脑裂
九、脑裂
1 解决脑裂问题
脑裂这个词描述的是这样的一个场景:(通常是在重负荷或网络存在问题时)elasticsearch集群中一个或者多个节点失去和主节点的通信,然后各节点就开始选举新的主节点,继续处理请求。这个时候,可能有两个不同的集群在相互运行着,这就是脑裂一词的由来,因为单一集群被分成了两部分。为了防止这种情况的发生,我们就需要设置集群节点的总数,规则就是节点总数除以2再加一(半数以上)。这样,当一个或者多个节点失去通信,小老弟们就无法选举出新的主节点来形成新的集群。因为这些小老弟们无法满足设置的规则数量。
我们通过下图来说明如何防止脑裂。比如现在,有这样一个5个节点的集群,并且都有资格成为主节点:
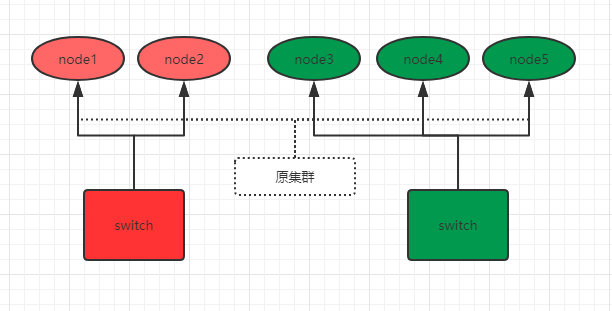
为了防止脑裂,我们对该集群设置参数:
discovery.zen.minimum_master_nodes: 3 # 3=5/2+1
之前原集群的主节点是node1,由于网络和负荷等原因,原集群被分为了两个switch:node1 、2和node3、4、5。因为minimum_master_nodes参数是3,所以node3、4、5可以组成集群,并且选举出了主节点node3。而node1、2节点因为不满足minimum_master_nodes条件而无法选举,只能一直寻求加入集群,要么网络和负荷恢复正常后加入node3、4、5组成的集群中,要么就是一直处于寻找集群状态,这样就防止了集群的脑裂问题。
除了设置minimum_master_nodes参数,有时候还需要设置node_master参数,比如有两个节点的集群,如果出现脑裂问题,那么它们自己都无法选举,因为都不符合半数以上。这时我们可以指定node_master,让其中一个节点有资格成为主节点,另外一个节点只能做存储用。当然这是特殊情况。
那么,主节点是如何知道某个节点还活着呢?这就要说到错误识别了。
2 错误识别
其实错误识别,就是当主节点被确定后,建立起内部的ping机制来确保每个节点在集群中保持活跃和健康,这就是错误识别。主节点ping集群中的其他节点,而且每个节点也会ping主节点来确认主节点还活着,如果没有响应,则宣布该节点失联。想象一下,老大要时不常的看看(循环)小弟们是否还活着,而小老弟们也要时不常的看看老大还在不在,不在了就赶紧再选举一个出来!
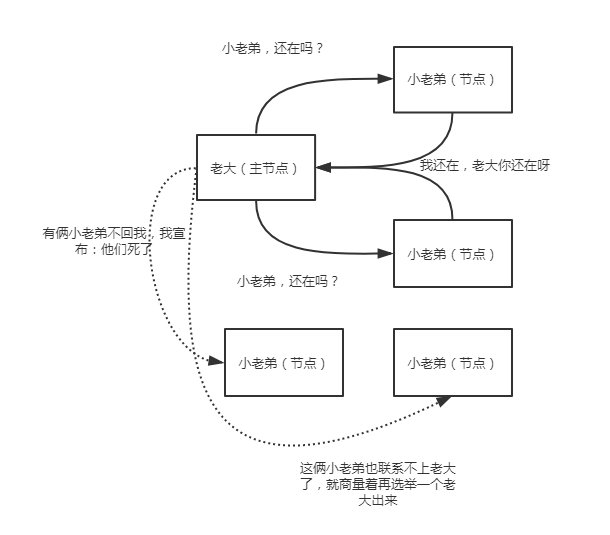
但是,多久没联系算是失联?这些细节都是可以设置的,不是一拍脑门子,就说某个小老弟挂了。在配置文件中,可以设置:
discovery.zen.fd.ping_interval: 1
discovery.zen.fd.ping_timeout: 30
discovery_zen.fd.ping_retries: 3
每个节点每隔discovery.zen.fd.ping_interval的时间(默认1秒)发送一个ping请求,等待discovery.zen.fd.ping_timeout的时间(默认30秒),并尝试最多discovery.zen.fd.ping_retries次(默认3次),无果的话,宣布节点失联,并且在需要的时候进行新的分片和主节点选举。根据开发环境,适当修改这些值。
本文来自博客园,作者:yyyz,转载请注明原文链接:https://www.cnblogs.com/yyyzyyyz/p/15700677.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号