资源控制器
四、资源控制器
pod分为两种类型:
- 自主式pod:如果pod退出,不会被重新创建
- 控制器管理的pod:如果pod退出,资源控制器会注意到缺少了pod并重建替代pod,以维持设定的pod副本数目
在第三章中创建的pod都是自主式pod。下面介绍控制器管理的pod,控制器有很多类型:
- ReplicationController 和 ReplicaSet
- Deployment
- DaemonSet
- StateFulSet
- Job/CronJob
- Horizontal Pod Autoscaling
1 ReplicationController和ReplicaSet
1.1 ReplicationController
ReplicationController可确保它管理的pod始终保持运行状态。如果pod因任何原因消失(例如节点从集群中消失或由于该pod已从节点中逐出),则ReplicationController会注意到缺少了pod并创建替代pod,确保容器应用的副本数始终保持在用户定义的副本数,而如果异常多出来的容器也会自动回收。
RC的控制流程如下图所示:
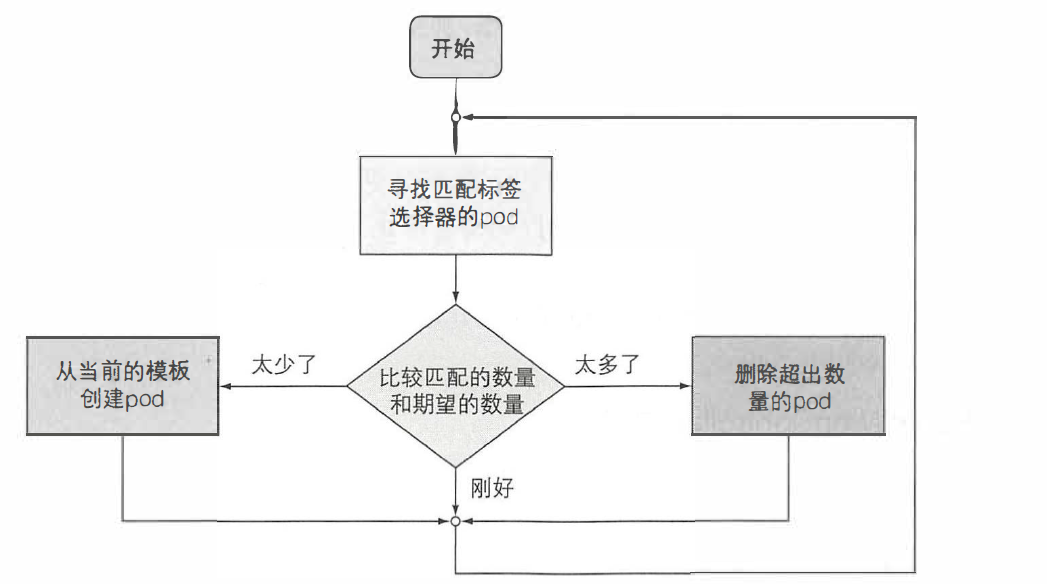
RC有三个主要部分:
- 标签选择器:用于确定RC管理哪些pod
- 副本个数:指定应运行的pod的期望数量
- pod模版:创建pod的资源清单
创建一个RC的资源清单如下:
apiVersion: v1
kind: ReplicationController # 定义资源类型为RC
metadata:
name: kubia # RC的名字
spec:
replicas: 3 # 期望的pod数目
selector:
app: kubia # pod选择器决定RC管理哪些pod(通过pod的标签)
template: # 创建pod所使用的模版
metadata:
labels:
app: kubia # 添加标签,RC根据这个标签名来管理pod
spec:
containers:
- name: mykubia
image: luksa/kubia
ports:
- containerPort: 8080
根据这个资源清单创建RC还是使用之前提到的kubectl create/apply -f命令即可,RC名字叫做kubia,它确保符合标签选择器app=kubia的pod始终为三个,当没有足够的pod时,根据提供的pod模板创建新的pod。template中的内容与前面我们手动创建pod的资源清单的定义基本相同。
刚创建这个RC时,此时并没有app=kubia标签,RC会根据template模版的内容,创建出三个pod。如果此时手动删除一个pod,RC会立即启动一个新pod,保持pod的数量始终为三。
可以通过kubectl get rc命令查看关于RC的相关信息:
NAME DESIRED CURRENT READY AGE
kubia 3 3 2 3m
1.2 ReplicaSet
下面要说明的是:使用ReplicaSet来代替ReplicationController。RS和RC相比,RS在标签选择的功能上更加强大:比如RS可以仅匹配标签名(相当于labels=*)而不论标签的内容是什么;再比如RS还允许匹配缺少某个标签的pod等等。
RS的资源清单如下:
apiVersion: apps/v1
kind: ReplicaSet # # 定义资源类型为RS
metadata:
name: kubia
spec:
replicas: 3
selector: # 这里的matchlabels和RC的selector作用是相同的
matchLabels:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: mykubia
image: luksa/kubia
可以看到与RC基本相同,惟一的区别在选择器上:没必要在selector中直接指定匹配pod的标签,而是多了一层matchLabels,在它下面指定标签。
创建RS也使用kubectl create/apply -f命令,同样可以通过如下命令来检查RS的相关信息:
kubectl get rs
kubectl describe rs
如你所见,RC与RS的使用没有任何区别,在RC的基础上,RS支持另一种选择器:
# 一个RS资源清单的选择器部分
selector:
matchExpressions:
- key: app
operator: In
values:
- kubia
RS可以使用matchExpressions标签选择器,可以添加额外的表达式,这种表达式由如下几个部分组成:
key标签名operator运算符,有四种:In,标签的值必须与其中一个指定的values匹配NotIn,标签的值与任何指定的values不匹配Exists,pod必须包含一个指定名称的标签(值不重要)。使用此运算符时,不应指定values字段。DoesNotExist,pod不得包含有指定名称的标签。使用此运算符时,不应指定values字段。
values标签值
比如,上述例子要求pod必须包含名为app的标签,且标签值必须为kubia。
k8s推荐使用RS代替RC,且后续会将RC弃用。
1.3 通过资源控制器管理pod
RC和RS作为资源控制器,可以很方便地对pod进行管理,比如扩容缩容等操作。你可以随时更改资源清单的replicas,方便地实现pod扩容缩容。并且,如果你更改了一个pod的标签,那么这个pod就不再归该资源控制器管理了,当你更改pod标签时,RC或RS会注意到一个pod丢失了,于是重新创建一个新的。此时被更改过标签的pod就变得和其他手动创建的pod 一样,如果把这个更改过标签的pod删掉,RC或者RS也不会重新调度它。
1.4 删除RC或者RS
接下来介绍如何删除资源控制器:
kubectl delete rc rc名称 # 删除rc
kubectl delete rs rs名称 # 删除rs
# 举例
kubectl delete rs kubia # 删除一个名为kubia的rs
注意,当你删除RC或者RS时,对应的pod也会被删除,如果你不想删除pod,可以添加如下参数:
kubectl delete rs kubia --cascade=false # 删除名为kubia的rs,但保持pod运行
2 Deployment
假设通过RS创建和管理了一些pod,作为应用的v1版本,接下来如果开发了新的应用版本v2,想用这个新版本替换原来的版本,这个过程就是版本的滚动更新问题。一般来说,更新应用有两种方式:
- 删除(停用)现有的v1版本的pod,然后创建新的v2版本的pod
- 创建新的pod,等待新pod运行之后,再删除旧pod(可以一次性创建新pod,一次性删除旧pod,也可以分批创建新pod,分批逐步删除旧pod)
这是最容易想到的两种方法,它们各有优劣。第一种方法会导致你的应用在一段时间内无法正常工作,直到新pod被启动;第二种方法会在一段时间内,同时运行两个版本的应用,如果在这期间涉及数据操作(比如操作数据库)可能会导致冲突。
我们可以手动操作来完成这个更新,比如按照第一种方法更新版本,只需要在RC的资源清单中修改pod模版为v2版本,RC会检测到当前没有pod匹配它的标签选择器,于是创建新的pod,此时删除旧pod就可以完成更新。也可以使用第二种方式来进行滚动更新,通过kubectl rolling-update命令进行升级。但是有一种更加高级的控制器资源Deployment,以声明的方式升级应用,而不是使用RS或者RC进行部署。
在使用Deployment时, 实际的pod是由Deployment的RC创建和管理的, 而不是由Deployment 直接创建和管理:

2.1 创建Deployment
创建Deployment与创建RC/RS并没有任何区别。Deployment也是由标签选择器、期望副本数和pod模板组成的。此外,它还包含另一个字段,指定一个部署策略,该策略定义在修改Deployment资源时应该如何执行更新。下面的清单nginx-deployment.yaml定义了一个nginx应用:
apiVersion: extensions/v1beta1 # 此为旧版本,新版本可以使用apps/v1
kind: Deployment # 定义资源类型为Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
使用该清单创建一个deployment:
kubectl create -f nginx-deployment.yaml --record
这里的--record选项会记录历史版本号,在之后的操作中非常有用,建议每次创建时都附加该选项。
创建好之后,可以通过kubectl get deployment和kubectl describe deployment 命令查看详细信息。
2.2 Deployment进行镜像的更新和回滚
只需修改Deployment资源清单中定义的pod模板,Kubernetes会自动将实际的系统状态收敛为资源中定义的状态。可以直接通过编辑yaml清单,然后使用命令kubectl apply -f来更新pod模版的镜像版本,也可以使用set image命令。
比如想要升级镜像为nginx:1.9.1版本,使用命令:
kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1
当执行完这个命令,Deployment的pod模板内的镜像会被更改为nginx:1.9.1,这是一个滚动更新的过程,在幕后会创建一个新的ReplicaSet然后慢慢扩容,同时之前版本的Replicaset会慢慢缩容至0。如果通过如下命令查看新旧RS
kubectl get rs
会发现新创建的RS,同时旧的RS也会被保留。所有操作都在Deployment资源上完成,底层的RS只是实现的细节。即RS的创建由k8s自动管理的,并不需要用户去关心。这样通过Deployment管理的好处是,不需要处理与维护多个RS,只需要管理单个Deployment就好了。
如果你的新版本应用出现故障,很可能需要进行回滚升级,此时没有被删除的旧RS就派上用场了:Deployment始终保持着升级的版本
历史记录。历史版本号会被保存在ReplicaSet中。滚动升级成功后,老版本的ReplicaSet也不会被删掉,这也使得回滚操作可以回滚到任何一个历史版本,而不仅仅是上一个版本。可以使用kubectl rollout history命令查看每次升级版本所执行的命令:
$ kubectl rollout history deployment nginx-deployment
REVISION CHANGE-CAUSE
2 kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1
如果创建Deployment时没有指定--record参数,这里的CHANGE-CAUSE一栏会为空,这会使用户很难辨别每次的版本做了哪些修改。
通过undo来实现回滚:
kubectl rollout undo deployment/nginx-deployment
由于可能需要的回滚操作,因此不应该手动删除旧RS:如果这么做便会丢失Deployment的历史版本记录而导致无法回滚。但是如果旧RS过多会使RS列表看起来十分混乱,因此deployment通过revisionHistoryLimit属性来限制历史版本数量。默认值是2,正常情况下在版本列表里只有当前版本和上一个版本。
2.3 通过Deployment扩容缩容
和RS/RC一样,只需要更改资源清单中期望的pod副本数目即可,可以直接修改yaml文件,然后kubectl apply -f,也可以直接通过命令:
kubectl scale deployment nginx-deployment --replicas=10
上述命令将名为nginx-deployment期望的副本数目更改为10。
2.4 Deployment更新策略
Deployment的默认更新策略是执行滚动更新RollingUpdate,另一种策略为Recreate它会一次性删除所有旧版本的pod, 然后创建新的pod。在默认的滚动更新策略下,升级过程中pod数量可以在期望副本数的一定区间内浮动, 并且其上限和下限是可配置的。如果应用能够支持多个版本同时对外提供服务, 则推荐使用这个策略来升级应用。
你可以在资源清单中定义更新策略:
spec:
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: O
type: RollingUpdate
这里要介绍一下RollingUpdate策略下的两个属性:
- maxSurge最大峰值:决定了Deployment配置中期望的副本数之外,最多允许超出的pod实例的数量。此值可以是绝对数(如5)或百分比(如10%)。默认值为25% ,所以pod实例最多可以比期望数量多25% 。如果期望副本数被设置为4,那么在滚动升级期间不会运行超过4+4*25%=5个pod,如果设置为绝对数,比如2,那么在滚动升级期间不会运行超过4+2=6个pod。
- maxUnavailable最大不可用:决定了在滚动升级期间,相对于期望副本数能够允许有多少pod实例处于不可用状态。此值可以是绝对数(如5)或百分比(如10%)。默认值为25%。如果期望副本数设置为4 ,并且百分比为25%,那么只能有4*25%=1个pod处于不可用状态。即在整个更新过程中,必须保持至少有三个pod实例处于可用状态来提供服务。
3 DaemonSet
使用RS可以在Kubernetes集群上运行部署特定数量的pod,但是,你可能希望pod在集群中的每个节点上运行时(并且每个节点都需要正好一个运行的pod实例) ,类似于守护进程,比如每个节点的日志记录、资源监控等等。
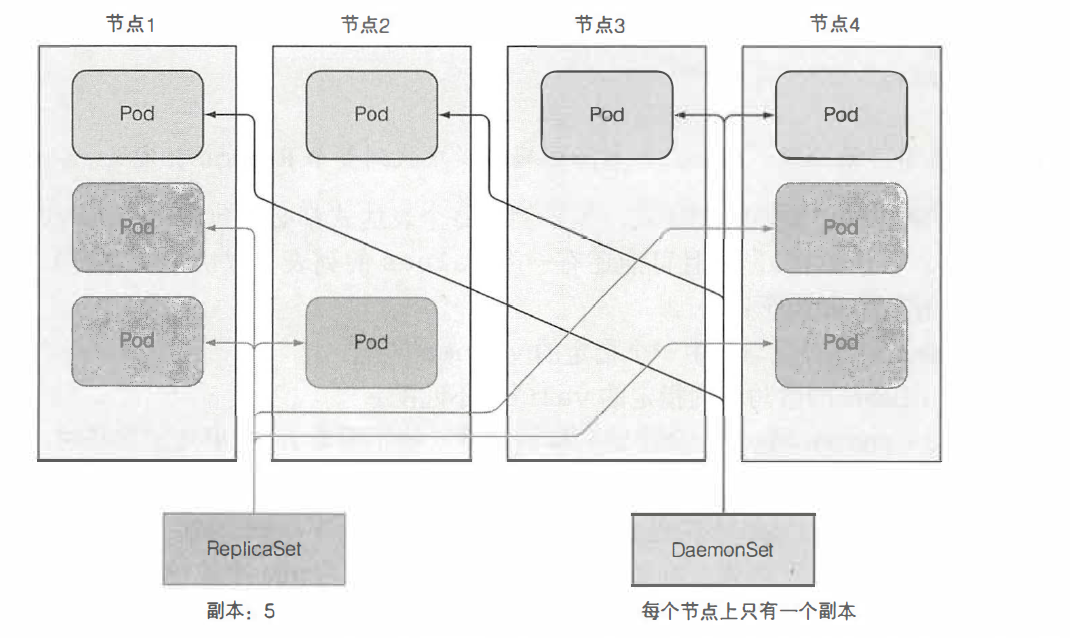
上图展示了RS和DaemonSet的区别,DaemonSet在每个节点上最多只运行一个pod副本,而RS则将它们随机地分布在整个集群中。另外,DaemonSet没有期望副本数的概念,它只需要保证一个pod匹配它的选择器并在每个节点上运行。
DaemonSet确保全部(或者某些)节点上运行一个Pod的副本。 当有节点加入集群时, 也会为他们新增一个Pod 。当有节点从集群移除时,这些Pod也会被回收。删除DaemonSet将会删除它创建的所有Pod。
如果节点下线,DaemonSet不会在其他地方重新创建pod。但是,当将一个新节点添加到集群中时,DaemonSet会立刻部署一个新的pod实例。如果有人无意中删除了一个pod,那么它也会重新创建一个新的pod。与RS一样,DaemonSet从配置的pod模板创建pod。
3.1 创建一个DaemonSet
你可以在资源清单yaml文件中描述DaemonSet。它和定义RS/RC/Deployment没有太大区别:
apiVersion: apps/v1
kind: DaemonSet # 资源类型为DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels: # 标签选择器
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
使用该清单创建一个DaemonSet,同样使用命令kubectl create -f即可。
3.2 DaemonSet在特定节点运行pod
DaemonSet默认将pod部署到集群中的所有节点上,除非指定这些pod只在部分节点上运行。通过在pod模版中nodeSelector参数来指定:
apiVersion: apps/v1
kind: DaemonSet # 资源类型为DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels: # 标签选择器
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
nodeSelector:
disk: ssd # pod模板包含一个节点选择器,会选择有disk=ssd标签的节点
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
接下来,由于指定了nodeSelector参数,pod只会在指定标签的节点创建,所以我们要给节点打上标签:
kubectl label node k8s-node-1 disk=ssd
4 Job
到目前为止,我们只谈论了需要持续运行的pod。但是可能会遇到只想运行完成工作后就终止任务的清况。RS/RC/DaemonSet都会持续运行任务,永远达不到完成态,这些pod中的进程在退出时会重新启动。但是在一个可完成的任务中,其进程终止后,不应该再重新启动。
Kubernetes通过Job提供了对此的支持。它允许你运行一种pod,该pod在内部进程成功结束时,不重启容器。一旦任务完成,pod就被认为处于完成状态。在发生节点故障时,该节点上由Job管理的pod将按照RS的pod的方式,重新安排到其他节点。如果进程本身异常退出(进程返回错误退出代码时),可以将Job配置为重新启动容器。
4.1 创建一个Job
下面是一个Job配置示例:
apiVersion: batch/v1
kind: Job
metadata:
name: myjob
# 可以不指定标签选择器,它将根据pod模版中的标签创建
spec:
template:
metadata:
labels: myjob
spec:
containers:
- name: example
image: example
restartPolicy: Never # Job中Pod的重启策略只能设置为Never或OnFailure之一。
你可以通过命令kubectl create -f即可创建Job。此外,通过kubectl get job可以查看资源信息。
4.2 在Job中运行多个pod实例
作业可以配置为创建多个pod实例, 并以并行或串行方式运行它们。这是通过在Job资源清单中设置completions和parallelism属性来完成的。
apiVersion: batch/v1
kind: Job
metadata:
name: myjob
# 可以不指定标签选择器,它将根据pod模版中的标签创建
spec:
parallelism: 2 # 标志并行运行的Pod的个数,默认为1
completions: 2 # 标志Job结束需要成功运行的Pod个数,默认为1
activeDeadlineSeconds: 100 # 标志失败Pod的重试最大时间,超过这个时间不会继续重试
template:
metadata:
labels: myjob
spec:
containers:
- name: example
image: example
restartPolicy: Never # Job中Pod的重启策略只能设置为Never或OnFailure之一。
关于Job的更多信息,比如Job的模式、Job清理、Job终止,详见官方文档。
5 CronJob
CronJob和Job类似,它用于执行周期性的动作,比如安排Job定期运行或在将来某个时间运行一次。应用场景比如定时备份、检查更新、报告生成等。这些任务中的每一个都应该配置为周期性重复的(例如:每天/每周/每月一次)。
5.1 创建一个CronJob
下面的CronJob资源清单会在每分钟打印出当前时间和问候消息:
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *" # 指定任务运行周期,Cron语法
jobTemplate: # Job 模板,指定需要运行的任务,格式同 Job
spec:
template:
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
使用kubectl create -f创建这个CronJob,它会开始执行。
5.2 Cron时间表语法
schedule里的格式叫做时间表语法,下面是它的简单介绍:
# 时间表从左到右包含以下五个条目
# ┌───────────── 分钟 (0 - 59)
# │ ┌───────────── 小时 (0 - 23)
# │ │ ┌───────────── 月的某天 (1 - 31)
# │ │ │ ┌───────────── 月份 (1 - 12)
# │ │ │ │ ┌───────────── 周的某天 (0 - 6)(周日到周一;在某些系统上,7 也是星期日)
# │ │ │ │ │
# │ │ │ │ │
# │ │ │ │ │
# * * * * *
比如:0 * * * *代表每小时的开始一次,0 0 1 1 *代表每年1月1日的午夜运行一次。
如果你担心自己写的Cron语法出错,可以在网上找到很多在线生成器,使用它们会更加方便:
5.3 CronJob Spec
-
.spec.schedule:调度,必需字段,指定任务运行周期 -
.spec.jobTemplate:Job 模板,必需字段,指定须要运行的任务 -
.spec.startingDeadlineSeconds:启动 Job 的期限(秒级别),该字段是可选的。过了截止时间,CronJob 就不会开始任务。 不满足这种最后期限的任务会被统计为失败任务。如果该域没有声明,那任务就没有最后期限。例如,如果将其设置为200,则 Job 控制器允许在实际调度之后最多 200 秒内创建 Job。 -
.spec.concurrencyPolicy:并发策略,该字段也是可选的。它指定了如何处理被 Cron Job 建立的 Job 的并发执行。只容许指定下面策略中的一种。-
Allow(默认):CronJob 允许并发任务执行。 -
Forbid: CronJob 不允许并发任务执行;如果新任务的执行时间到了而老任务没有执行完,CronJob 会忽略新任务的执行。 -
Replace:如果新任务的执行时间到了而老任务没有执行完,CronJob 会用新任务替换当前正在运行的任务。 -
注意,当前策略只能应用于同一个 Cron Job 建立的 Job。若是存在多个 Cron Job,它们建立的 Job 之间老是容许并发运行。
-
-
.spec.suspend:挂起,该字段也是可选的。- 若是设置为
true,后续全部执行都会被挂起。 - 它对已经开始执行的 Job 不起做用。默认值为
false。
- 若是设置为
-
.spec.successfulJobsHistoryLimit和.spec.failedJobsHistoryLimit:历史限制,是可选的。它们指定了能够保留多少完成和失败的 Job。默认设置为3和1。限制设置为0代表相应类型的任务完成后不会保留。
5.4 删除CronJob
要删除CronJob只需要使用delete命令即可,比如删除名为example的CronJob:
kubectl delete cronjob example
删除CronJob会清除它创建的所有任务和Pod,并阻止它创建额外的任务。
本文来自博客园,作者:yyyz,转载请注明原文链接:https://www.cnblogs.com/yyyzyyyz/p/15754841.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号