监督学习方法
学习资料:《统计学习方法 第二版》、《机器学习实战》、吴恩达机器学习课程
一. 感知机Proceptron
-
感知机是根据输入实例的特征向量\(x\)对其进行二类分类的线性分类模型:\(f(x)=\operatorname{sign}(w \cdot x+b)\),感知机模型对应于输入空间(特征空间)中的分离超平面\(w \cdot x+b=0\)。
-
感知机学习的策略是极小化损失函数:\(\min _{w, b} L(w, b)=-\sum_{x_{i} \in M} ;y_{i}\left(w \cdot x_{i}+b\right)\);
损失函数对应于误分类点到分离超平面的总距离。 -
感知机学习算法是基于随机梯度下降法的对损失函数的最优化算法。对于所有误分类的点,计算这些点到超平面的距离,目的是最小化这些点到平面的距离。
当训练数据集线性可分时,感知机学习算法存在无穷多个解,其解由于不同的初值或不同的迭代顺序而可能有所不同。
二. K近邻算法
-
K-近邻算法是一种没有显示学习过程的算法。数据集的可代表性就很重要!
-
K-近邻原理:把数据集和输入实例点都映射到空间内,对给定的输入实例点,首先确定输入实例点的𝑘个最近邻训练实例点,这𝑘个训练实例点的类的多数就是预测的输入实例点的类。
-
K-近邻算法的核心要素是K的值、距离度量(一般为欧式距离)、分类决策规则(一般是多数表决)。当训练集和核心要素确定时,其结果确定。
-
\(k\)值小时,\(k\)近邻模型更复杂;𝑘值大时,𝑘近邻模型更简单。
三. 朴素贝叶斯
1. 数学公式
朴素的意思是所有特征相互独立且同等重要。就说明
贝叶斯定理:
得到朴素贝叶斯法的模型:
2. 三种常用的朴素贝叶斯模型
- 高斯模型 当特征是连续变量时使用,假设特征符合高斯分布
- 多项式模型 当特征是离散值使用
多项式模型在计算先验概率\(P(y_k)P(y_k)\)和条件概率\(P(x_i|y_k)P(x_i|y_k)\)时,会做一些平滑处理。

- 伯努利模型 当特征是离散值且是二值离散时使用
四. 决策树
决策树是基于特征对实例进行分类的树形结构。包括三大步骤:特征的选择、决策树的生成、决策树的剪枝。
1. 特征的选择
熵
信息论(information theory)中的熵(香农熵)的定义:随机变量不确定性的度量。
熵是一种信息的度量方式,表示信息的混乱程度,也就是说:信息越有序,信息熵越低。例如:火柴有序放在火柴盒里,熵值很低,相反,熵值很高。熵越大,随机变量的不确定性就越大。
信息增益
信息增益的定义:熵之差。在这里表示的是得知特征X后使得类Y划分不确定度减少的程度。
选择特征的方法是:计算每个特征对于训练集的信息增益。选择信息增益最大的特征,即分类能力强的特征。
信息增益比
用信息增益来选择特征易选择取值较多的特征,信息增益比在信息增益的基础之上乘上一个惩罚参数:特征个数较多时,惩罚参数较小,信息增益比也变小;特征个数较少时,惩罚参数较大,信息增益比随之增大。
信息增益比偏向于选择取值较少的特征。
基尼指数
基尼指数(基尼不纯度)表示在样本集合中一个随机选中的样本被分错的概率,即指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。
2. 决策树的生成
对于当前数据集的每一次的划分,都希望根据某特征划分之后的各个子集的纯度更高,不确定性更小。
ID3算法
用信息增益从大到小选择特征,根据特征的取值将训练集分为相应子集,形成对应子结点,每个子结点中的训练子集中数量最多的类作为该结点的类标记,然后递归构建决策树。
C4.5算法
用信息增益比从大到小选择特征,递归构建决策树。
CART算法
CART是个二叉树,也就是当使用某个特征划分样本集合时,不管这个特征有几个取值,划分时都只有两个集合:一个是等于给定的特征值的样本集合D1 。另一个是不等于给定的特征值的样本集合D,实际上是对拥有多个取值的特征的二值处理。
因而对于一个具有多个取值(超过2个)的特征,需要计算以每一个取值作为划分点,对样本D划分之后子集的纯度Gini(D,Ai),(其中Ai 表示特征A的可能取值),然后从所有的可能划分的Gini(D,Ai)中找出Gini指数最小的划分,这个划分的划分点,便是使用特征A对样本集合D进行划分的最佳划分点。
3. 决策树的剪枝
- 简化决策树,防止过拟合;
- 合并无法产生大量信息增益的叶结点,消除过度匹配的问题;
- 通过优化损失函数,减小决策树复杂度。
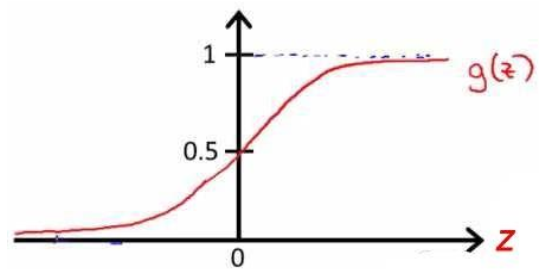
五. logistic回归
logistic回归是一种二分类算法
1. 表达式和函数图像

2. cost function


3. 梯度下降

六. SVM
Support Vector(支持向量):就是离超平面最近的点
SVM是线性分类算法,与感知机不同的是,SVM的原理是不仅仅要成功做到线性可分,还要找最大间隔largest margin——就是支持向量离超平面最近的距离,然后最大化这个距离。进而转化为最优化问题——最优化距离。
1. 松弛变量
之前的模型噪声对非常敏感。如果数据集存在噪音,会导致最终超平面的选择不够好,甚至造成线性不可分的情况。在优化目标函数上加上松弛变量就类似于正则化变量一样,允许离群点的存在,但是会对离群点有所惩罚。寻找最优最大间隔与考虑离群点的存在之间的平衡就成了优化目标。
2. 核函数
SVM是线性分类算法。对于非线性可分的数据集,可以利用核函数将数据映射到高维空间,从而把低纬线性不可分数据转为高纬度线性可分数据,然后再用SVM。
七. 集成方法
bagging、boosting都是集成多个分类器的方法。
1. bagging
把训练集进行随机放回抽样,抽取出与原训练集数量相同的新数据集,总共生成多个样本数量相同的新训练集。利用同一个学习算法对这几个训练集训练,形成多个分类器。之后预测新实例时用多个分类器同时进行预测,选择最多的分类类别作为结果。
最常用的方法:随机森林
2. boosting
只用原始数据集,但对里面每个样本赋予权重,先后用同种弱分类器训练数据集,每个弱分类器训练结束得到由分类正确率计算出来的alpha值,再通过这个值更新样本权重。预测新实例时是将每个弱分类器预测结果乘alpha值线性相加得到。
最常用的方法:Adaboost
八. 分类
分类问题可以分为二分类问题、多分类问题、多标签分类问题和多输出分类
二分类:一个样本只有一个标签且只可能是0或者1;
多分类:一个样本只有一个标签但标签结果为多个;
多标签:一个样本有多个标签,但每个标签的值是0或1;
多输出:一个样本有多个标签且每个标签的值为多个。
如何解决多分类的问题
-
一些算法(比如随机森林分类器或者朴素贝叶斯分类器)可以直接处理多类分类问题。
-
其他一些算法(比如 SVM 分类器或者线性分类器)则是严格的二分类器。但是,用一些策略可以让二分类器去执行多类分类。
- OvA n个类需要n个分类器:每一个类对应一个二分类器,输出是或否。优点是分类器较少,缺点是每个分类器需要训练所有数据。
- OvO n个类需要
n(n-1)/2个分类器:每两个类组成一个二分类器,输出两个类中的一个。优点是每个分类器只需要在训练集的部分数据上面进行训练,这部分数据是它所需要区分的那两个类对应的数据。缺点是分类器较多。(SVM适合OvO)
九. 线性回归
线性回归模型中将cost function最小化除了用梯度下降还可以用正规方程。正规方程法不需要学习率,不需要特征缩放,可以直接一次计算出:

只要特征变量的数目并不大,标准方程是一个很好的计算参数的替代方法。具体地说,只要特征变量数量小于一万,通常使用标准方程法,而不使用梯度下降法。
注意:有些时候对于某些模型不能使用正规方程而只能用梯度下降。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号