一次OB事务锁阻塞造成应用线程阻塞的案例
故障场景
xxx系统应用告警:应用线程阻塞导致CPU使用率升高,进而造成应用不可用,影响电子保单生产。
OB环境
版本:4.2.1.6
租户兼容模式:OB oracle租户
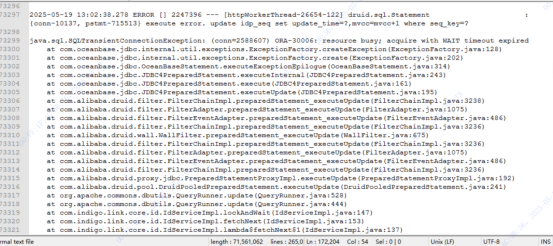
应用报错日志
排查步骤
检查参数
根据应用报错,“wait timeout expired”,怀疑SQL执行超时,被OB_query_timeout 参数强制中断执行,导致应用报错。
排查手段:通过OCP检查租户参数,默认10秒,有可能是参数造成。
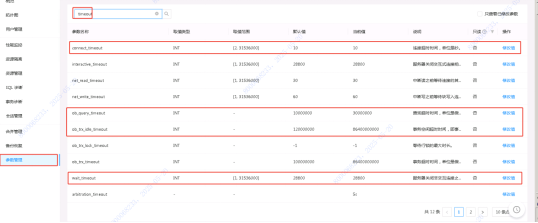
根据应用日志中报错的sql,看sql执行时间,是否会被强制中断。
排查手段:在SQL诊断页面,选取故障时间点,查找异常SQL。发现一个update 执行时间异常,点击sql下钻。
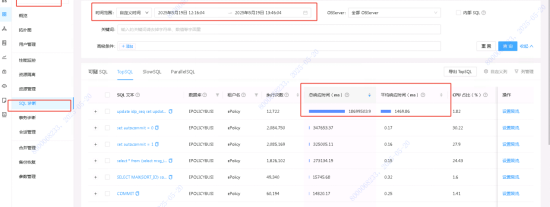
故障期间,Sql运行平均响应时间9.9秒,结合sql文本,索引信息。
结合目前信息可得出结论:Where条件是主键的一个update,运行超过10秒,超过OB_query_timeout参数设置,被OB强制中断执行,导致前端应用报错。
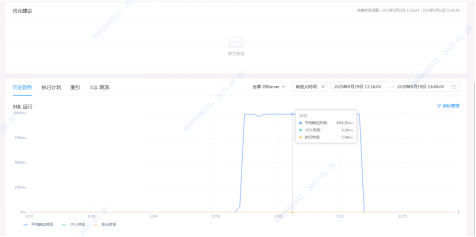
TOPSQL文本:update xxx set xx=xx where aaa=11; 其中 aaa是主键。
以上排查下来,可以得出应用日志报错的原因,是SQL执行超时,被数据库强制中断造成。应用线程增加,导致CPU满,造成应用不可用,怀疑是这个sql执行时间异常变慢,高并发下,导致应用线程阻塞。
检查sql执行计划
查看执行计划是否有变更导致SQL变慢:这里OCP无法显示执行计划信息,通过手动查询方法如下
结论:sql执行计划无变更
---查出SQL_ID
select * from gv$ob_sql_audit where query_sql like '%xxxx%';
----根据SQL_ID 查看有几个执行计划
select * from GV$OB_PLAN_CACHE_PLAN_STAT where sql_id=''\G
注意点:gv$ob_sql_audit 保留时间较短,建议CTAS及时备份故障期间的数据到临时表。
查看observer日志
通过OCP找到primary zone 所在的机器,登录堡垒机,查看observer日志,看是否有异常报错(路径/home/admin/oceanbase/log/observer.log)
日志报错:

err_:-6005, err_:"OB_TRY_LOCK_ROW_CONFLICT" 报错表示加锁加不上。
结论:因某些原因,导致update无法加锁。可能排队获取锁超时,也可能是其它原因导致无法加锁,日志里没有其余信息显示,向锁阻塞方向排查。
排查锁信息
通过OCP排查,没有长事务,没有死锁。
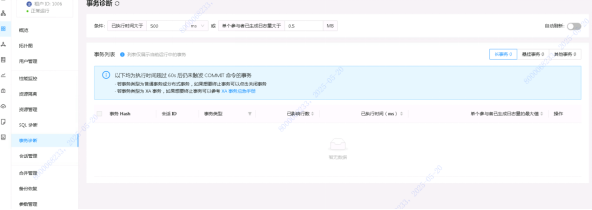
查看当前数据库中持有锁的情况
Select * from v$ob_locks;
官网对v$ob_locks个字段的解释
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000000219707
*注意:v$ob_locks为实时锁信息,只有在故障期间才可以查到
故障原因总结
因tx锁,导致update被阻塞,阻塞时间达到ob_query_timeout参数设置时间,被OB强制kill,应用打印wait timeout报错日志。
因高并发锁阻塞导致应用线程堆积,cpu空转造成CPU告警,应用hang死。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号