运行原理
八、运行原理
此处,你应该已经熟悉Kubernetes能提供什么以及做了什么。现在,是时候了解下它们是怎么被实现的了。
1 Kubernetes架构
在第一章中,介绍过Kubernetes的架构,现在来回顾一下。Kubernetes集群分为两部分:
- Kubernetes控制平面(主节点)
- 工作节点
控制平面负责控制并使得整个集群正常运转。控制平面包含如下组件:
- Kubernetes API Server,控制面板所有的其他组件都要和它通信
- Scheduler,调度器,为应用分配工作节点
- Controller Manager,控制管理器执行集群级别的功能,比如复制组件、持续跟踪工作节点等
- etcd分布式可监控存储,它能够持久化存储集群配置
这些组件用来存储、管理集群状态, 但它们不是运行应用的容器。工作节点是真正运行应用的地方。主要包含如下组件:
- Docker等容器
- Kubelet,能够与主节点控制面板的API Server通信,还可以部署、监控、维护它所在节点的容器
- Proxy,它负责组件之间的负载均衡和服务发现
除了控制平面(和运行在节点上的组件, 还要有几个附加组件, 这样才能提供所有之前讨论的功能。)包含:
- Kubernetes DNS服务器
- 仪表板
- Ingress控制器
- Heapster (容器集群监控)
- 容器网络接口插件
1.1 Kubernetes组件的分布式特性
之前提到的组件都是作为单独进程运行的。下图描述了各个组件及它们之间的依赖关系。
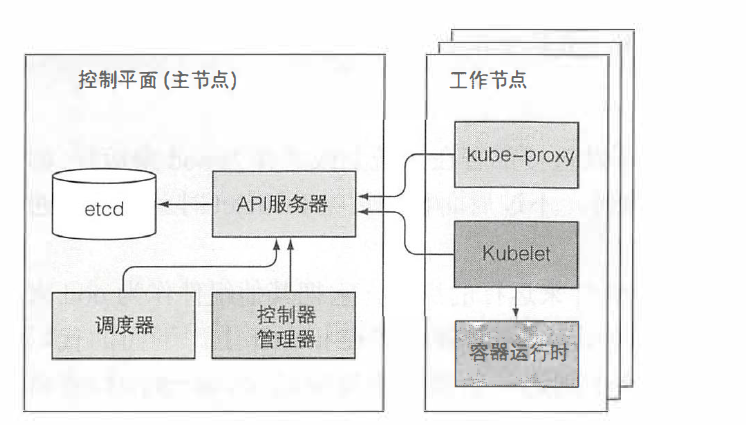
API服务器对外暴露了一个名为ComponentStatus的API资源,用来显示每个控制平面组件的健康状态。可以通过kubectl列出各个组件以及它们的状态:
kubectl get componentstatuses
在组件通信方面,Kubernetes系统组件间只能通过API服务器通信,它们之间不会直接通信。API服务器是和etcd通信的唯一组件。其他组件不会直接和etcd通信,而是通过API服务器来修改集群状态。
尽管工作节点上的组件都需要运行在同一个节点上,控制平面的组件可以被简单地分割在多台服务器上。为了保证高可用性,控制平面的每个组件可以有多个实例。etcd和API服务器的多个实例可以同时并行工作,但是,调度器和控制器管理器在给定时间内只能有一个实例起作用,其他实例处于待命模式。
控制平面的组件以及kube-proxy可以直接部署在系统上或者作为pod来运行,而Kubelet是唯一作为常规系统组件来运行的组件,它把其他组件作为pod来运行。为了将控制平面作为pod来运行,Kubelet被部署在master上。通过以下命令查看系统名称空间下的pod:
kubectl get pod -o custom-columns=POD:metadata.name,NODE:spec.nodeName --sort-by spec.nodeName -n kube-system
# 参数说明
# 通过-o custom-columns选项自定义展示的列
# --sort-by spec.nodeName 对资源列表按spec.nodeName字段进行排序
结果如下:
POD NODE
coredns-5c98db65d4-cvc88 k8s-master # DNS服务
coredns-5c98db65d4-kfnvn k8s-master # DNS服务
etcd-k8s-master k8s-master # etcd
kube-apiserver-k8s-master k8s-master # API服务器
kube-controller-manager-k8s-master k8s-master # 控制器管理器
kube-scheduler-k8s-master k8s-master # 调度器
kube-flannel-ds-j8xd2 k8s-master # flannel
kube-proxy-k4nlq k8s-master # kube-proxy
kube-proxy-7pvcm k8s-node-1 # kube-proxy
kube-flannel-ds-828wp k8s-node-1 # flannel
kube-flannel-ds-ld4cs k8s-node-2 # flannel
kube-proxy-kw2xs k8s-node-2 # kube-proxy
所有的控制平面组件在主节点上作为pod运行,可以看到,etcd、API服务器、调度器、控制器管理器和DNS服务运行在master上,两个工作节点均运行一个Kube-Proxy pod和一个Flannel网络pod,用来为pod提供重叠网络。
现在,让我们对每一个组件进行研究,从持久化存储组件etcd开始。
1.2 Kubernetes如何使用etcd
etcd用于将数据持久化,它是一个响应快、分布式、一致的key-value存储。因为它是分布式的,故可以运行多个etcd来获取高可用性和更好的性能。
唯一能直接和etcd通信的是Kubernetes的API服务器。所有其他组件通过API服务器间接地读取、写入数据到etcd。这带来一些好处,其中之一就是增强乐观锁系统、验证系统的健壮性;并且,通过把实际存储机制从其他组件抽离,未来替换起来也更容易。值得强调的是,etcd是Kubernetes存储集群状态和元数据的唯一的地方。
为保证高可用性,常常会运行多个etcd。多个etcd需要保持一致。这种分布式系统需要对系统的实际状态达成一致。etcd使用RAFT一致性算法来保证这一点,确保在任何时间点,每个节点的状态要么是大部分节点的当前状态,要么是之前确认过的状态。此外,要保证运行的etcd集群个数成员为奇数。
1.3 Kubernetes API服务器
Kubernetes API作为中心组件,其他组件或者客户端都会去调用它。以RESTfulAPI的形式提供了可以查询、修改集群状态的CRUD接口。它将状态存储到etcd中。
API服务器除了提供一种一致的方式将对象存储到etcd,也对这些对象做校验,这样客户端就无法存入非法的对象了(直接写入存储的话是有可能的)。除了校验,还会处理乐观锁,这样对于并发更新的情况,对对象做更改就不会被其他客户端覆盖。
API服务器的客户端之一就是前几章一直在使用的kubectl,举个例子, 当以JSON文件创建一个资源, kubectl通过一个HTTP POST请求将文件内容发布到API服务器。接收到请求后API服务器内部操作如下图:
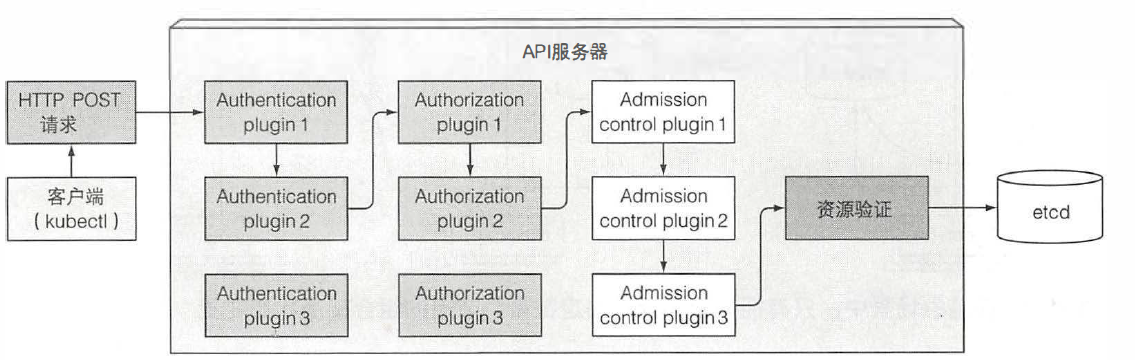
Authentication:首先, API服务器需要认证发送请求的客户端。这是通过配置在API服务器上的一个或多个认证插件来实现的。API服务器会轮流调用这些插件,直到有一个能确认是谁发送了该请求。这是通过检查HTTP请求实现的。
Authorization:除了认证插件,API服务器还可以配置使用一个或多个授权插件。它们的作用是决定认证的用户是否可以对请求资源执行请求操作。例如,当创建pod 时,API服务器会轮询所有的授权插件,来确认该用户是否可以在请求命名空间创建pod。一旦插件确认了用户可以执行该操作,API服务器会继续下一步操作。
Admission:如果请求尝试创建、修改或者删除一个资源,请求需要经过准入控制插件的验证。同理,服务器会配置多个准入控制插件。这些插件会因为各种原因修改资源,可能会初始化资源定义中漏配的字段为默认值甚至重写它们。插件甚至会去修改并不在请求中的相关资源,同时也会因为某些原因拒绝一个请求。资源需要经过所有准入控制插件的验证。但是,如果请求只是尝试读取数据,则不会做准入控制的验证。
资源验证:请求通过了所有的准入控制插件后,API服务器会验证存储到etcd,然后返回一个响应给客户端。
1.4 调度器
前面的章节提到过,通常不会去指定pod应该运行在哪个集群节点上,这项工作交给调度器Scheduler完成。宏观来看,调度器的操作比较简单。就是利用API服务器的监听机制等待新创建的pod,然后给每个新的、没有节点集的pod分配节点。
调度器不会命令选中的节点(或者节点上运行的Kubelet)去运行pod。调度器做的就是通过API服务器更新pod的定义。然后API服务器再去通知Kubelet该pod已经被调度过。当目标节点上的Kubelet发现该pod被调度到本节点,它就会创建并且运行pod的容器。
调度过程可以很简单,比如不关心节点上已经运行的pod,随机选择一个节点;调度过程也可以很复杂,比如机器学习,来预测接下来几分钟或几小时哪种类型的pod将会被调度, 然后以最大的硬件利用率、无须重新调度己运行pod的方式来调度。Kubernetes的默认调度器实现方式处于最简单和最复杂程度之间。
在一个集群中,满足一个pod调度请求的所有节点称之为可调度节点。 如果没有任何一个节点能满足pod的资源请求,那么这个pod将一直停留在未调度状态直到调度器能够找到合适的节点。
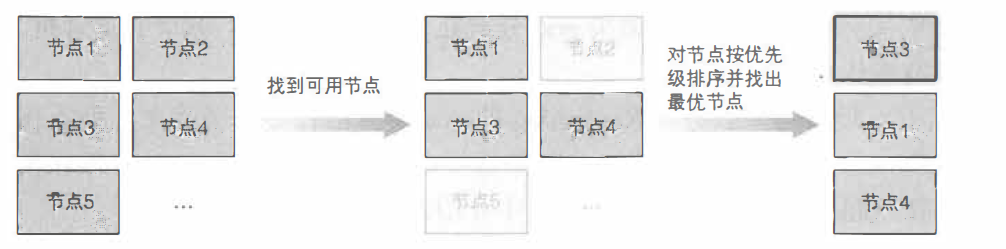
调度器给一个pod做调度选择包含两个步骤:
- 过滤
- 打分
过滤阶段会将所有满足pod调度需求的节点选出来。 例如,PodFitsResources过滤函数会检查候选节点的可用资源能否满足pod的资源请求。在过滤之后,得出一个节点列表,里面包含了所有可调度节点;通常情况下,这个节点列表包含不止一个节点。如果这个列表是空的,代表这个pod不可调度。
在打分阶段,调度器会为pod从所有可调度节点中选取一个最合适的节点。根据当前启用的打分规则,调度器会给每一个可调度节点进行打分。最后,调度器会将pod调度到得分最高的节点上。如果存在多个得分最高的节点,调度器会从中随机选取一个。
整个过程如下图:
支持以下两种方式配置调度器的过滤和打分行为:
- 调度策略 允许你配置过滤的断言(Predicates)和打分的优先级(Priorities)
- 调度配置 允许你配置实现不同调度阶段的插件, 包括:
QueueSort,Filter,Score,Bind,Reserve,Permit等等。 你也可以配置调度器运行不同的配置文件
1.5 控制器管理器
如前面提到的,API服务器只做了存储资源到etcd和通知客户端有变更的工作。调度器则只是给pod分配节点,所以需要有活跃的组件确保系统真实状态朝API服务器定义的期望的状态收敛。这个工作由控制器管理器(Controller Manager)里的控制器来实现。
我们已经接触过很多控制器,比如第四章介绍的各种资源控制器,第七章介绍的StatefulSet都是控制器,每个控制器做什么通过名字显而易见。
控制器之间不会直接通信,它们甚至不知道其他控制器的存在。每个控制器都连接到API服务器,通过监听机制,请求订阅该控制器负责的一系列资源的变更。
以上简要介绍了主节点的四个组件,接下来是工作节点的组件。
1.6 Kubelet
所有Kubernetes控制平面的控制器都运行在主节点上, 而Kubelet以及Service Proxy都运行在工作节点上。
简单地说, Kubelet就是负责所有运行在工作节点上内容的组件。它第一个任务就是在API服务器中创建一个Node资源来注册该节点。然后需要持续监控API服务器是否把该节点分配给pod,然后启动pod容器。具体实现方式是告知配置好的容器运行时来从特定容器镜像运行容器。Kubelet随后持续监控运行的容器,向API服务器报告它们的状态、事件和资源消耗。
Kubelet也是运行容器存活探针的组件,当探针报错时它会重启容器。最后一点,当pod从API服务器删除肘,Kubelet终止容器,并通知服务器pod已经被终止了。
1.7 Kubernetes Service Proxy
除了Kubelet,每个工作节点还会运行kube-proxy ,用于确保客户端可以通过Kubernetes API连接到你定义的服务。kube-proxy确保对服务IP和端口的连接最终能到达支持服务的某个pod处。如果有多个pod支撑一个服务,那么代理会发挥对pod的负载均衡作用。
查看官方文档以了解更多kube-proxy的知识。
1.8 Kubernetes插件
现在已经讨论了Kubernetes集群正常工作所需要的一些核心组件。同时还罗列了一些插件,它们不是必需的这些插件用于启用Kubernetes服务的DNS查询,通过单个外部IP地址暴露多个HTTP服务、Kubernetes web仪表板等特性。
通过提交YAML清单文件到API服务器,这些组件会成为插件并作为pod部署。有些组件是通过Deployment资源或ReplicationController资源部署的,有些是通过DaemonSet 。
2 控制器如何协作
让我们看一下当一个pod资源被创建时会发生什么。因为一般不会直接创建pod,所以创建Deployment资源作为替代,然后观察启动pod 的容器会发生什么。
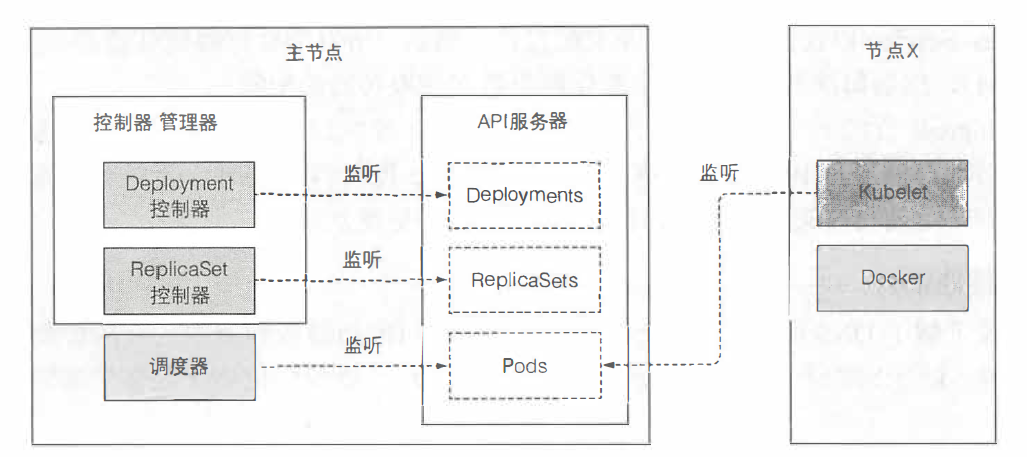
2.1 涉及组件
在启动整个流程之前,控制器、调度器、Kubelet就已经通过API服务器监听它们各自资源类型的变化了。如下图,图中的每个组件在即将触发的流程中都起到一定的作用。图中不包含etcd,因为它被隐藏在API服务器之后。
2.2 事件链
准备包含Deployment资源清单的yaml文件,通过kubectl提交到Kubernetes。kubectl通过POST请求发送资源清单到Kubernetes API服务器。API服务器检查Deployment定义,存储到etcd,返回响应给kubectl。整个事件链如下图:
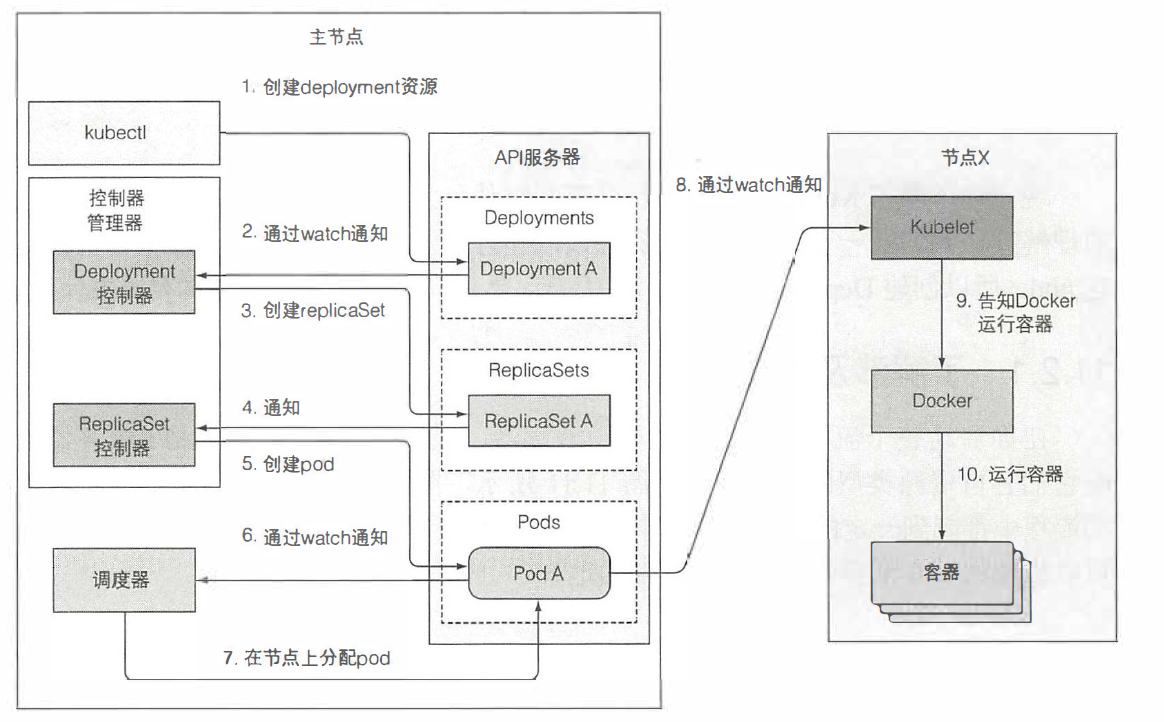
当新创建Deployment资源时,所有通过API服务器监听机制监听Deployment列表的客户端马上会收到通知,其中有个客户端叫Deployment控制器,该控制器是一个负责处理部署事务的活动组件。当Deployment控制器检查到有一个新的Deployment对象时,会按照Deploymnet当前定义创建ReplicaSet。这包括通过Kubernetes API创建一个新的ReplicaSet资源。Deployment控制器不会去直接创建新的pod。
新创建的ReplicaSet由ReplicaSet控制器(通过API服务器创建、修改、删除ReplicaSet资源)接收。控制器会考虑replica数量、ReplicaSet中定义的pod选择器,然后检查是否有足够的满足选择器的pod。然后控制器会基于ReplicaSet的pod模板创建pod资源(当Deployment控制器创建ReplicaSet时,会从Deployment复制pod模板)。
新创建的pod目前保存在etcd中,但是它们每个都缺少一个重要的东西就是它们还没有任何关联节点。它们的nodeName属性还未被设置。调度器会监控像这样的pod,发现一个,就会为这个pod选择最佳节点,并将节点分配给pod。pod的定义现在就会包含它应该运行在哪个节点。
到此为止,所有的一切都发生在Kubernetes控制平面(主节点)中。工作节点还没做任何事情,pod容器还没有被启动起来,pod容器的镜像还没有下载。随着pod目前分配给了特定的节点,节点上的Kubelet终于可以工作了。Kubelet通过API服务器监听pod变更,发现有新的pod分配到本节点后,会去检查pod定义,然后命令Docker(或者其它容器)运行容器。
2.3 观察事件
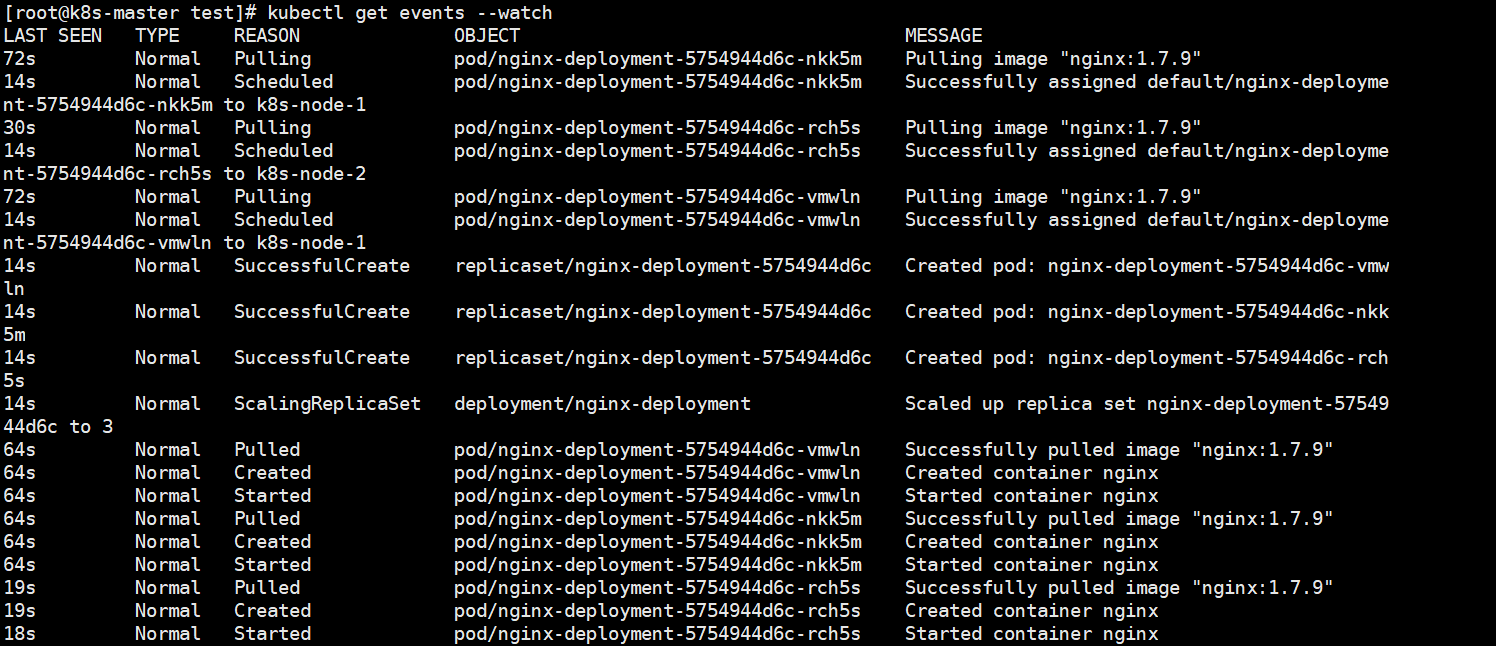
控制平面组件和Kubelet执行动作时,都会发送事件给API服务器。发送事件是通过创建事件资源来实现的,事件资源和其他的Kubernetes资源类似。每次使用kubectl describe来检查资源的时候,就能看到资源相关的事件,也可以直接用kubectl get events获取事件。
使用kubectl get检查事件时,因为不是以合适的时间顺序显示的。当一个事件发生了多次,该事件只会被显示一次,显示首次出现时间、最后一次出现时间以及发生次数。如果你不习惯这种显示,可以利用--watch选项。
kubectl get events --watch
结果如下图所示:
本文来自博客园,作者:yyyz,转载请注明原文链接:https://www.cnblogs.com/yyyzyyyz/p/15778717.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号