
re模块
正则表达式:
应用场景:
1、判断某一个字符串是否符合规则 (注册时:判断手机号,身份证号,邮箱格式是否正确)
2、将符合规则的内容从一个庞大的字符串体系中提取出来 (爬虫,日志分析)
什么是正则表达式:
只和字符串打交道,是一种规则,来约束字符串的规则
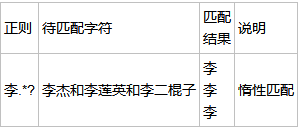
字符组:
在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用 [ ] 表示。
字符分为很多类,比如数字,字母,标点等等。
[0123456789] 表示0-9都可以匹配
[0-9] 用 - 表示范围,[0-9] 和 [0123456789] 是一样的
[a-z] 表示所有的小写字母
[A-Z] 表示所有的大写字母
[0-9a-fA-F] 可以匹配数字,大小写形式的a~f,常用来验证十六进制字符
原理是通过ASCII编码,小的一个值指向大的一个值
元字符:
\w 匹配字母或数字或下划线
\W 匹配非字母或非数字或非下划线
\s 匹配任意的空白符(空格、换行\n、制表符\t)
\S 匹配非空白符
\d 匹配数字
\D 匹配非数字
\n 匹配一个换行符
\t 匹配一个制表符
\b 匹配一个单词的边界
\A 匹配以什么开头,与 ^ 的功能一样 (\A匹配内容)
\Z 匹配以什么结尾,与 $ 的功能一样 (匹配内容\Z)
. 匹配除换行符以外的任意字符
^ 匹配字符串的开始
$ 匹配字符串的结尾
a|b 匹配字符a或字符b (把长的放前面,如 abc|ab)
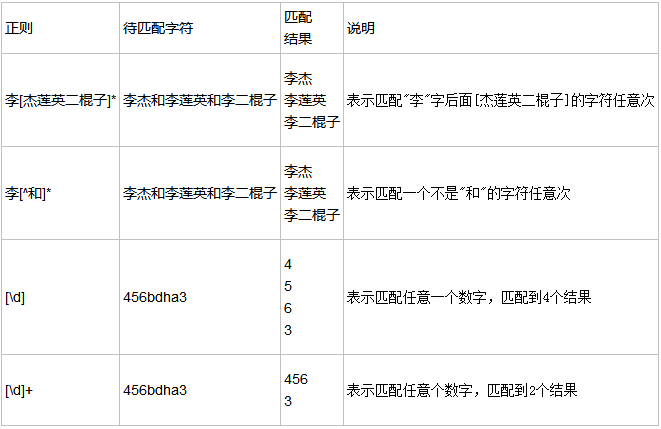
() 匹配括号内的表达式,也表示一个组
[...] 匹配字符组中的字符
[^...] 匹配除了字符组中字符的所有字符
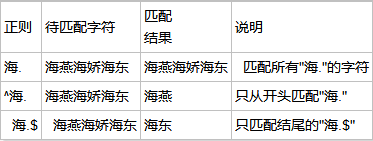
量词:
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次货更多次
{n,m} 重复n到m次

.^$
*+?{}
注意:前面的 *,+,? 等都是贪婪匹配,也就是尽可能多的匹配,后面加?使其变成惰性匹配
字符集 [ ] [ ^ ]
分组 ()与 或 | [ ^ ]
身份证号码是一个长度为15或18个字符的字符串,如果是15位则全部由数字组成,首位不能为0;如果是18位的,则前17位全部是数字,末位可以是数字或x
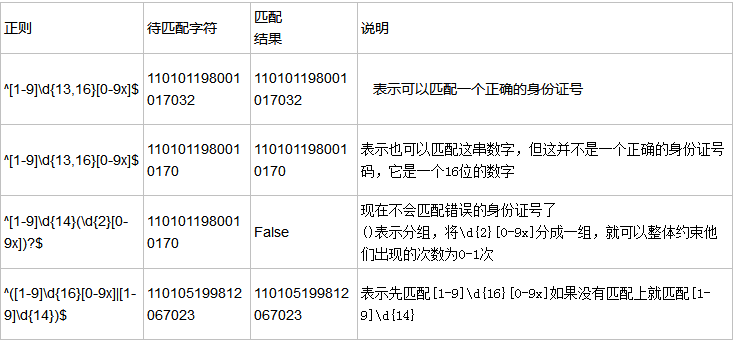
转义符 \
在正则表达式中,有很多有特殊意义的是元字符,比如\n和\s等,如果要在正则中匹配正常的"\n"而不是"换行符"就需要对"\"进行转义,变成'\\'。

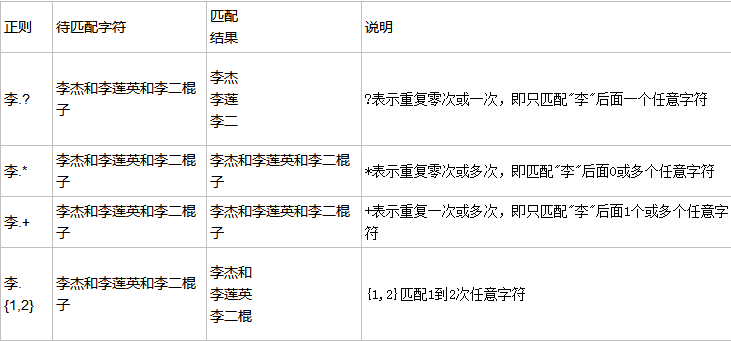
贪婪匹配
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配

几个常用的非贪婪匹配
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
. * ?
. 是任意字符
* 是取 0 至 无限长度
? 是非贪婪模式
合在一起就是,取尽量少的任意字符,一般不会这么单独写,大多用在:
. * ? x 就是取前面任意长度的字符,直到一个 x 出现
import re
# \w与\W print(re.findall('\w', 'hello egon 123')) # ['h', 'e', 'l', 'l', 'o', 'e', 'g', 'o', 'n', '1', '2', '3'] print(re.findall('\W', 'hello egon 123')) # [' ', ' '] # \s与\S print(re.findall('\s', 'hello egon 123')) # [' ', ' '] print(re.findall('\S', 'hello egon 123')) # ['h', 'e', 'l', 'l', 'o', 'e', 'g', 'o', 'n', '1', '2', '3'] # \n与\t都是空,都可以被\s匹配 print(re.findall('\s', 'hello \n egon \t 123')) # [' ', '\n', ' ', ' ', '\t', ' '] # \n与\t print(re.findall(r'\n', 'hello egon \n123')) # ['\n'] print(re.findall(r'\t', 'hello egon \t 123')) # ['\t'] # \d与\D print(re.findall('\d', 'hello egon 123')) # ['1', '2', '3'] print(re.findall('\D', 'hello egon 123')) # ['h', 'e', 'l', 'l', 'o', ' ', 'e', 'g', 'o', 'n', ' '] # \A与\Z print(re.findall('\Ahe', 'hello egon 123')) # ['he'] print(re.findall('123\Z', 'hello egon 123')) # ['123'] # ^与$ print(re.findall('^he', 'hello egon 123')) # ['he'] print(re.findall('123$', 'hello egon 123')) # ['123'] # 重复匹配:. * ? .* .*? + {n,m} | # . print(re.findall('a.b', 'a1b')) # ['a1b'] print(re.findall('a.b', 'a1b a*b a b aaab')) # ['a1b', 'a*b', 'a b', 'aab'] print(re.findall('a.b', 'a\nb')) # [] # * print(re.findall('ab*', 'bbbbbbb')) # [] print(re.findall('ab*', 'a')) # ['a'] print(re.findall('ab*', 'abbbbbb')) # ['abbbbbb'] # ? print(re.findall('ab?', 'a')) # ['a'] print(re.findall('ab?', 'abbbb')) # ['ab'] # 匹配所有包含小数在内的数字 print(re.findall('\d+\.?\d*', 'sdfsdfs231sdsd1.123sdfsfas34jk23kj52k3jh4kj')) # ['231', '1.123', '34', '23', '52', '3', '4'] # .*默认为贪婪匹配 print(re.findall('a.*b', 'a1b222222222b')) # ['a1b222222222b'] # .*? 为非贪婪匹配:推荐使用 print(re.findall('a.*?b', 'a1b22222222b')) # ['a1b'] # + print(re.findall('ab+', 'a')) # [] print(re.findall('ab+', 'abbb')) # ['abbb'] # {n,m} print(re.findall('ab{2}', 'abbbb')) # ['abb'] print(re.findall('ab{2,4}', 'abbb')) # ['abbb'] print(re.findall('ab{1,}', 'abbbbbb')) # ['abbbbbb'] print(re.findall('ab{0,}', 'a')) # ['a'] #[] print(re.findall('a[1*-]b', 'a1b a*b a-b')) # ['a1b', 'a*b', 'a-b'] []内的都为普通字符了,且如果-没有被转意的话,应该放到[]的开头或结尾 print(re.findall('a[^1*-]b', 'a1b a*b a-b a=b')) # ['a=b'] []内的^代表的意思是取反,所以结果为['a=b'] print(re.findall('a[0-9]b', 'a1b a*b a-b a=b')) # ['a1b'] print(re.findall('a[a-z]b', 'a1b a*b a-b a=b aeb')) # ['aeb'] print(re.findall('a[a-zA-Z]b', 'a1b a*b a-b a=b aeb aEb')) # ['aeb', 'aEb'] # 转义\ print(re.findall('a\\c', 'a\c')) # 对于正则来说a\\c确实可以匹配到a\c,但是在python解释器读取a\\c时,会发生转义,然后交给re去执行,所以抛出异常 print(re.findall(r'a\\c', 'a\c')) # ['a\\c'] r代表告诉解释器使用rawstring,即原生字符串,把我们正则内的所有符号都当普通字符处理,不要转义 print(re.findall('a\\\\c', 'a\c')) # 同上面的意思一样,和上面的结果一样都是['a\\c'] # ()分组 print(re.findall('ab+', 'ababab123')) # ['ab', 'ab', 'ab'] print(re.findall('(ab)+123', 'ababab123')) # ['ab'],匹配到末尾的ab123中的ab print(re.findall('(?:ab)+123', 'ababab123')) # ['ababab123'] findall的结果不是匹配的全部内容,而是组内的内容,?:可以让结果为匹配的全部内容
re模块下的常用方法:
import re # findall print(re.findall('\d', 'sdfh34h2h423h2h23h')) # ['3', '4', '2', '4', '2', '3', '2', '2', '3'] # 返回值是一个列表,里面的每个元素是所有匹配到的项 # search ret = re.search('\d', 'sdfh34h2h423h2h23h') print(ret) # <re.Match object; span=(4, 5), match='3'> print(ret.group()) # 3 ret = re.search('\d', 'sdhfsd') print(ret) # None if ret: print(ret.group()) # search返回值: # 返回一个re_Match对象 # 通过group取值 # 且只包含第一个匹配到值
import re # findall 有一个特点,会优先显示分组中的内容 ret = re.findall('www.(baidu|oldboy).com', 'www.baidu.com') print(ret) # ['baidu'] ret = re.search('www.(baidu|oldboy).com', 'www.baidu.com') print(ret) # <re.Match object; span=(0, 13), match='www.baidu.com'> print(ret.group()) # www.baidu.com
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号