



DataFrames,Datasets,与 SparkSQL
1. DataFrames,Datasets,与SparkSQL
Spark SQL 以及它的 DataFrames和Datasets 接口是Spark性能的未来,它们提供了更高效的存储选择,高级的优化器,以及在序列化数据上的直接操作。
这些组件对于获取Spark高性能至关重要。下图是一个性能对比:
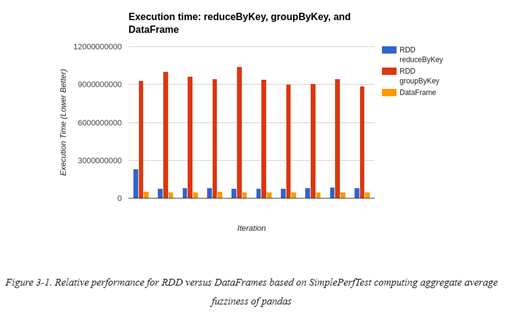
与RDDs一样,DataFrames与Datasets代表的是分布式数据集合,但是它们相对于RDDs来说,还会保有额外的schema信息。这个额外的schema信息可用于提供更高效的存储层(Tungsten),并在优化器中(Catalyst)可以执行额外的优化。
除了schema信息,对于在Datasets与DataFrames上执行的操作,优化器中可以检查它们的逻辑含义,而不仅是执行函数而已。
2. SparkSession(or HiveContext or SQLContext)
在Spark应用中,SparkContext为它的entry point;在流程序中,对应的为 StreamingContext。而在SparkSQL中,它的entry point为SparkSession。正如其他的Spark组件一样,我们需要import以下额外的组件,以使用SparkSQL:
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession, Row}
import org.apache.spark.sql.catalyst.expressions.aggregate._
import org.apache.spark.sql.expressions._
import org.apache.spark.sql.functions._
如果使用的是Spark Shell,则会自动获取一个SparkSession,名为spark(如Spark中对应的sc)。
SparkSession一般是使用builder 模式创建,使用的方法是getOrCreate()。如果已存在一个session,则直接获取,否则创建一个新的。此builder可以接受基于string的key-value 配置项:config(key, value);以及一些常见配置的快捷方法。
在快捷配置中,其中比较重要的一个是enableHiveSupport(),它可以在不需要安装 Hive 的情况下,给用户提供访问Hive UDFs的权限(但是需要引入额外的jar包)。下面的例子展示了如何创建一个支持 Hive 的SparkSession:
val session = SparkSession.builder() .enableHiveSupport() .getOrCreate() // Import the implicits, unlike in core Spark the implicits are defined // on the context. import session.implicits._
enableHiveSupport() 这个快捷方法不仅配置了Spark SQL 使用这些 Hive jars,同时也会主动检查hive 类是否能被导入。如果不能导入,(相对于手动指定config值)则会抛出更清晰的报错信息,具体实现源码为:
/**
* Enables Hive support, including connectivity to a persistent Hive metastore, support for
* Hive serdes, and Hive user-defined functions.
*
* @since 2.0.0
*/
def enableHiveSupport(): Builder = synchronized {
if (hiveClassesArePresent) {
config(CATALOG_IMPLEMENTATION.key, "hive")
} else {
throw new IllegalArgumentException(
"Unable to instantiate SparkSession with Hive support because " +
"Hive classes are not found.")
}
}
/**
* @return true if Hive classes can be loaded, otherwise false.
*/
private[spark] def hiveClassesArePresent: Boolean = {
try {
Utils.classForName(HIVE_SESSION_STATE_BUILDER_CLASS_NAME)
Utils.classForName("org.apache.hadoop.hive.conf.HiveConf")
true
} catch {
case _: ClassNotFoundException | _: NoClassDefFoundError => false
}
}
可以看到,调用enableHiveSupport()方法后,会自动检查Hive 相关 classes是否能导入,若无法导入则会报错。
若是API中有提供快捷配置方法,则优先建议使用这些方法做配置。因为常规的config接口中,不会做配置验证。
对于getOrCreate方法,需要注意的是:如果一个session已经在存在了,则你的配置值可能会被忽略,并直接得到一个已存在的SparkSession。一些选项,例如master的配置,也仅会在没有已存在的SparkContext运行时,创建一个新的 SparkContext并应用此配置;否则,直接返回一个已有的SparkContext。
在Spark 2.0以前,在使用Spark SQL时,使用的是两个独立的entry points(HiveContext 或 SQLContext)。它们的主要区别在于:HiveContext不需要安装一个Hive。HiveContext优于SQLContext。如果你有hive依赖冲突,且无法解决时,才建议使用SQLContext。相对于SQLContext,HiveContext有更完整的SQL parser,以及additional UDFs。下面是创建一个HiveContext的例子:
val sc = new SparkContext() val hiveContext = new HiveContext(sc) // Import the implicits, unlike in core Spark the implicits are defined // on the context. import hiveContext.implicits._
在使用时,我们应优先考虑使用SparkSession,然后再考虑HiveContext,最后是SQLContext。有些情况下,可能Spark的库并未更新HiveContext或SQLContext中的方法到SparkSession中,所以可能仍有使用HiveContext/SQLContext的需求。下面是创建SQLContext或HiveContext所需要的额外的导入库信息:
import org.apache.spark.sql.SQLContext import org.apache.spark.sql.hive.HiveContext import org.apache.spark.sql.hive.thriftserver._
在使用SparkSQL与Spark-Hive时,需要引入的sbt/maven 库为(以2.4.0 版本为例):
// https://mvnrepository.com/artifact/org.apache.spark/spark-hive libraryDependencies += "org.apache.spark" %% "spark-hive" % "2.4.0" % "provided" // https://mvnrepository.com/artifact/org.apache.spark/spark-sql libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.4.0"
2. Schema基础
Schema的信息,以及它启用的优化过功能,是SparkSQL与core Spark之间的一个核心区别。检查schema对于DataFrames尤为重要,因为RDDs与Datasets中没有模板化的类型。无论是加载数据时的引用、还是基于父DataFrames做计算、亦或是在DataFrames上应用transformation,schema一般都是由Spark SQL自动处理。
DataFrames以人类可读、以及程序化格式,这两种方式描述schema。printSchema() 会显示一个DataFrame的schema,此方法常用于spark-shell中,用于及时了解当前处理的数据的schema。这对于数据各执(如JSON)来说特别有用,因为一般若仅查看一小部分数据、或是仅读一个header,可能无法立即判断出数据的schema信息。在程序用法上,我们可以调用schema直接获取数据schema信息(常用于ML pipeline transformers)。鉴于大家可能都已经很熟悉了case classes 和 JSON,这里我们拿JSON举例,看看如何在spark中表示:
JSON 数据:
{
"name": "mission",
"pandas": [{
"id": 1,
"zip": "94110",
"pt": "giant",
"happy": true,
"attributes": [0.4, 0.5]
}]
}
对应的 case class:
case class RawPanda(id: Long, zip: String, pt: String, happy: Boolean, attributes: Array[Double]) case class PandaPlace(name: String, pandas: Array[RawPanda])
根据创建的 case class,我们可以创建一个本地实例,将它转为一个Dataset,并打印出它的schema信息:
def createAndPrintSchema()={
val damao = RawPanda(1, "M1B 5K7", "giant", true, Array(0.1, 0.1))
val pandaPlace = PandaPlace("toronto", Array(damao))
val df = session.createDataFrame(Seq(pandaPlace))
df
}
使用df.printSchemat打印出的schema信息为:
root
|-- name: string (nullable = true)
|-- pandas: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- id: long (nullable = false)
| | |-- zip: string (nullable = true)
| | |-- pt: string (nullable = true)
| | |-- happy: boolean (nullable = false)
| | |-- attributes: array (nullable = true)
| | | |-- element: double (containsNull = false)
Schema信息除了便于人类阅读外,也可以用于编程时使用。用于编程的schema 可以通过df.schema 返回,例如:
> df.schema
res0: org.apache.spark.sql.types.StructType = StructType(
StructField( name,StringType,true),
StructField( pandas,
ArrayType(
StructType( StructField( id,LongType,false),
StructField( zip,StringType,true),
StructField( pt,StringType,true),
StructField( happy,BooleanType,false),
StructField(attributes,ArrayType(DoubleType,false),true)),
true),true))
可以看到返回的是一个StructType类型,里面的元素是StructField,它的case class定义如下:
case class StructField(
name: String,
dataType: DataType,
nullable: Boolean = true,
metadata: Metadata = Metadata.empty) {
…
这里可以注意到,StructField可以嵌套StructField,正如case class嵌套一样。StructFiled的参数指定name、type、以及一个布尔值表示此字段可能是null或是缺失。
2. DataFrameAPI
DataFrameAPI可用于操作DataFrames,过程不需要注册临时表或产生任何SQL表达式。它也包含transformations和actions两类操作。
Transformations
在DataFrameAPI中的transformation与RDD中的概念类似,但是有更多的关系型风格。在RDD中,我们可以使用任意的函数,对此,optimizer无法对此进行优化。而在DataFrameAPI中,通过使用有限制的表达式语法,optimizer 可以有更多的信息用于优化。和RDD一样,我们可以将DataFrame中的变换(transformations)大致分解为简单单个DataFrame、多个DataFrame、key/value、以及grouped/windowed transformations。
这里需要注意的是:SparkSQL 变换仅仅是部分惰性的,因为schema是立即计算的
简单的DataFrame变换与SQL表达式
DataFrame中的变换与RDD中的基本一致,它们的区别是:在DataFrame中使用的是Spark SQL 表达式,而RDD中用的是arbitrary functions。DataFrame中的函数,例如filter,接受的是Spark SQL表达式,而不是lambda函数。下面我们以DataFrames中不同的filter操作为例,进行进一步探讨。
首先创建两个示例数据:
def createPandaInfo()={
val damao = RawPanda(1, "M1B 5K7", "giant", true, Array(0.1, 0.1))
val tuantuan = RawPanda(2, "B11, 7JK", "small", false, Array(0.05, 0.1))
val df = session.createDataFrame(Seq(damao, tuantuan))
df
}
> val pandaInfo = createPandaInfo
pandaInfo: org.apache.spark.sql.DataFrame = [id: bigint, zip: string ... 3 more fields]
对于DataFrame,(假设这里的一个实例化变量是df)我们可以通过df(“列名”) 访问到列的信息,注意这里只是列的信息,并不是列的数据,例如:
scala> pandaInfo.columns
res37: Array[String] = Array(id, zip, pt, happy, attributes)
scala> pandaInfo("happy")
res38: org.apache.spark.sql.Column = happy
在执行filter时,若是需要从列上筛选,则在指定列上给出filter语句即可,例如:
pandaInfo.filter(pandaInfo("happy") !== true).collect
res45: Array[org.apache.spark.sql.Row] = Array([2,B11, 7JK,small,false,WrappedArray(0.05, 0.1)])
也可以对多个列执行过滤:
pandaInfo.filter(
| (pandaInfo("happy") !== true).and(pandaInfo("attributes")(0) < pandaInfo("attributes")(1))
| ).collect
res53: Array[org.apache.spark.sql.Row] = Array([2,B11, 7JK,small,false,WrappedArray(0.05, 0.1)])
从上面的例子可以看到,可以对嵌套元素进行访问,例如pandaInfo("attributes")(0),以及多个过滤条件之间使用 .and 方式进行连接。
还有一点需要注意的是,在与常数进行比较时,必须将列名写在常数前面,例如:
> pandaInfo.filter(0 < pandaInfo("id")).collect
<console>:43: error: overloaded method value < with alternatives:
(x: Double)Boolean <and>
…
cannot be applied to (org.apache.spark.sql.Column)
> pandaInfo.filter( pandaInfo("id") > 0).collect
res60: Array[org.apache.spark.sql.Row] = Array([1,M1B 5K7,giant,true,WrappedArray(0.1, 0.1)], [2,B11, 7JK,small,false,WrappedArray(0.05, 0.1)])
因为SparkSQL的 column operator 是定义在 column class上的,所以表达式 0 >= pandaInfo.col("id") 不会被编译,因为Scala会在 0 上使用 >= 的操作符,而不是在列上使用。所以此时需要将列写在前面,或是将0转换为一个column(使用lit方法),例如:
scala> lit(0)
res63: org.apache.spark.sql.Column = 0
scala> pandaInfo.filter( lit(0) < pandaInfo.col("id")).collect
res64: Array[org.apache.spark.sql.Row] = Array([1,M1B 5K7,giant,true,WrappedArray(0.1, 0.1)], [2,B11, 7JK,small,false,WrappedArray(0.05, 0.1)])
filter仅是一个很简单的例子,对于更多DataFrame标准方法,可以去参考SparkSQL官方API文档。
3. 在DataFrames与Datasets中的数据表示
DataFrames 相对于RDDs,更是一种行式对象;且DataFrames与Datasets有专门的表示方法、以及列式缓存格式。这种专门的表示方法,不仅可以更高效的使用存储空间,甚至还可以实现比Kryo序列化更快的编码。不过有一点需要说明的是,DataFrames与Datasets与RDDs一样,一般都是惰性执行的,并建立在它们的依赖谱系之上(除了DataFrames中,它被称为一个logical plan,且包含更多的信息)。
Tungsten
Tungsten是一个新的Spark SQL组件,通过直接在byte level运作,提供更高效的Spark操作。下面我们对比一下 DataFrames与RDDs的cache情况:
首先是 DataFrames:
def dfcahce()={
val rawdata = sc.textFile("s3://xxxx/ ")
val caseRdd = rawdata.map(x => {
val words = x.split(",")
item(words(0), words(1), words(2), words(3), words(4))
})
val dfcache = session.createDataFrame(caseRdd)
dfcache.persist()
dfcache.filter(dfcache("id") === 12545).collect
}
执行代码查看cache情况:

然后是RDD:
def rddCache()={
val rawdata = sc.textFile("s3://tang-emr/mediumdata/")
val caseRdd = rawdata.map(x => {
val words = x.split(",")
item(words(0), words(1), words(2), words(3), words(4))
})
caseRdd.persist()
caseRdd.filter(_.id == "12545").collect
}
执行代码后查看cache情况:

有关storage,这里需要注意的是,在执行了persist() 方法后,会将RDD数据缓存在executor的内存中。所以此时即使一个job结束后,container并不会被回收。因为它们需要将数据缓存在内存。在一个application结束后,Storage页面就不会再有RDD缓存的信息显示。
使用Tungsten时,它所占用的对象空间远小于序列化对象(使用Java,甚至是 Kryo序列化)空间。而因为Tungsten并不依赖于Java对象,所以堆内、堆外的内存分配均是支持的。Tungsten除了存储格式更紧凑外,相对于原生序列化,Tungsten序列化的时间也会更快。
需要注意的是,因为Tungsten不再依赖于Java 对象而工作,所以我们可以使用on-heap(in the JVM)或是 off-heap 存储。如果使用off-heap存储,则需要给container足够的空间用于off-heap的分配。这个可以通过web UI获取更清晰的信息。
3.DataSets
DataSets 是SparkSQL的一个扩展,提供了额外的编译-时间类型检查(compile-time type checking)。在Spark 2.0之后,DataFrames成为Datasets的一个特殊的版本,用于处理通用Row对象,且不包含Datasets的常规编译-时间类型检查。
从代码上看,DataSets与DataFrames的关系为:
type DataFrame = Dataset[Row]
在不同使用场景中,使用DataSets而不使用DataFrames 的其中一个原因有:DataFrames 有runtime schema information,但是缺少compile-time information about schema。
DataSets提供了类似RDD的变换,例如:
def funMap(ds: Dataset[RawPanda]): Dataset[Double] = {
ds.map{rp => rp.attributes.filter(_ > 0).sum}
}
更多有关DataSets的使用方法不在此详述。
3. Query Optimizer
Catalyst 是Spark SQL 查询优化器,它接收一个query plan,将它转换为一个Spark可以执行的execution plan。正如根据RDDs的transformation 构造一个DAG 一样,我们在DataFrames/Datasets 应用的relational and functional transformations 会被Spark SQL 用于构建一个query plan的树,成为logical plan。Spark可以在logical plan上应用一些优化,并使用cost-based 模型为同一个logical plan对应的多个physical plan中做选择。
Logical and Physical Plans
根据DataFrames/Datasets(或SQL queries)上应用的transformations,会先构造一个未解析的(unresolved)logical plan。Spark optimizer 的运行分为多个阶段,它需要先解析references、以及表达式的类型,然后再执行优化。
解析后的plan称为logical plan,Spark在logical plan上直接应用一系列的简化操作,产生一个优化的(optimized)logical plan。
在logical plan被优化后,Spark会产生一个physical plan。Physical plan阶段会使用rule-based和cost-based 优化,产生一个最优的physical plan。这个阶段中最重要的优化之一是谓词下推(predicate pushdown)到数据源层。
代码生成
作为最后一步,Spark可能为组件应用代码生成(apply code generation)。代码生成由Janino编译Java代码完成。早期版本使用Scala的Quasi Quotes,但是此方法为小数据集启用code generation时会产生很高的负载。在一些TPCDS queries中,code generation 可以提升10倍以上的性能。
Large Query Plans 与迭代算法
Catalyst 已经相当强大了,但在一些场景中仍会有些挑战,其中之一就是超大型的query plans。这些query plans一般是迭代算法产生,例如图算法或是机器学习算法。对此,一个简单的解决方案是将数据转回RDD,然后在每轮迭代后转回DataFrame/DataSet,如:
val rdd = df.rdd
rdd.cache()
sqlCtx.createDataFrame(rdd, df.schema)
假设即使你用的是python,也尽量确保使用底层的Java RDD以提升性能。
使用DataFrame 迭代算法会导致query plan 生成较慢的问题是一个已知issue,apache jira链接如下:
https://issues.apache.org/jira/browse/SPARK-13346
References:
[1] Holden Karau and Rachel Warren, High Performance Spark, 2019

 浙公网安备 33010602011771号
浙公网安备 33010602011771号