
07-Spark之RDD
一:分布式程序的设计思想
- step1:读取数据Input
- 代码中:要指定读取数据文件的位置,然后返回一个代表这个输入数据的变量
- 将要处理的数据拆分成N份,每一份数据放在不同机器上
- 相当于接一个大活,干活的是很多人一起干活,将一个大的任务拆分成很多小任务给每个人分
- step2:处理数据Transform
- 代码中:定义Input的数据变量怎么进行转换,返回一个代表结果数据的变量
- 启动N个计算任务Task,每个计算任务Task根据处理逻辑去处理每一份数据
- 每个计算Task都会计算得到一个结果
- step3:保存结果Save
- 代码中:将代表结果数据的变量进行输出或者保存到外部系统中
- 启动Task将每台机器的数据进行输出或者写入外部系统
二:RDD的设计及定义
- 本质:一个抽象的逻辑上的数据集合的概念,类似于Python中的list,但RDD是分布式的
- Python中的list:数据只存在于list构建的节点
- Spark中的RDD:数据是分布式存储在多台节点上的
- 功能:实现分布式的数据存储,是一个对应多个物理分区的数据集合,每个分区的数据可以存储在不同的节点上
- RDD本质上是一个逻辑的概念,代表多台机器上的多个分区的数据
- RDD就类似于HDFS中的文件,RDD的分区就类似于HDFS中的Block块
实现
- step1:SparkCore中所有的数据读取到程序中以后都会存储在一个RDD中,将数据划分到多个分区中
- step2:所有的数据转换处理,都直接在代码中对RDD进行处理,底层会对RDD的每个分区进行并行处理
![]()
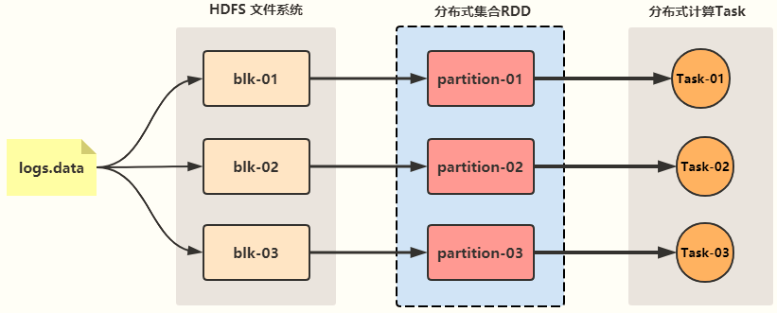
三:RDD的五大特性
- 特性一:每个RDD都由一系列的分区构成
- 特性二:RDD的计算操作本质上是对RDD每个分区的计算
- 特性三:每个RDD都会保存与其他RDD之间的依赖关系:血链或者血脉
- 特性四:可选的,如果是二元组【KV】类型的RDD,在Shuffle过程中可以自定义分区器
- 特性五:可选的,Spark程序运行时,Task的分配可以指定实现最优路径解:最优计算位置
-
思想:移动存储不如移动计算:计算过程中避免了大量数据在网络中传输,影响性能
-
Driver分配Task给Executor运行,怎么分配性能最好?
- 尽量将Task分配到对应处理的数据所在的节点的Executor中运行
- https://spark.apache.org/docs/latest/tuning.html#data-locality
- PROCESS_LOCAL:Task直接运行在数据所在的Executor中
- NODE_LOCAL:Task分配在与数据同机器的其他Executor中
- RACK_LOCAL:Task分配在于数据同机架的不同机器的Executor中
- NO_PREF:不做最优配置
-
四:RDD的缺陷是什么?
- RDD不支持细粒度的操作,不支持行级操作
- RDD不支持增量迭代操作,RDD本身是为了离线批处理设计的
五:RDD的弹性表现在哪几点?
- 弹性:允许用户在性能和安全性之间自由灵活的选择,所有Task都可以基于容错机制恢复
- 容错机制:血脉机制,如果RDD中分区的数据丢失,可以重新根据依赖关系重新构建RDD
- 缓存机制:persist/cache/unpersist:允许用户将RDD进行缓存
- 检查点机制:checkpoint:允许用户将RDD的数据放入HDFS可靠的系统中
六:Spark的算子分为几类?
- 转换算子:定义RDD的转换过程,一般是Lazy模式,一般不会触发job,返回一定是RDD
- 触发算子:将RDD数据返回给用户,一定会触发job,构建Task的运行,返回值一定不是RDD
七:Spark的常用算子有哪些?
- 常用触发算子:count、first、foreach、foreachPartition、saveAsTextFile、take、collect、reduce……
- 常用转换算子:map、flatMap、filter、xxxxByKey、join、union、distinct、repartition……
- 面试: 算子区别和场景(得自己理解找答案)
- repartition、coalesce区别和应用场景
- persist、cache、checkpoint区别和应用场景
- sortBy、sortByKey、top、takeOrdered区别和应用场景
- map、mapPartitions、foreach、foreachPartition区别和应用场景
- groupByKey、reduceByKey区别和应用场景

 浙公网安备 33010602011771号
浙公网安备 33010602011771号