

论文笔记 Stacked Hourglass Networks for Human Pose Estimation
Stacked Hourglass Networks for Human Pose Estimation
key words:
人体姿态估计 Human Pose Estimation 给定单张RGB图像,输出人体某些关键点的精确像素位置.
堆叠式沙漏网络 Stacked Hourglass Networks
多尺度特征 Features processed across all scales
特征用于捕捉人体的空间关系 Capture spatial relationships associated with body
中间监督 Intermediate supervision
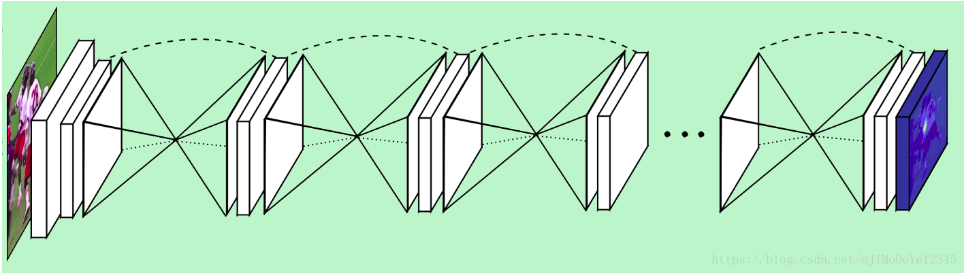
图 - Stacked Hourglass Networks由多个 stacked hourglass 模块组成,通过重复进行bottom-up, top-down推断以估计人体姿态.
沙漏设计 Hourglass Design
动机:捕捉不同尺度下图片所包含的信息.
局部信息,对于比如脸部、手部等等特征很有必要,而最终的姿态估计需要对整体人体一致理解. 不同尺度下,可能包含了很多有用信息,比如人体的方位、肢体的动作、相邻关节点的关系等等.
Hourglass设计:
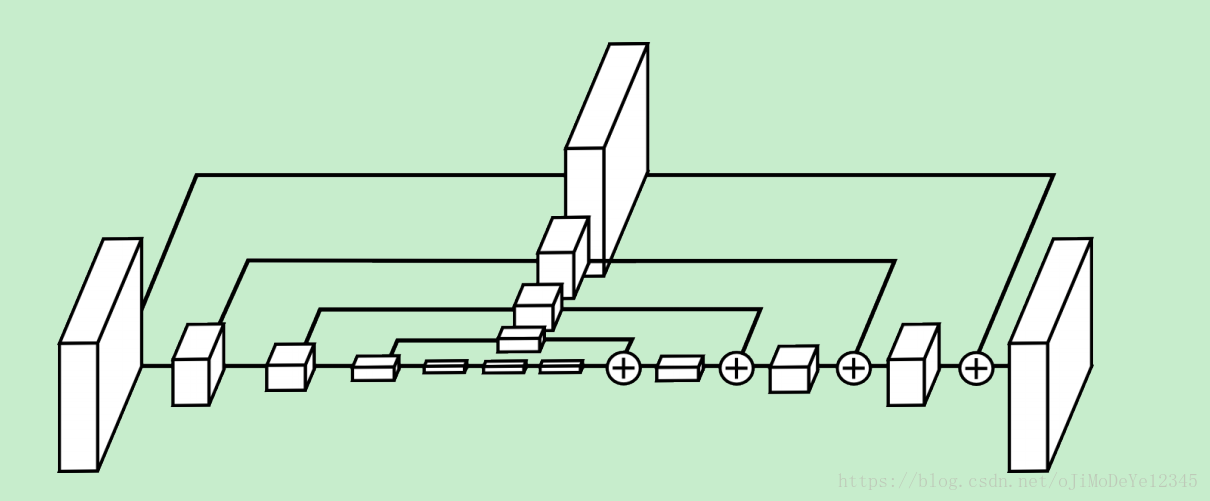
图 - 单个hourglass模块示例. 图中个方框分别对应一个residual模块. 整个hourglass中,特征数是一致的.
hourglass设置:
首先Conv层和Max Pooling层用于将特征缩放到很小的分辨率;
每一个Max Pooling(降采样)处,网络进行分叉,并对原来pre-pooled分辨率的特征进行卷积;
得到最低分辨率特征后,网络开始进行upsampling,并逐渐结合不同尺度的特征信息. 这里对较低分辨率采用的是最近邻上采样(nearest neighbor upsampling)方式,将两个不同的特征集进行逐元素相加.
整个hourglass是对称的,获取低分辨率特征过程中每有一个网络层,则在上采样的过程中相应低就会有一个对应网络层.
得到hourglass网络模块输出后,再采用两个连续的 1×1 Conv层进行处理,得到最终的网络输出.
Stacked Hourglass Networks输出heatmaps的集合,每一个heatmap表征了关节点在每个像素点存在的概率.
Residual模块提取了较高层次的特征(卷积路),同时保留了原有层次的信息(跳级路)。不改变数据尺寸,只改变数据深度。可以把它看做一个保尺寸的高级“卷积”层。
中间监督 Intermediate Supervision
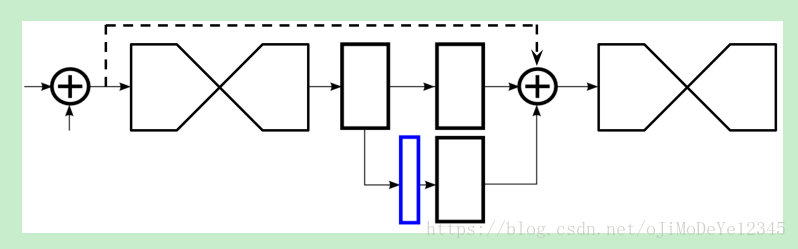
Hourglass网络输出heatmaps集合(蓝色方框部分),与真值进行误差计算。 其中利用1×1的Conv层对heatmaps进行处理并将其添加回特征空间中,作为下一个hourglass model的输入特征。每一个Hourglass网络都添加Loss层.Intermediate Supervision的作用在[2]中提到:如果直接对整个网络进行梯度下降,输出层的误差经过多层反向传播会大幅减小,即发生vanishing gradients现象。
为解决此问题,[2]在每个阶段的输出上都计算损失。这种方法称为intermediate supervision,可以保证底层参数正常更新。
堆栈沙漏与中级监督 Stack Hourglass with Intermediate Supervision
正如本文开头所示,网络的核心结构为堆叠多个hourglass model,这为网络提供了重复自下而上,自上而下推理的机制,允许重新评估整个图像的初始估计和特征。实现这一过程的核心便是预测中级热度图并让中级热度图参与loss计算。
如果对单一的Hourglass Model进行Intermediate Supervision,监督放在哪个位置比较合适呢?如果在网络进行上采样后提供监督,那么在更大的全球堆叠沙漏网络人类姿势估计上下文中,无法相对于彼此重新评估这些特征;如果在上采样之前监督,此时,给定像素处的特征是处理相对局部感受野的结果,因此不知道关键的全局线索。本文提供的解决方式是repeated bottom-up,top-down inference with Stacked hourglass(图解在本文文首),通过该方式, the network can maintain precise local information while considering and then reconsidering the overall coherence of the features。
Reference:
[1] https://blog.csdn.net/shenxiaolu1984/article/details/51094959
[2] Wei, S.E., Ramakrishna, V., Kanade, T., Sheikh, Y.: Convolutional pose machines. Computer Vision and Pattern Recognition (CVPR), 2016 IEEE Conference on (2016)
[3] https://blog.csdn.net/zziahgf/article/details/72732220

 浙公网安备 33010602011771号
浙公网安备 33010602011771号