DQL
五、DQL
数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE子句组成的查询块。要查询的东西可以是常量值、表达式、字段、函数等。
1 基础查询
语法:
SELECT 查询列表
FROM 表名;
示例:
# 查询表中的单个字段
SELECT last_name FROM employees;
# 查询表中的多个字段
SELECT
last_name,
salary,
email
FROM
employees;
# 查询表中的所有字段(当数据量大的时候,不建议使用)
SELECT * FROM employees;
# 查询常量值
SELECT 100;
SELECT 'john';
# 查询表达式
SELECT 100*98;
# 查询函数
SELECT version();
# 起别名
SELECT 100 as '常量值';
SELECT
first_name AS '姓',
last_name AS '名'
FROM
employees;
# DISTINCT去重,查询员工表中的所有部门编号
SELECT DISTINCT
department_id as '部门编号'
FROM
employees;
# 查询员工名和姓连接成一个字段,并显示为姓名,使用CONCAT
SELECT
CONCAT( last_name, first_name ) AS '姓名'
FROM
employees;
2 条件查询
语法:
SELECT 查询列表
FROM 表名
WHERE 条件表达式;
分类:
-
按条件表达式筛选:条件运算符:
>、<、=、<>、!=、>=、<=。 -
按逻辑表达式筛选:逻辑运算符:
&&(and)、||(or)、!(not)。 -
模糊查询:
like、betweenand、in、is null、is not null。
示例:
# 查询员工工资 > 12000 的员工信息
SELECT
*
FROM
employees
WHERE
salary > 12000;
# 查询部门编号不等于 90 号的员工名和部门编号
SELECT
last_name,
department_id
FROM
employees
WHERE
department_id != 90;
# 查询工资在 10000 到 20000 之间的员工名、工资以及奖金
SELECT
last_name AS '员工名',
salary AS '工资',
commission_pct AS '奖金'
FROM
employees
WHERE
salary >= 10000
AND salary <= 20000;
# 查询部门编号不是在 90 到 110 之间,或者工资高于 15000 的员工信息
SELECT
*
FROM
employees
WHERE
( department_id < 90 OR department_id > 110 )
OR ( salary > 15000 );
# 查询员工名中包含字符 a 的员工信息,百分号%用来通配任意N个字符,类似于正则表达式中的 .*
SELECT
*
FROM
employees
WHERE
last_name LIKE '%a%';
# 查询员工名中第二个字符为 _ 的员工信息
SELECT
*
FROM
employees
WHERE
last_name like '_\_%';
# 查询工资在 10000 到 20000 之间的员工名、工资以及奖金
SELECT
last_name AS '员工名',
salary AS '工资',
commission_pct AS '奖金'
FROM
employees
WHERE
salary BETWEEN 10000
AND 20000;
# 查询员工的工种编号是 IT_PROG 、AD_VP 的员工信息
SELECT
*
FROM
employees
WHERE
job_id IN ( 'IT_PROG', 'AD_VP' );
# 查询没有奖金的员工信息
SELECT
*
FROM
employees
WHERE
commission_pct IS NULL;
3 排序查询
语法:
SELECT 查询列表
FROM 表名
WHERE 条件表达式
ORDER BY 排序列表(字段 [asc],字段 [desc],……);
ASC升序,DESC降序。
示例:
# 查询员工信息,要求工资从高到低排序
SELECT
*
FROM
employees
ORDER BY
salary DESC;
# 查询部门编号 >= 90 的员工信息,按入职时间的先后进行排序
SELECT
*
FROM
employees
WHERE
department_id >= 90
ORDER BY
hiredate ASC;
# 按年薪的高低显示员工的信息和年薪
SELECT
*,
salary * 12 * ( IFNULL( commission_pct, 0 ) + 1 ) AS '年薪'
FROM
employees
ORDER BY
年薪 ASC;
# 查询员工信息,要求先按工资排序,再按员工编号排序
SELECT
*
FROM
employees
ORDER BY
salary,
employee_id;
4 常见函数
分类:
- 单行函数:将一个数据进行处理,返回一个值,如 length() 、concat() 等。
- 分组函数:将虚拟表看做一个组,处理一组数据,返回一个值。
4.1 单行函数之字符函数
# 获取参数值的字节个数: length(str)
SELECT LENGTH( 'john' ); -- 4
SELECT LENGTH( '张三丰hahaha' ); -- 15
# 拼接字符串: concat(str1,str2,……)
SELECT
CONCAT( last_name, '_', first_name ) AS '姓名'
FROM
employees;
# 将字符变为大写:upper(str)
SELECT
UPPER(last_name)
FROM
employees;
# 将字符变为小写: lower(str)
SELECT
LOWER( last_name )
FROM
employees;
# 截取字符:substr(str,position,[length])
# 截取从指定索引处后面所有字符
SELECT
SUBSTR( '李莫愁爱上了陆展元', 7 );
# 截取从指定索引处指定字符长度的字符
SELECT
SUBSTR( '李莫愁爱上了陆展元', 1,3 );
# 用于返回子串在原字符串中的第一次出现的索引,如果找不到返回0:instr(str,substr)
SELECT
INSTR( '杨不悔爱上了殷六侠', '殷六侠' );
# 去除左右空格:trim(str)
SELECT
trim( ' 杨不悔爱上了殷六侠 ' );
# 替换: replace(str,from_str,to_str)
SELECT
REPLACE ( '杨不悔爱上了殷六侠', '爱上了', '怎么可能爱上' );
# 用指定的字符实现左填充指定长度:lpad(str,len,padstr)
SELECT
LPAD( '杨不悔爱上了殷六侠', 20, '*' );
# 用指定的字符实现右填充指定长度: rpad(str,len,padstr))
SELECT
RPAD( '杨不悔爱上了殷六侠', 20, '*' );
4.2 单行函数之数学函数
# 四舍五入:round(x,d)
SELECT
ROUND(1.65)
SELECT
ROUND(1.45)
SELECT
ROUND(1.567,2)
# 向上取整:ceil(x)
SELECT
CEIL(1.11)
# 向下取整: floor(x)
SELECT
FLOOR(1.567)
# 截断:truncate(x,d)
SELECT
TRUNCATE(1.567,2)
# 取余。返回n除以m后的余数,mod(n,m)
SELECT
MOD(3,1)
4.3 单行函数之日期函数
# 返回当前系统日期+时间:now()
select NOW();
# 返回当前系统日期:curdate()
select CURDATE()
# 返回当前时间:curtime()
select CURTIME();
# 获取指定的部分,年、月、日、小时、分钟、秒:
SELECT YEAR(NOW());
SELECT MONTH(NOW());
SELECT DAY(NOW());
SELECT HOUR(NOW());
SELECT MINUTE(NOW());
SELECT SECOND(NOW());
# 将日期格式的字符转换成指定格式的日期:str_to_date(str,format)
SELECT STR_TO_DATE('9-13-1999','%m-%d-%y');
# 将日期转换为字符:date_format(date,format)
SELECT DATE_FORMAT(NOW(),'%Y年-%m月-%d日');
其中,format为格式化字符,如下:
| 格式字符 | 说明 |
|---|---|
| %a | 缩写星期名 |
| %b | 缩写月名 |
| %c | 月,数值 |
| %D | 带有英文前缀的月中的天 |
| %d | 月的天,数值(00-31) |
| %e | 月的天,数值(0-31) |
| %f | 微秒 |
| %H | 小时 (00-23) |
| %h | 小时 (01-12) |
| %I | 小时 (01-12) |
| %i | 分钟,数值(00-59) |
| %j | 年的天 (001-366) |
| %k | 小时 (0-23) |
| %l | 小时 (1-12) |
| %M | 月名 |
| %m | 月,数值(00-12) |
| %p | AM 或 PM |
| %r | 时间,12-小时(hh:mm:ss AM 或 PM) |
| %S | 秒(00-59) |
| %s | 秒(00-59) |
| %T | 时间, 24-小时 (hh:mm:ss) |
| %U | 周 (00-53) 星期日是一周的第一天 |
| %u | 周 (00-53) 星期一是一周的第一天 |
| %V | 周 (01-53) 星期日是一周的第一天,与 %X 使用 |
| %v | 周 (01-53) 星期一是一周的第一天,与 %x 使用 |
| %W | 星期名 |
| %w | 周的天 (0=星期日, 6=星期六) |
| %X | 年,其中的星期日是周的第一天,4 位,与 %V 使用 |
| %x | 年,其中的星期一是周的第一天,4 位,与 %v 使用 |
| %Y | 年,4 位 |
| %y | 年,2 位 |
4.4 单行函数之其他函数
# 显示当前数据库的版本:version()
SELECT version();
# 显示当前在那个数据库中:database()
SELECT DATABASE ();
# 显示当前登录的用户:user()
SELECT USER();
4.5 单行函数之流程控制函数
# 类似于 java 中的 switch ... case 语句:
case 要判断的字段或表达式
when 常量1 then 要显示的值1或语句1;
when 常量2 then 要显示的值2或语句2;
……
else 要显示的值n或语句n;
end;
# 类似于 java 中的 if ... else 语句:
case
when 条件1 then 要显示的值1或语句1
when 条件2 then 要显示的值2或语句2
……
else 要显示的值n或语句n
end;
# 举例
SELECT
*,
CASE
commission_pct
WHEN NULL THEN '没有奖金'
ELSE '有奖金'
END
FROM
employees;
4.6 分组(聚合)函数
常见的分组函数是:
-
avg():求平均值。
-
count():求总数。
-
max():求最大值。
-
min():求最小值。
-
sum():求和。
特点:
-
一般而言,sum 和 avg 用于处理数值型。max 、min 、count 可以处理任何类型。
-
avg 、count 、max 、min 、sum 都忽略 null 值。
-
count 函数一般单独使用,一般使用 count(*) 来统计行数。
-
和分组函数一同查询的字段要求是 group by 后的字段。
示例:
SELECT
avg( salary ), -- 平均值
count(*), -- 总数
MAX( salary ), -- 最大值
MIN( salary ), -- 最小值
sum( salary ) -- 求和
FROM
employees;
5 分组(聚合)查询
语法:
SELECT 分组函数,列[要求出现在group by后面]
FROM 表名
WHERE 条件表达式
group by 分组表达式
having 分组条件表达式
ORDER BY 排序列表(字段 [asc],字段 [desc],……);
示例:
# 示例:查询每个部门的平均工资
SELECT
avg( salary ) ,department_id
FROM
employees
GROUP BY
department_id;
# 示例:查询每个工种的最高工资
SELECT
max( salary ),
job_id
FROM
employees
GROUP BY
job_id;
# 示例:查询每个位置上的部门个数
SELECT
count(*),
location_id
FROM
departments
GROUP BY
location_id;
# 示例:邮箱中包含 a 字符的,每个部门的平均工资
SELECT
AVG( salary ),
department_id
FROM
employees
WHERE
email LIKE '%a%'
GROUP BY
department_id;
# 示例:查询有奖金的每个领导手下员工的最高工资
SELECT
max(salary),manager_id
from employees
where commission_pct is not null
GROUP BY manager_id;
# 示例:查询那个部门的员工个数 > 2
SELECT
department_id,
count(*) AS `count`
FROM
employees
GROUP BY
department_id
HAVING
`count` > 2
# 示例:查询每个工种有奖金的员工的最高工资 > 12000 的工种编号和其最高工资
SELECT
job_id,
max( salary ) AS `max`
FROM
employees
WHERE
commission_pct IS NOT NULL
GROUP BY
job_id
HAVING
`max` > 12000;
# 示例:按员工姓名的长度分组,查询每一组的员工个数,筛选出员工个数 > 5 的
SELECT
count(*) ,LENGTH( last_name )
FROM
employees
GROUP BY
LENGTH( last_name )
HAVING
count(*) > 5;
# 示例:查询每个部门每个工种的员工的平均工资
SELECT
AVG( salary ),
department_id,
job_id
FROM
employees
GROUP BY
department_id,
job_id;
6 连表查询
6.1 笛卡尔积
连表查询通过如下语句:
SELECT name,boyName from boys,beauty;
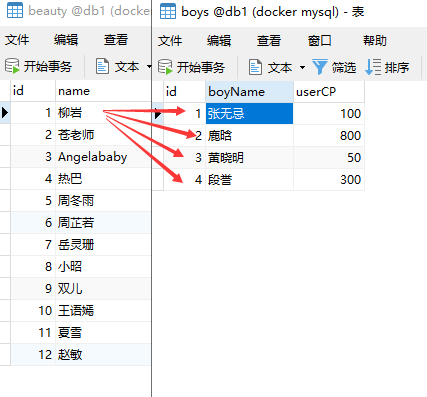
表A有m行,表B有n行,查询结果为m*n行,这种情况叫做笛卡尔积的错误。
为了避免笛卡尔积,需要在 WHERE 中加入有效的连接条件。
6.2 连接查询的分类
按年代分类:
- SQL 92 标准。
- SQL 99 标准(推荐使用)。
按功能分类:
- 内连接
- 等值连接。
- 非等值连接。
- 自连接。
- 外连接
- 左外连接。
- 左右连接。
- 全外连接(MySQL中不支持)。
- 交叉连接
6.3 SQL 92 标准
SQL 92 标准支持所有的内连接。
等值连接:
# 查询女神名和其对应的男神名
SELECT
`name`,
boyName
FROM
beauty,
boys
WHERE
beauty.boyfriend_id = boys.id;
# 示例:查询员工名和其对应的部门名
SELECT
last_name,
department_name
FROM
employees,
departments
WHERE
employees.department_id = departments.department_id;
# 示例:查询有奖金的员工名、部门名
SELECT
e.last_name,
d.department_name
FROM
employees e,
departments d
WHERE
e.department_id = d.department_id
AND e.commission_pct IS NOT NULL;
非等值连接:
# 查询员工的工资等级
SELECT
e.salary,
jg.grade_level
FROM
employees e,
job_grades jg
WHERE
e.salary BETWEEN jg.lowest_sal
AND jg.highest_sal;
自连接:
SELECT
e.last_name as last_name ,
m.last_name as manager_name
FROM
employees as e,
employees as m
WHERE
e.manager_id = m.employee_id;
6.4 SQL 99 标准
语法:
SELECT 查询列表
FROM 表1 别名 [连接类型 inner|left|right] join 表2 别名
ON 连接条件
WHERE 筛选条件
group by 分组字段
having 分组筛选条件
order by 排序列表;
# 说明:
# 内连接:inner join
# 外连接:
# 左外连接:left [outer] join
# 右外连接:right [outer] join
# 全外连接:full [outer] join
# 交叉连接:cross join
内连接示例:
# 查询女神名和其对应的男神名
SELECT
`name`,
boyName
FROM
beauty
INNER JOIN boys
ON beauty.boyfriend_id = boys.id;
# 查询员工的工资等级
SELECT
e.salary,
jg.grade_level
FROM
employees e
INNER JOIN job_grades jg ON e.salary BETWEEN jg.lowest_sal
AND jg.highest_sal;
SELECT
e.salary,
jg.grade_level
FROM
employees e
INNER JOIN job_grades jg ON e.salary BETWEEN jg.lowest_sal
AND jg.highest_sal;
# 查询员工的名称和其上级的名称
SELECT
e.last_name AS last_name,
m.last_name AS manager_name
FROM
employees AS e
INNER JOIN employees AS m ON e.manager_id = m.employee_id;
内连接主要查询的是两个表中某个字段数据相同的交集部分,外连接主要用于查询一个表中有,另一个表中没有的数据。
外连接查询时,分为主表和从表,用作主表的表写在运算符左边时用左外连接,主表写在运算符右边时用右外连接。
比如主表A外连接从表B,查询结果为主表中的所有记录,如果从表中有匹配的,就显示,如果从表没有匹配,则显示null。换句话说,相当于:外连接的查询结果=内连接结果+主表中有但从表中没有的记录
# 查询没有男朋友的女神名
SELECT
beauty.`name`,
boys.boyName
FROM
beauty # beauty为主表,写在左边所以使用左外连接
LEFT JOIN boys ON beauty.boyfriend_id = boys.id
WHERE
boys.boyName IS NULL;
交叉连接(笛卡尔积):
SELECT
beauty.`name`,
boys.boyName
FROM
beauty
CROSS JOIN boys;
7 子查询
子查询:出现在其他语句内部的select语句,称为子查询。而内部嵌套其他select语句的查询,称为主查询或外查询。
子查询的分类,按照子查询出现的位置:
- select 后面:仅仅支持标量子查询
- from 后面:支持表子查询
- where 或 having 后面:支持标量子查询或列子查询,行子查询
- exists 后面(又称为相关子查询):支持表子查询
按照结果集的行列数不同:
- 标量子查询(结果集只有一行一列)
- 列子查询(结果集只有一列多行)
- 行子查询(结果集有一行多列)
- 表子查询(结果集,一般为多行多列)
select后面支持标量子查询;
from后面支持表子查询;
where或having后面支持标量子查询,列子查询,行子查询;
exists后面支持表子查询。
7.1 在where或having后面
这种子查询是最常用的。它的特点:
-
子查询放在小括号内
-
子查询一般放在条件的右侧
-
标量子查询,一般搭配单行操作符使用(>、<、>=、<=、<>)
-
列子查询,一般搭配多行操作符使用(in、any/some、all)
标量子查询示例:
# 查询谁的工资比 Abel 高
SELECT
last_name
FROM
employees
WHERE
salary > ( SELECT salary FROM employees WHERE last_name = 'Abel' );
# 返回 job_id 和 141 号员工相同,salary 比 143 号员工多的员工姓名、job_id 和工资
SELECT
last_name,
job_id,
salary
FROM
employees
WHERE
job_id = ( SELECT job_id FROM employees WHERE employee_id = 141 )
AND salary > ( SELECT salary FROM employees WHERE employee_id = 143 );
# 返回公司工资最少的员工的 last_name 、job_id 和 salary
SELECT
last_name,
job_id,
salary
FROM
employees
WHERE
salary = ( SELECT min( salary ) FROM employees );
# 查询最低工资大于 50 号部门最低工资的部门 id 和其最低工资
SELECT
department_id,
MIN( salary )
FROM
employees
GROUP BY
department_id
HAVING
min( salary ) > ( SELECT min( salary ) FROM employees WHERE department_id = 50 );
列子查询示例:
# 返回 location_id 是 1400 或 1700 的部门中的所有员工姓名
SELECT
last_name
FROM
employees
WHERE
department_id IN ( SELECT DISTINCT department_id FROM departments WHERE location_id IN ( 1400, 1700 ) );
# 返回其它工种中比 job_id 为 'IT_PROG' 工种任一工资低的员工的员工号、姓名、job_id 以及 salary
SELECT
employee_id,
last_name,
job_id,
salary
FROM
employees
WHERE
salary < ANY ( SELECT DISTINCT salary FROM employees WHERE job_id = 'IT_PROG' ) and job_id != 'IT_PROG';
# 返回其它工种中比 job_id 为 'IT_PROG' 工种所有工资低的员工的员工号、姓名、job_id 以及 salary
SELECT
employee_id,
last_name,
job_id,
salary
FROM
employees
WHERE
salary < ALL ( SELECT DISTINCT salary FROM employees WHERE job_id = 'IT_PROG' ) and job_id !
行子查询不常用,示例:
# 查询员工编号最小并且工资最高的员工信息
SELECT * FROM employees
WHERE ( salary, employee_id ) = (( SELECT max( salary ) FROM employees ),( SELECT min( employee_id ) FROM employees ) );
7.2 在select后面
示例:
# 查询每个部门的员工个数
SELECT d.*,( SELECT count(*) FROM employees e WHERE e.department_id = d.department_id ) as '员工个数'
FROM
departments d;
7.3 在from后面
# 查询每个部门的平均工资的工资等级
SELECT
temp.department_id,
jg.grade_level
FROM
( SELECT department_id AS department_id, avg( salary ) AS `avg` FROM employees GROUP BY department_id ) temp
INNER JOIN ( SELECT grade_level, highest_sal, lowest_sal FROM job_grades ) jg ON temp.avg BETWEEN jg.lowest_sal
AND jg.highest_sal;
7.4 在exists后面
语法:
exists(查询语句)
# 返回 0或者1
示例:
# 查询有员工的部门名
SELECT
department_name
FROM
departments d
WHERE
EXISTS ( SELECT * FROM employees e WHERE d.department_id = e.department_id );
8 分页查询
应用场景:实际的web项目中需要根据用户的提交请求,返回对应的分页
语法:
SELECT 查询列表
FROM 表 [join type] JOIN 表2
ON 连接条件
WHERE 筛选条件
GROUP BY 分组字段
HAVING 分组筛选条件
ORDER BY 排序字段
LIMIT 起始索引(从0开始),每页显示条数。
特点:
- 起始条目索引从0开始
- limit子句放在查询语句的最后
- 公式:
select * from 表 limit (page-1)*sizePerPage,sizePerPage,其中每页显示条目数sizePerPage,要显示的页数page
示例:
# 查询前 5 条员工信息
SELECT
*
FROM
employees
LIMIT 0,5;
9 联合查询
将多条查询语句的结果合并成一个结果。
语法:
查询语句1
UNION
查询语句2
...;
特点:
-
多条查询语句的查询的列数必须是一致的
-
多条查询语句的查询的列的类型几乎相同
-
union代表去重,union all代表不去重,可以包含重复项
示例:
# 查询部门编号 > 90 或邮箱包含 a 的员工信息
SELECT * FROM employees WHERE last_name LIKE '%a%'
UNION
SELECT * FROM employees WHERE department_id > 90 ;
本文来自博客园,作者:yyyz,转载请注明原文链接:https://www.cnblogs.com/yyyzyyyz/p/15848647.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号