

6.3RLE算法的缺点
RLE不适合文本文件的压缩。
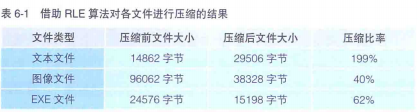
通过表 6-1 可以看出,使用 RLE 算法对文本文件进行压缩后,文件却增大了,而且几乎是压缩前的 2倍。这是因为文本文件中同样字符连续出现的部分并不多。以存储着“This is a pen.”这 14 个字符的文本文件为例,使用 RLE 算法对其进行压缩后,就变成了“T1hlils1 lils1lal 1pleln1.1”这样的 28 个字符,是压缩前的 2倍。由于文章中字符大量连续出现的情况并不多见,因此,使用 RLE 算法后,大部分字符后面都会加上1,这样一来,压缩后的文件自然变成了之前的 2 倍。
与文本文件不同,图像文件的压缩比率”达到了 40%。程序的 EXE文件的压缩比率也达到了 60%,这是因为 EXE 文件中连续的数据部分,其初始值为 0的情况很多。
此外,我们也可以在 RLE 算法的基础上再下点功夫,不以 1 个字符为单位,而以字符串为单位来查找重复次数。例如,This is a pen.中,is 重复了两次。通过利用这个压缩技巧,压缩后的文件也能小一些。由此可见,压缩技巧的拙劣是由所花的功夫决定的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号