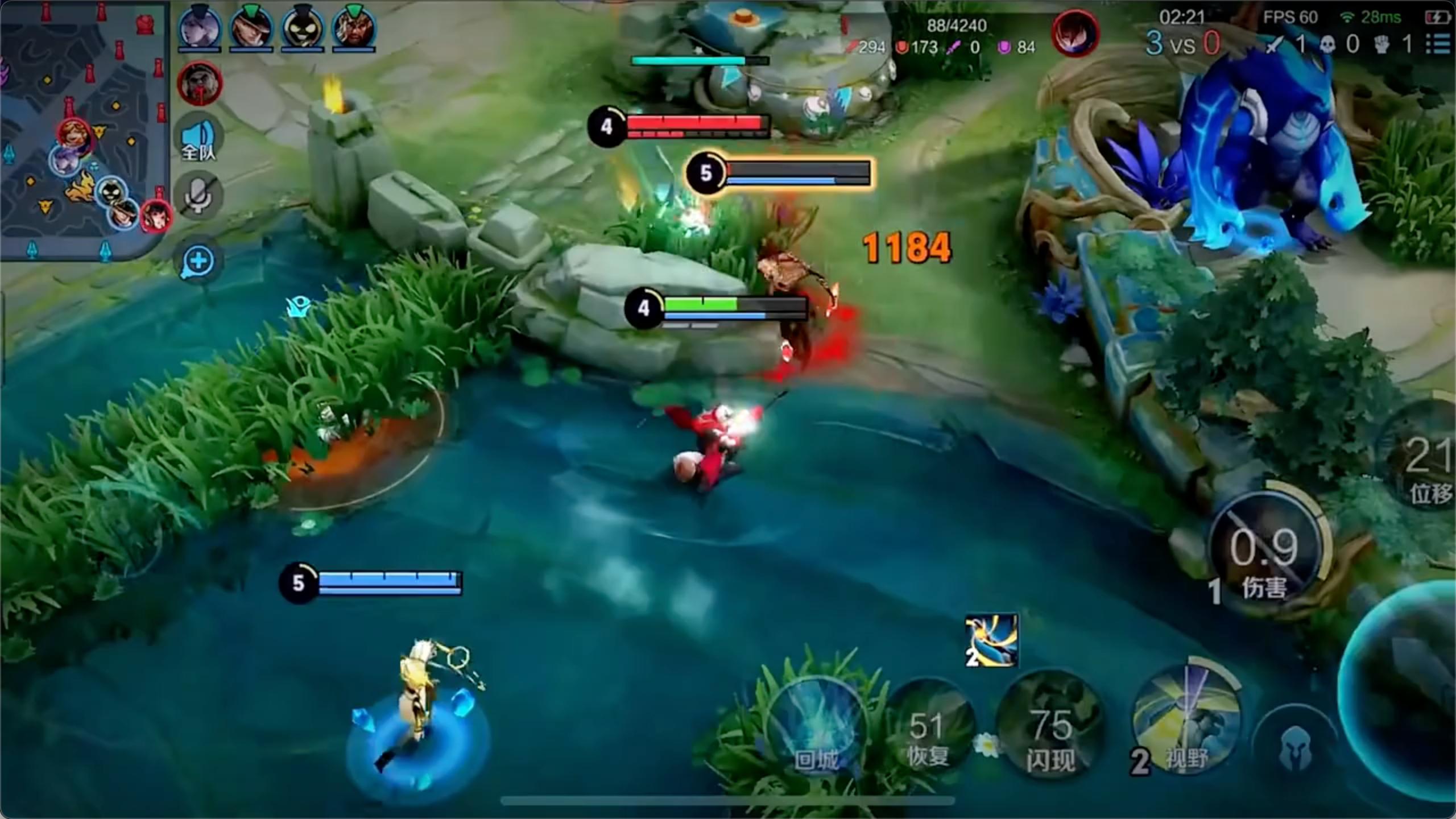

可以看到原始模型对视频做了整体的理解,可以正常理解为游戏画面,以及视频的大致内容:
python test_inference.py --model Qwen/Qwen3-VL-4B-Instruct --video ../data/wzry/57/2.mp4 --prompt "描述这个视频并进行打标,使用json输出标签,使用中文。"
{
"video_description": "这是一段《王者荣耀》的游戏录像,展示了玩家在游戏中的战斗和操作过程。画面中可以看到多个英雄角色在河道区域进行激烈对战,其中包括使用技能攻击敌方单位、躲避伤害以及利用地形优势进行战术配合。屏幕左上角显示了小地图和队伍状态,右下角则有技能按钮和伤害数值提示。整个场景充满动感,展现了快节奏的MOBA竞技风格。",
"tags": [
"王者荣耀",
"MOBA游戏",
"英雄对战",
"技能释放",
"团队协作",
"游戏直播",
"战斗场面",
"游戏策略"
]
}
然后再看微调后的模型效果,可以看到视频对内容理解的更为精准:
python test_inference.py --model ~/multi-model-train/output/wzry_video_finetune/ --video ../data/wzry/57/2.mp4 --prompt "描述这个视频并进行打标,使用json输出标签"
{
"video_description": "这是王者荣耀游戏界面,刚开始是角色“百里守约”的游玩记录,左上角显示的是敌方信息和我的方信息。在画面中,“百里守约”开枪击败了角色“苏烈”。然后“百里守约”受到了敌方的攻击,在使用技能位移了一段距离后发动技能与对方角色“澜”交战,并将对方打成残血。",
"tags": [
"王者荣耀",
"百里守约",
"澜",
"战斗画面"
]
}
3. 总结
本文围绕 qwen3-vl-4b-instruct,对多模态视频理解中的推理与全参数微调过程进行了完整实践,从视频输入构建、推理执行,到基于真实游戏视频的数据准备与训练配置,系统梳理了多模态模型在视频场景下的工程细节。后续我们将进一步介绍如何对视频这类非结构化特征进行统一管理,并逐步完善模型的持续训练 pipeline,包括特征处理、版本化与管理机制,以及模型版本的管理与部署,以支撑更稳定、可扩展的多模态应用落地。
References
1. video_processing_qwen3_vl.py:https://github.com/huggingface/transformers/blob/main/src/transformers/models/qwen3_vl/video_processing_qwen3_vl.py
2. MicroLens Github:https://github.com/westlake-repl/MicroLens
3. QwenVL Training Framework: https://github.com/QwenLM/Qwen3-VL/tree/main/qwen-vl-finetune

 浙公网安备 33010602011771号
浙公网安备 33010602011771号