
课后作业3
一、个人信息
- 学号:2017xxxxx7080
- 姓名:于志霖
二、程序分析说明
def process_file(dst): # 读文件到缓冲区 try: # 打开文件 f=open(dst,'r') except IOError as s: print (s) return None try: # 读文件到缓冲区 bvffer=f.read() except: print ("Read File Error!") return None f.close() return bvffer
读文件到缓冲区
def process_buffer(bvffer): if bvffer: word_freq = {} # 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq bvffer=bvffer.lower() #大小写转换,将大写字母转化为小写字母 for s in '“”!?,.;:$': bvffer=bvffer.replace(s,' ') #将找出的特殊符替换为空格 list=bvffer.split() #以空格为标志分割字符串 for str in list: word_freq[str] = word_freq.get(str, 0) + 1 return word_freq
处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq
def output_result(word_freq): if word_freq: sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) for item in sorted_word_freq[:10]: # 输出 Top 10 的单词 print(item)
输出词频top10的单词
def test(): #将词频统计程序封装成测试程序 dst ="C:/Users/yuzhilin/Desktop/新建文件夹 (2)/Gone_with_the_wind.txt" bvffer = process_file(dst) word_freq = process_buffer(bvffer) output_result(word_freq)
结合前三个函数实现统计词频并输出前十的功能
三、性能分析结果及改进情况
(1)指出了正确的执行次数最多的代码和执行时间最长的代码
执行次数最多的代码

执行时间最长的代码

(2)给出改进优化方法,根据方法的正确性以及语言描述质量给分
答:改进界面、显示优化,使结果明确展现
(3)给出改进代码
#定义一个getstr类,对结果输出格式进行定义
def getstr(word,count,allwordnum): countstr=word+'----'+str(count)+'----'+str(allwordnum) return countstr
print('出现单词:'+word.1just(18)+'出现次数:'.1just(0)+str(cnt).1just(10)+'文章单词总数:'.1just(0)+str(allwordnum)) outdata.write(getstr(word,cnt,allwordnum)+'\n')
四、程序运行命令、结果截图
(1)程序运行命令、运行结果截图
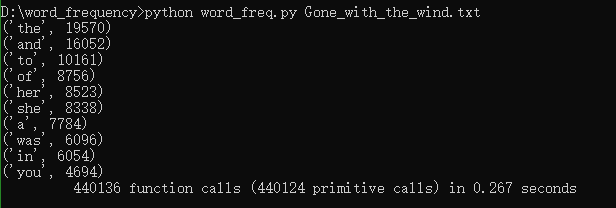
(因电脑中python环境搭建出现了问题,这是通过同学电脑运行出的结果,望老师谅解!)
五、总结反思
知识匮乏,针对本次作业我通过百度学到了很过东西也由此改进了代码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号