
第二周:卷积神经网络 part 1
第二周:卷积神经网络 part 1
视频学习
数学基础
受结构限制严重,生成式模型效果往往不如判别式模型。
RBM:数学上很漂亮,且有统计物理学支撑,但主流深度学习平台不支持RBM和预训练。
自编码器:正则自编码器、稀疏自编码器、去噪自编码器和变分自编码器。
- 概率/函数形式统一:
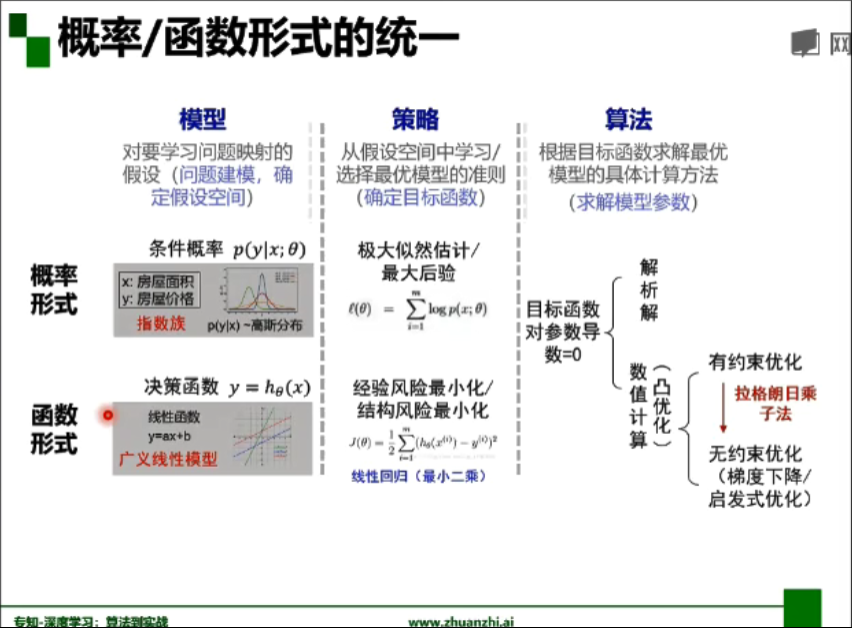
-
欠拟合、过拟合解决方案:
- 欠拟合:提高模型复杂度
- 决策树:拓展分支
- 神经网络:增加训练轮数
- 过拟合1:降低模型复杂度
- 优化目标加正则项
- 决策树:剪枝
- 神经网络:early stop、dropout
- 过拟合2:数据增广(训练集越大,越不容易过拟合)
- 计算机视觉:图像旋转、缩放、剪切
- 自然语言处理:同义词替换
- 语音识别:添加随机噪声
- 欠拟合:提高模型复杂度
-
交叉熵与对数损失函数关系:如果把所有样本取均值就把交叉熵转化成了对数损失函数。
平方损失函数假设高斯分布,而分类问题是二项/多项分布,对数损失与二项/多项分布下的最大似然等价。
- 频率学派:参数估计只依赖观测数据
- 贝叶斯学派:参数估计同时依赖观测数据和先验知识
卷积神经网络CNN
-
基本应用:分类、检索、检测、分割、人脸识别、图像生成、风格转化、自动驾驶
-
深度学习三部曲:搭建神经网络、损失函数、优化函数
-
全连接网络处理图像问题:参数太多:权重矩阵的参数太多 -> 过拟合
-
卷积神经网络的解决方法:局部关联,参数共享
-
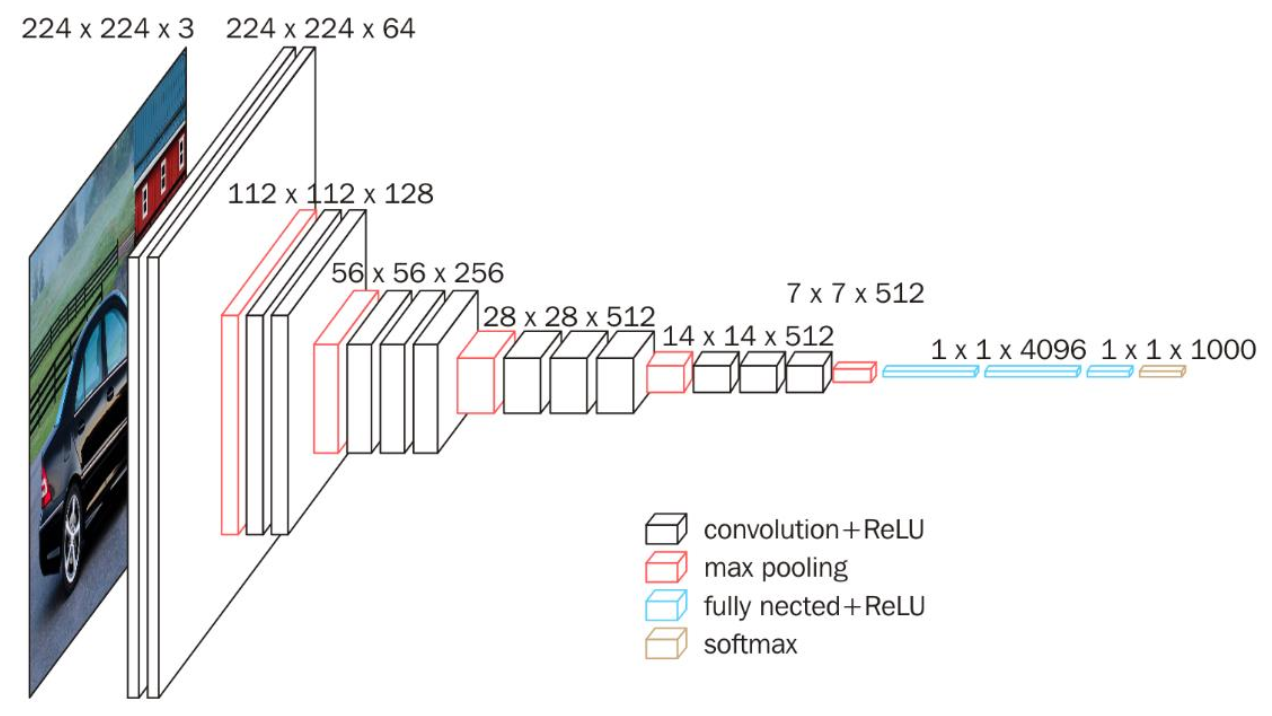
CNN组成:CONV layer卷积层、RELU layer激活层、POOL layer池化层、FC layer全连接层
-
卷积操作:
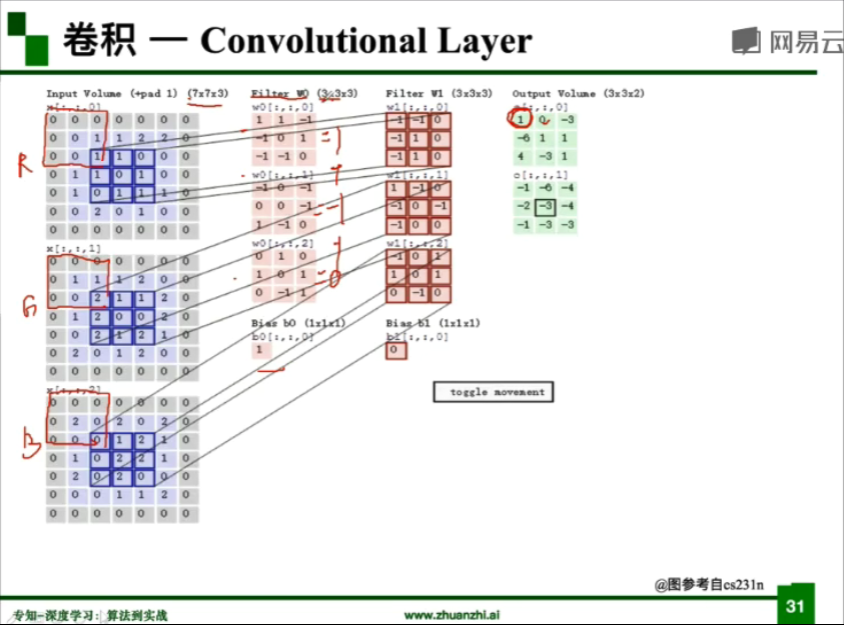
kernel/filter:卷积核/滤波器
stride:步长
weights:权重
receptive field:感受野
activation map 或 feature map:特征图
padding :填充
depth/channel:深度/通道
-
特征图大小计算公式:(N-F+padding*2)/stride+1,输入为N×N,卷积核为F×F
-
参数量:(卷积核大小5×5+偏置1)×个数
-
池化(pooling):保留了主要特征的同时减少了参数和计算量,防止过拟合,提高模型泛化能力
- Max pooling:最大值池化
- Average pooling:平均值池化
ps:池化层无参数,且不改变通道个数
缩小图像(或称为下采样(subsampled)或降采样(downsampled))
原理:对于一幅图像I尺寸为MN,对其进行s倍下采样,即得到(M/s)(N/s)尺寸的得分辨率图像,当然s应该是M和N的公约数才行,如果考虑的是矩阵形式的图像,就是把原始图像s*s窗口内的图像变成一个像素,这个像素点的值就是窗口内所有像素的均值。
目的:1.使得图像符合显示区域的大小。2.生成对应图像的缩略图。
放大图像(或称为上采样(upsampling)或图像插值(interpolating))
原理:图像放大几乎都是采用内插值方法,即在原有图像像素的基础上在像素点之间采用合适的插值算法插入新的元素。
目的:放大原图像,从而可以显示在更高分辨率的显示设备上。
-
全连接(Fully Connected):
- 两层之间的所有神经元都有权重链接
- 通常全连接层在卷积神经网络尾部
- 全连接层参数量通常最大
-
卷积神经网络典型结构:
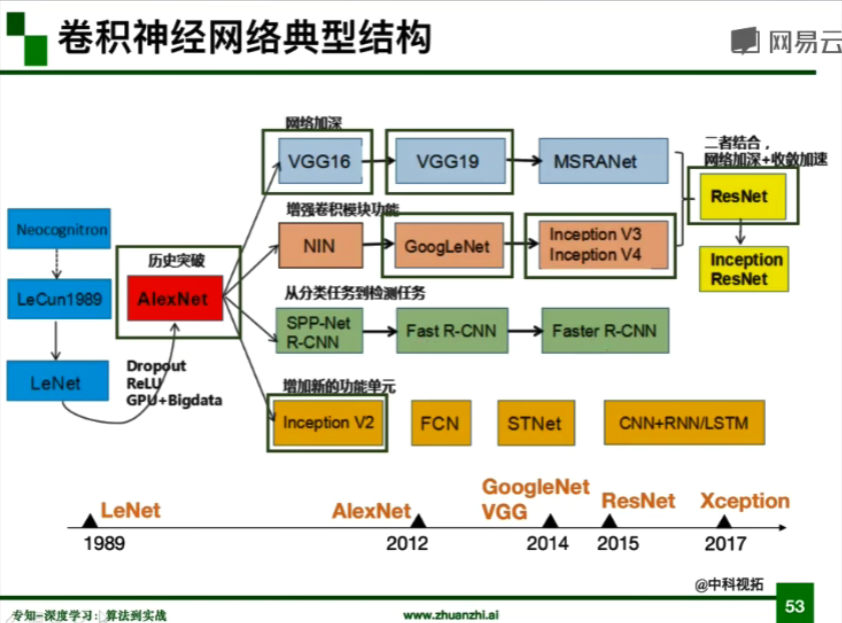
- AlexNet
- ILSVRC2012冠军,错误率下降十个百分点,深度学习转折点
- 大数据训练:百万级ImageNet图像数据
- 非线性激活函数:ReLU
- 解决了梯度消失问题(在正区间)
- 计算速度特别快,只需要判断输入是否大于0
- 收敛速度远快于Sigmoid
- 防止过拟合1:Dropout(随机失活)
- 训练时随机关闭部分神经元,测试时整合所有神经元
- 防止过拟合2:Data augmentation(数据增强)
- 平移、翻转、对称
- 随机crop。训练的时候,对于256×256的图片进行随机crop到224×224
- 水平翻转,相当于将样本倍增
- 改变RGB通道强度
- 对RGB空间做一个高斯扰动
- 平移、翻转、对称
- 其他:双GPU实现
ps:Dropout训练时为0.5,测试时设置0
-
ZFNet
- ILSVRC2013冠军,14.8%
- 网络结构与AlexNet相同
- 提取更详细信息:将卷积层1中的感受野大小由11×11改为7×7,步长由4改为2
- 卷积层3、4、5中的滤波器个数由384,384,256改为512,512,1024
-
VGG
- ILSVRC2014亚军,7.3%
- 是一个更深的网络:8 layers(AlexNet) -> 16 - 19(VGG)
- 广泛用于迁移学习
因为当时没有Batch Normalization,较深网络训练的方法是先训练前面层,然后冻结前面层参数,再训练后面层。
- GoogLeNet
- ILSVRC2014冠军,6.7%
- 组成
- 卷积层池化层:卷积—池化—卷积—卷积—池化
- Inception模块:多个Inception结构堆叠
- 辅助分类器:解决过深导致梯度消失问题,作用不大,v3拿掉
- 除分类外没有额外FC层:网络很深,但参数量仅为AlexNet的1/12
- Naive Inception
- 多种卷积核增加特征多样性(conv1×1,conv3×3,conv5×5,pool3×3)
- 在深度上进行串联:padding使结果大小保持一致
- 通道非常大:计算复杂度过高
- Inception v2
- 插入1×1卷积核进行降维:减小通道数,降低参数量
- Inception v3
- 用两个3×3卷积核代替5×5卷积核:对应感受野大小一样
- 进一步对v2参数量进行降低
- 增加非线性激活函数(激活两次):使网络产生更多独立特征(disentangled feature),表征能力更强,训练更快
- 用两个3×3卷积核代替5×5卷积核:对应感受野大小一样
Inception结构最初由GoogLeNet引入,GoogLeNet叫做Inception-v1;之后引入了BatchNormalization,叫做Inception-v2;随后引入分解,叫做Inception-v3。
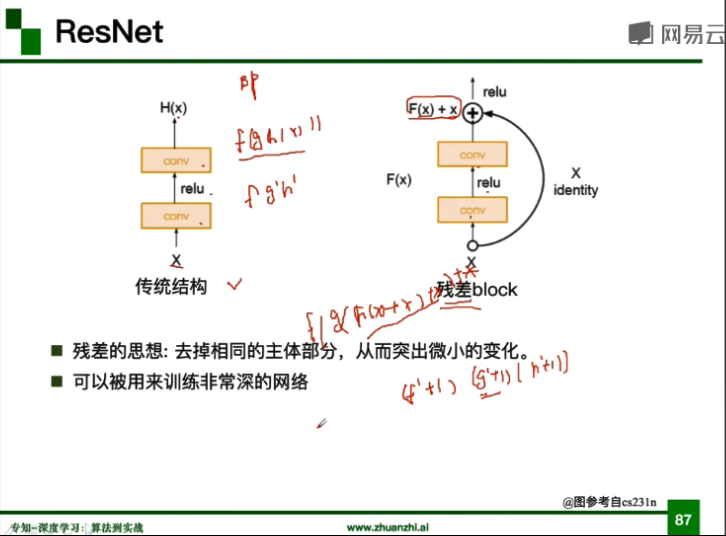
ResNet
- 残差学习网络(deep residual learning network)
- ILSVRC2015冠军,3.57%
- 深度有152层
- 除了输出层外没有其他全连接层
- 残差的思想:去掉相同的主体部分,从而突出微小的变化
- 可以被用来训练非常深的网络,不会出现梯度消失
代码练习
MNIST数据集分类
- 创建全连接网络和卷积神经网络
class FC2Layer(nn.Module):
def __init__(self, input_size, n_hidden, output_size):
# nn.Module子类的函数必须在构造函数中执行父类的构造函数
# 下式等价于nn.Module.__init__(self)
super(FC2Layer, self).__init__()
self.input_size = input_size
# 这里直接用 Sequential 就定义了网络,注意要和下面 CNN 的代码区分开
self.network = nn.Sequential(
nn.Linear(input_size, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, output_size),
nn.LogSoftmax(dim=1)
)
def forward(self, x):
# view一般出现在model类的forward函数中,用于改变输入或输出的形状
# x.view(-1, self.input_size) 的意思是多维的数据展成二维
# 代码指定二维数据的列数为 input_size=784,行数 -1 表示我们不想算,电脑会自己计算对应的数字
# 在 DataLoader 部分,我们可以看到 batch_size 是64,所以得到 x 的行数是64
# 大家可以加一行代码:print(x.cpu().numpy().shape)
# 训练过程中,就会看到 (64, 784) 的输出,和我们的预期是一致的
# forward 函数的作用是,指定网络的运行过程,这个全连接网络可能看不啥意义,
# 下面的CNN网络可以看出 forward 的作用。
x = x.view(-1, self.input_size)
return self.network(x)
class CNN(nn.Module):
def __init__(self, input_size, n_feature, output_size):
# 执行父类的构造函数,所有的网络都要这么写
super(CNN, self).__init__()
# 下面是网络里典型结构的一些定义,一般就是卷积和全连接
# 池化、ReLU一类的不用在这里定义
self.n_feature = n_feature
self.conv1 = nn.Conv2d(in_channels=1, out_channels=n_feature, kernel_size=5)
self.conv2 = nn.Conv2d(n_feature, n_feature, kernel_size=5)
self.fc1 = nn.Linear(n_feature*4*4, 50)
self.fc2 = nn.Linear(50, 10)
# 下面的 forward 函数,定义了网络的结构,按照一定顺序,把上面构建的一些结构组织起来
# 意思就是,conv1, conv2 等等的,可以多次重用
def forward(self, x, verbose=False):
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = x.view(-1, self.n_feature*4*4)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.log_softmax(x, dim=1)
return x
- 定义训练与测试函数
控制变量:全连接网络与CNN拥有相同数量的模型参数。
这里分两次进行:第一次不打乱像素顺序,第二次打乱像素顺序。

# 对每个 batch 里的数据,打乱像素顺序的函数
def perm_pixel(data, perm):
# 转化为二维矩阵
data_new = data.view(-1, 28*28)
# 打乱像素顺序
data_new = data_new[:, perm]
# 恢复为原来4维的 tensor
data_new = data_new.view(-1, 1, 28, 28)
return data_new
# 训练函数
def train_perm(model, perm):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
# 像素打乱顺序
# data = perm_pixel(data, perm)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train: [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# 测试函数
def test_perm(model, perm):
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
data, target = data.to(device), target.to(device)
# 像素打乱顺序
# data = perm_pixel(data, perm)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
accuracy))
不打乱像素顺序的情况下全连接与CNN准确率分别为88%、96%
打乱像素顺序的情况下全连接与CNN准确率分别为87%、84%
从结果来看,全连接网络的性能基本上没有发生变化,但是CNN的性能明显下降,卷积和池化就难以发挥作用。
这是因为CNN会利用像素的局部关系,但是打乱顺序以后,这些像素间的关系将无法得到利用。
CIFAR10数据集分类
PyTorch 创建了一个叫做 totchvision 的包,该包含有支持加载类似Imagenet,CIFAR10,MNIST 等公共数据集的数据加载模块 torchvision.datasets 和支持加载图像数据转换模块 torch.utils.data.DataLoader。
CIFAR-10数据集,它包含十个类别:‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’。图像尺寸为3x32x32,也就是RGB的3层颜色通道,每层通道内的尺寸为32*32。

- 训练网络
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
使用CNN训练10个epoch后在整个数据集上的表现准确率为64%
对于复杂多分类问题可以改进CNN使得性能进一步提升,具体可采用Dropout、Data Augmentation等方法,或者采用下面更强大的网络结构。
使用VGG16对CIFAR10分类
- VGG16模型
训练测试步骤同上。
使用VGG训练10个epoch后在整个数据集上的表现准确率为83%
我们发现将网络参数改小后,一个简化版的VGG仍然能够显著地将准确率从64%提升到83%。
VGG名称来源于牛津大学视觉几何组(Visual Geometry Group)的缩写。
该模型参加2014年的ImageNet图像分类与定位挑战赛,取得了优异成绩:在分类任务上排名第二,在定位任务上排名第一。
猫狗大战(VGG模型迁移学习)

在源代码基础上做了以下改进,进一步提高准确率:
-
数据增强:在数据处理的地方加入旋转
-
使用VGG19:相比VGG16网络更深,表现更优
-
采用Adam优化器,并将学习率调整为3e-4:相比SGD优化能力更强,学习率比较玄学
-
增大训练样本:使得训练结果更精确
import numpy as np
import matplotlib.pyplot as plt
import os
import torch
import torch.nn as nn
import torchvision
from torchvision import models,transforms,datasets
import time
import json
# 判断是否存在GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('Using gpu: %s ' % torch.cuda.is_available())
- 下载数据:
因为数据集文件存储结构与规范格式不一样,需要加入一些对数据的操作,这里感谢之前同学分享的方法。
! wget https://static.leiphone.com/cat_dog.rar
# 解压rar压缩包,需要安装rarfile库(pip install rarfile)
! pip install rarfile
import rarfile
path = "cat_dog.rar"
path2 = "/content/"
rf = rarfile.RarFile(path) #待解压文件
rf.extractall(path2) #解压指定文件路径
! mkdir cat_dog/val/Dog
! mkdir cat_dog/val/Cat
! mkdir cat_dog/train/Cat
! mkdir cat_dog/train/Dog
! mkdir cat_dog/test/test
! mv cat_dog/val/dog* cat_dog/val/Dog/
! mv cat_dog/val/cat* cat_dog/val/Cat/
! mv cat_dog/train/cat* cat_dog/train/Cat/
! mv cat_dog/train/dog* cat_dog/train/Dog/
! mv cat_dog/test/*.jpg cat_dog/test/test
- 数据处理:
torchvision支持对输入数据进行一些预处理/变换,图片将被整理成 224×224×3 的大小,同时还将进行归一化处理。
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
vgg_format = transforms.Compose([
# transforms.RandomHorizontalFlip(p=0.5), # 水平翻转
# transforms.RandomVerticalFlip(p=0.5), # 垂直翻转
# transforms.RandomRotation(30), # 随机旋转
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])
data_dir = './cat_dog'
dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), vgg_format)
for x in ['train', 'val']}
tsets = {y: datasets.ImageFolder(os.path.join(data_dir, y), vgg_format)
for y in ['test']}
dset_sizes = {x: len(dsets[x]) for x in ['train', 'val']}
dset_classes = dsets['train'].classes
loader_train = torch.utils.data.DataLoader(dsets['train'], batch_size=64, shuffle=True, num_workers=6)
loader_valid = torch.utils.data.DataLoader(dsets['val'], batch_size=5, shuffle=False, num_workers=6)
loader_test = torch.utils.data.DataLoader(tsets['test'],batch_size=5,shuffle=False,num_workers=6)
- 创建VGG Model:
使用预训练好的CNN模型,迁移学习。
我们可以看到VGG对于1000分类的表现也非常出色,可以细分到猫的具体种类。
# ImageNet 1000类的JSON文件展示VGG预测结果
!wget https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
# 使用了VGG19
model_vgg = models.vgg19(pretrained=True)
with open('./imagenet_class_index.json') as f:
class_dict = json.load(f)
dic_imagenet = [class_dict[str(i)][1] for i in range(len(class_dict))]
inputs_try , labels_try = inputs_try.to(device), labels_try.to(device)
model_vgg = model_vgg.to(device)
outputs_try = model_vgg(inputs_try)
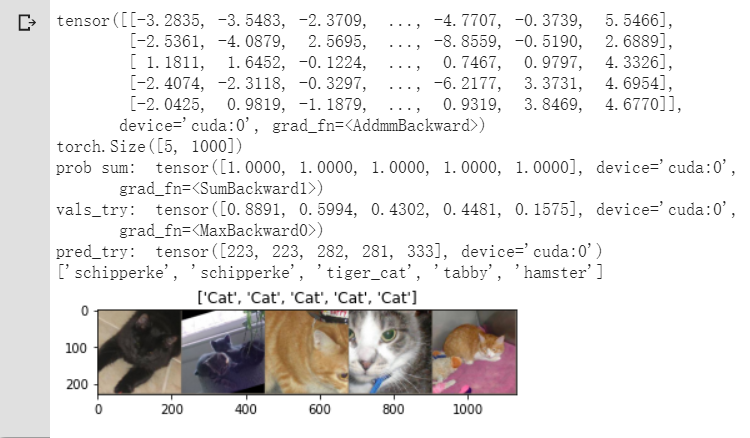
print(outputs_try)
print(outputs_try.shape)
'''
可以看到结果为5行,1000列的数据,每一列代表对每一种目标识别的结果。
但是我也可以观察到,结果非常奇葩,有负数,有正数,
为了将VGG网络输出的结果转化为对每一类的预测概率,我们把结果输入到 Softmax 函数
'''
m_softm = nn.Softmax(dim=1)
probs = m_softm(outputs_try)
vals_try,pred_try = torch.max(probs,dim=1)
print( 'prob sum: ', torch.sum(probs,1))
print( 'vals_try: ', vals_try)
print( 'pred_try: ', pred_try)
print([dic_imagenet[i] for i in pred_try.data])
imshow(torchvision.utils.make_grid(inputs_try.data.cpu()),
title=[dset_classes[x] for x in labels_try.data.cpu()])
- 修改最后一层,冻结前面层的参数:
VGG 模型由三种元素组成:
-
卷积层(CONV)是发现图像中局部的 pattern
-
全连接层(FC)是在全局上建立特征的关联
-
池化(Pool)是给图像降维以提高特征的 invariance
print(model_vgg)
model_vgg_new = model_vgg;
for param in model_vgg_new.parameters():
param.requires_grad = False # 冻结前面层的参数
model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2) # 1000类替换为2类(4096为全连接层维度)
model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1)
model_vgg_new = model_vgg_new.to(device)
print(model_vgg_new.classifier)
- 训练并测试全连接层:
- 创建损失函数和优化器
- 训练模型
- 测试模型
'''
第一步:创建损失函数和优化器
损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签.
它不会为我们计算对数概率,适合最后一层是log_softmax()的网络.
'''
criterion = nn.NLLLoss()
# 二分类:NLLLoss(负对数似然损失函数)
# criterion = nn.CrossEntropyLoss()
# 多分类:CrossEntropyLoss(交叉熵损失函数)
# 学习率 Adam最优3e-4
lr = 0.0003
# 随机梯度下降
# optimizer_vgg = torch.optim.SGD(model_vgg_new.classifier[6].parameters(),lr = lr)
# Adam
optimizer_vgg = torch.optim.Adam(model_vgg_new.classifier[6].parameters(),lr = lr)
'''
第二步:训练模型
'''
def train_model(model,dataloader,size,epochs=1,optimizer=None):
model.train()
for epoch in range(epochs):
running_loss = 0.0
running_corrects = 0
count = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
optimizer = optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
count += len(inputs) # 可调整训练图像序号,增大训练样本
print('Training: No. ', count, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
# 模型训练
train_model(model_vgg_new,loader_train,size=dset_sizes['train'], epochs=1,
optimizer=optimizer_vgg)
# 第三步:测试模型
def test_model(model,dataloader,size):
model.eval()
predictions = np.zeros(size)
all_classes = np.zeros(size)
all_proba = np.zeros((size,2))
i = 0
running_loss = 0.0
running_corrects = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
predictions[i:i+len(classes)] = preds.to('cpu').numpy()
all_classes[i:i+len(classes)] = classes.to('cpu').numpy()
all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy()
i += len(classes)
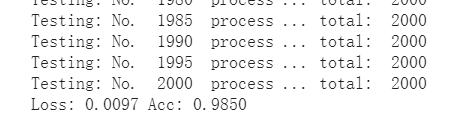
print('Testing: No. ', i, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
return predictions, all_proba, all_classes
predictions, all_proba, all_classes = test_model(model_vgg_new,loader_valid,size=dset_sizes['val'])
- 输出CSV类型文件:
import re
# 得到测试图片编号
string = tsets['test'].imgs[0][0]
num = re.sub("\D", "", string)
result = []
# 将测试数据集(test)输入到网络中,得到识别结果
for item,lable in loader_test:
item = item.to(device)
ll = model_vgg_new(item)
_,pre = torch.max(ll.data,1)
result += pre
# 结果排序
result_end =list()
cc = 0
for item in result:
string = tsets['test'].imgs[cc][0]
num = re.sub("\D", "", string)
result_end.append((num,item.tolist()))
cc += 1
result_sort = sorted(result_end,key=lambda x:int(x[0]))
# 写入文件
import csv
f = open('out_file.csv','w')
writer = csv.writer(f)
for i in result_sort:
writer.writerow(i)
f.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号