Spark入门级小玩
·背景
随着周边吐槽hadoop的声音渐渐多起来之后,spark也逐渐进入了大家的视野。之前,笔者有粗略的写过一篇spark的安装和性能比较[http://www.cnblogs.com/zacard-orc/p/3526007.html],加上这两天重读着大学时候的一些基础书籍,感觉IT领域大局势就像DNA的结构一样。百家齐鸣却又万象归一,就像APP与H5的战争一样,内存计算及磁盘计算在各领风骚数十年后,可能渐渐也有了一丝明朗的阳光,同时也给了一次屌丝走向高富帅的机会。这次再写一篇,不做枯燥理论的复制粘贴,就把这几天工作上碰到的一些内容更形象地与SPARK贴合起来。由于之前接触python不多,花了一天时间在上面,终于喝了两口python的汤,也正好切好本文的角度,已一个局外人的视角来解析spark的方便。写的不好之处,请拍~。
·Spark里的常用名字
pySpark.SparkContext:字面理解spark专属的上下文,承上启下。更形象的说,就像你的一份简历,上面有很多的字段(属性),方便你来告诉spark这次的 任务你想干什么。如果你忘了一些设置,或者想个性化一些设置,可以再从pySpark.conf中重新进行设定。
pySpark.SparkContext.textFile:知道了任务,总要告诉Spark你具体要处理的对象。对大多数人来说,读文件是绕不开的一些。这个函数就是读取文件的神器。虽然现在的pyspark还不支持streaming,但是预计时间上也是迟早的事。
RDD:字面理解,弹性数据集合。再粗俗点,大家把日志读到"内存",这个内存形式的会比较怪异。见下图,它可能存在的多种形式。

Partition:在一些常见的PPT介绍中,每个人对其的理解也有很大的差别,有的认为,RDD是PARTITION的一部分,多个RDD组成PARTITION。也有认为PARTITION是RDD的一部分。这个只能说,E文单词有时候还真的挺隐晦。从官网API的mapPartition上看,笔者觉得Spark更推荐上图3的使用形式。但是,有了Yarn之后,Spark立马从张辽变成了张飞。
Map+Reduce:OK。数据有了存在的形式,接下来干嘛。那就是自己改刀。在此需要提醒的时,在pyspark提示符号下,作为刚接触的同学可以多敲敲type。敲完之后,便一目了然。

spark 提供了很多API供大家发挥,唯独???需要从python中自己打造,有时候神和人的区别也许就在那???中能找到答案。PS:笔者是人。
Shared Variables:MR这就走完了,但是Spark除了内存和并行计算是主打卖点外,还有一件事情是他的卖点,就是共享变量,其重要性无论在哪种语言的API中都位于一级目录。这个还真是方便,在有些MR的任务中,往往要插入第三方数据或者乱入的数据。之前hadoop streaming 可以有conf参数提供,但是是静态,如果像中途变更,就是重启服务。正是这种情况下,Shared Variables中的broadcast发挥了强大的功能,能写能读,方便灵活,类同范围攻击。官网介绍它时,说他可以放LARGE DATA而且还能用Spark自己的算法最快地发布到每个Worker上。由于笔者未读源码,只是抓包看了一下,不是UDP的组播。另外还有一个变量叫Accumulators,这个能读不能写,字面义是"累加器",官网也是这么演示,但是笔者更看重它的另外一层E文翻译"蓄水池",除传统累加外,还能做一些MR过程中的临时统计,但又不输出到RDD结果。
·Spark入门演示
这次的演示不从官网角度出发,不从复制粘贴开始,就从最实际的工作切入。举个栗子,要基础的运维统计,统计每行日志中哪些耗时超过5100毫秒的操作记录。然后我们一步一步来。日志的样本如下所示,为了文章的效果,只显示5行,并且已经放到了hdfs://cent8:9000/input的目录下

先进入pyspark目录
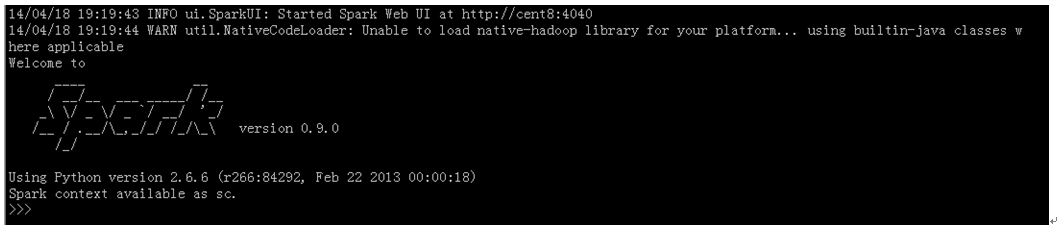
由于pyspark启动时默认加载了spark许多类库,所以原本写在脚本中的import xxx from sparkxxx都可以省略
先试着打开文件,很EAYS,打开的同时就已经分布式地加载到了内存中,此时words就是RDD类。
words = sc.textFile("/input/2.txt")

看下words里面是什么,words.collect(),而且它返回了一个列表。

知道它是一个列表后,python同学的发挥空间就打开了,接下来我们继续。把日志明细拆开,这里会开启MAP,当然不开也可以。
def f(x):
a=x.split(' ')
b=a[8].split(':')
return int(b[0])
words.map(f).collect()

一样的拆完之后,它返回了一个列表,我们稍加改动一下,把耗时大于5100的记录展示出来,它就变成了。
def f(x):
a=x.split(' ')
b=a[8].split(':')
if(int(b[0])>5100):
print x
return x
words.map(f).collect()
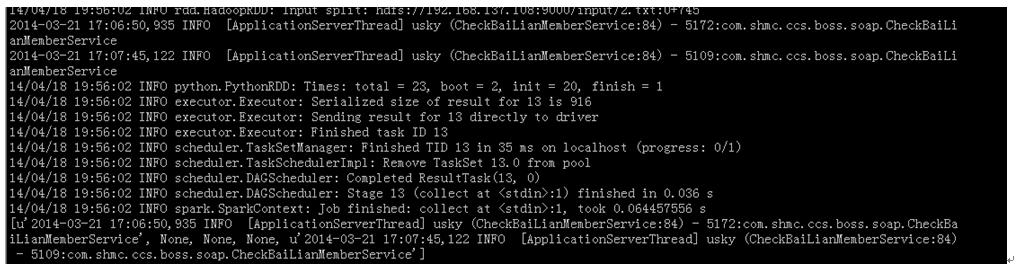
找日志的活就结束了,前面我们还说到了一个broadcast变量,官网给的例子太短了,让人理解困难。我来把它重新改造一下。
bv = sc.broadcast([13,23,33]) 设置了broadcast,然后就可以在自定义函数中自己饮用了。
def f(x):
a=x.split(' ')
b=a[8].split(':')
if(int(b[0])>5100):
print x
return int(b[0])+int(bv.value[2])
words.map(f).collect()

我们把BV的值再改一次改成[100,200,300]看会发生什么

OK,这次为此,Spark应用大门就此彻底打开了。当然这个spark的世界很大很大,包括很多屌丝逆袭高富帅的ML类,此文仅仅沧海一藕。如果想深入进去,涉及的知识面可谓覆盖了几乎整个时下流行的计算机体系的边边角角。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号