

6.5用二叉树实现哈夫曼编码
哈夫曼算法是指,为各压缩对象文件分别构造最佳的编码体系,并以该编码体系为基础来进行压缩。因此,用什么样式的编码(哈夫曼编码)对数据进行分割,就要由各个文件而定。
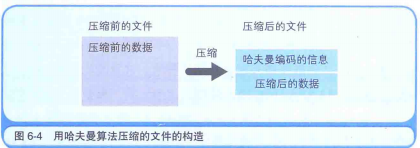
用哈夫曼算法压缩过的文件中,存储着哈夫曼编码信息和压缩过的数据,如下图。
接下来,我们尝试一下把 AAAAAABBCDDEEEEEF 中的A~F这些字符,按照“出现频率高的字符用尽量少的位数编码来表示”这一原则进行整理。按照出现频率从高到低的顺序整理后,结果就如表 6-3 所示。该表中同时也列出了编码的方案。

在表 6-3 的编码(方案)中,随着出现频率的降低,字符编码信息的数据位数也在逐渐增加,从开始的 1 位、2位,依次增加到 3 位。不过,这个编码体系是存在问题的。该问题就是,例如 100 这个3 位的编码,它的意思是用1、0、0这3个编码来表示 E、A、A 呢? 还是用10、0这两个编码来表示 B、A 呢?亦或是用100 来表示C呢?这些都无法进行区分。因此,如果不加人用来区分字符的符号,这个编码方案)就无法使用。
而在哈夫曼算法中,通过借助哈夫曼树构造编码体系,即使在不使用字符区分符号的情况下,也可以构建能够明确进行区分的编码体系。也就是说,利用哈夫曼树后,就算表示各字符的数据位数不同也能够做成可以明确区分的编码。因此,只要掌握了哈夫曼树的制作方法,并用程序将其完成,就可以借助哈夫曼算法实现文件压缩了不过,与 RLE 算法相比,程序的内容要复杂很多。
接下来我们就来看一下如何制作哈夫曼树。自然界的树是从根开始生枝长叶的。而哈夫曼树则是从叶生枝,然后再生根。图 6-5 展示了对AAAAAABBCDDEEEEEF 进行编码的哈夫曼树的制作过程。大家也尝试绘制一下吧。尝试过 1次后,应该就能理解哈夫曼树的制作顺序了。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号