爬虫作业 (学号尾号2)
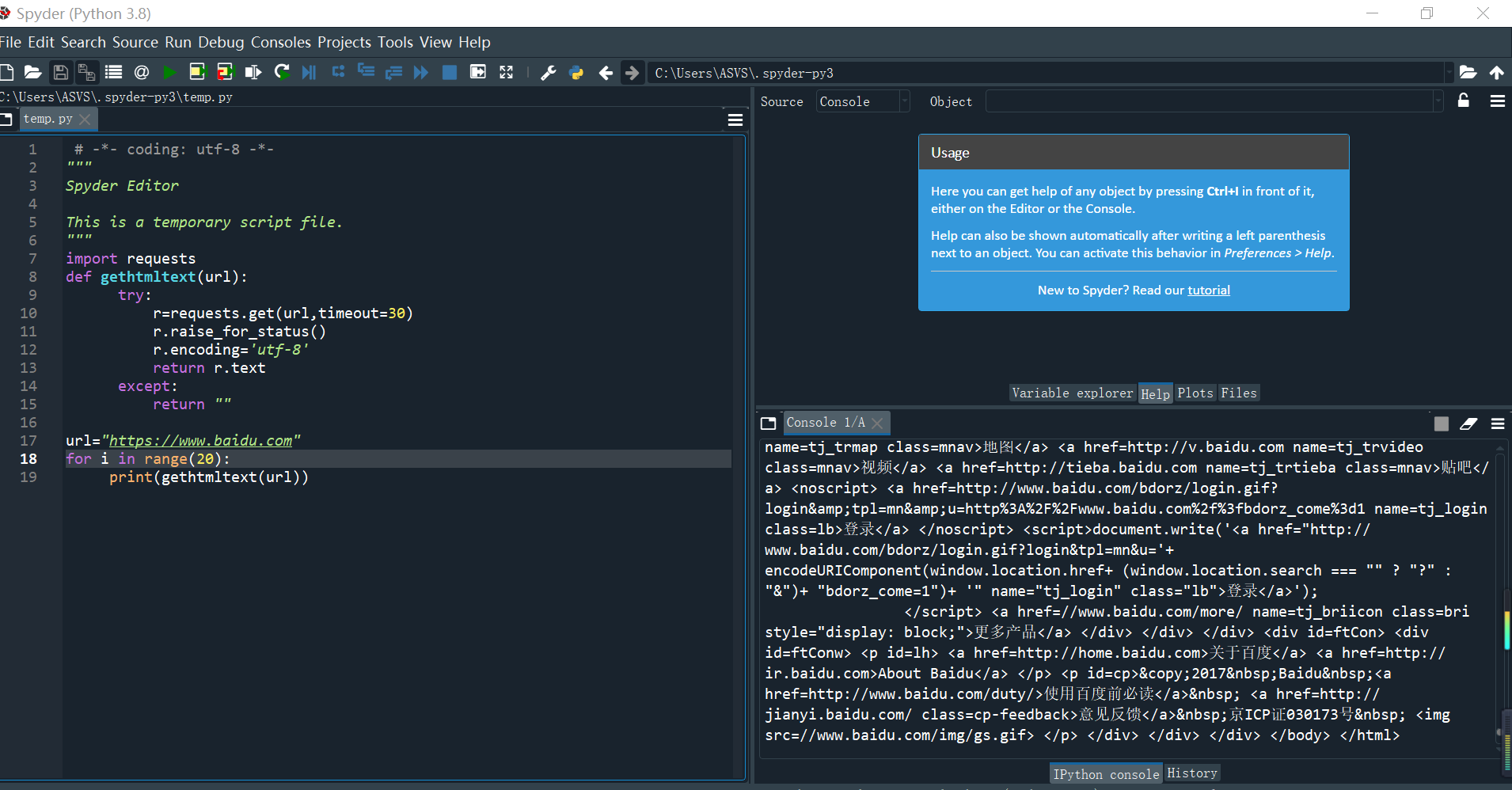
(1)百度主页
import requests
def gethtmltext(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding='utf-8'
return r.text
except:
return ""
url="https://www.baidu.com"
for i in range(20):
print(gethtmltext(url))
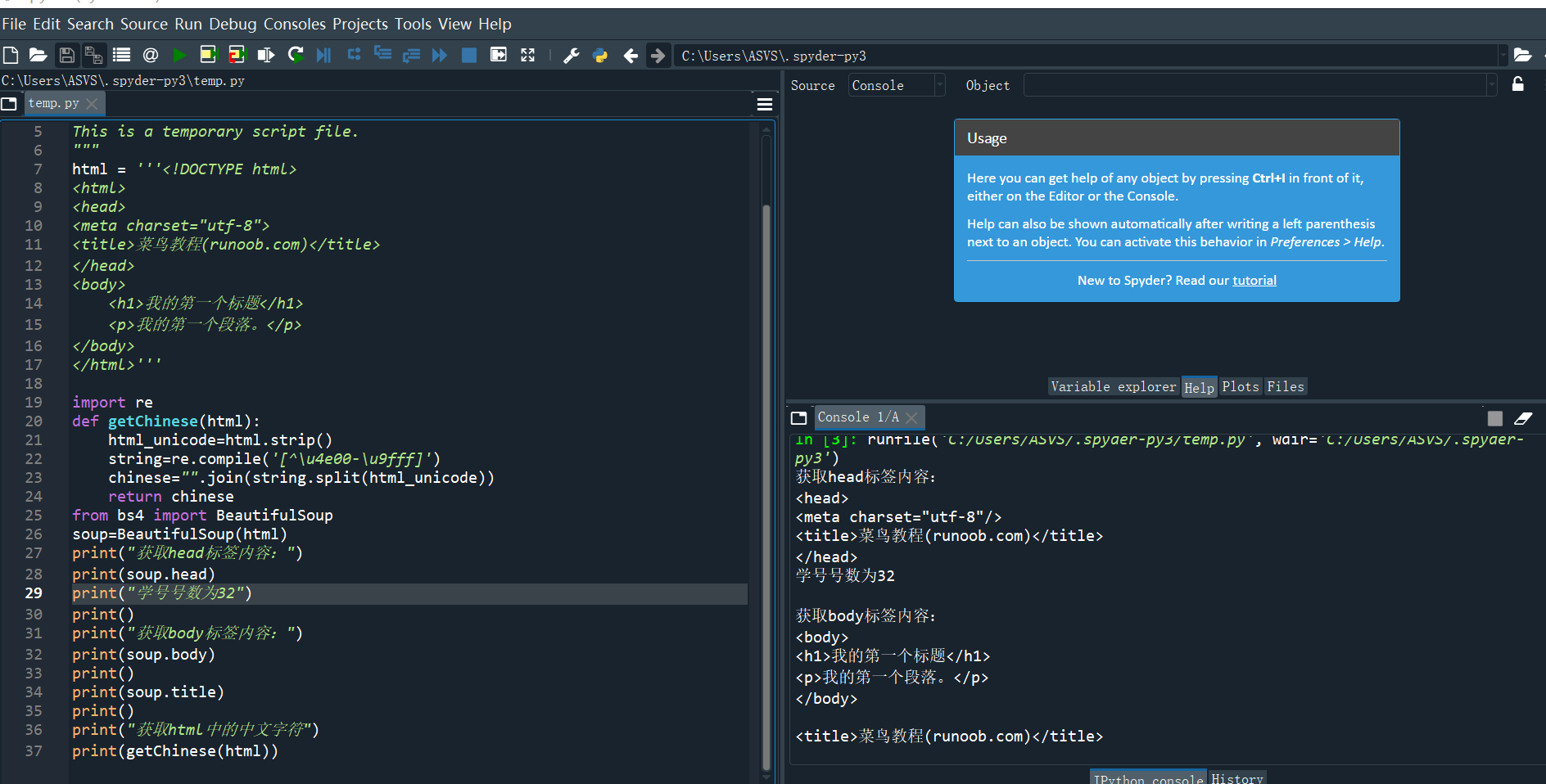
(2)这是一个简单的html页面,请保持为字符串,完成后面的计算要求。
html = '''<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>菜鸟教程(runoob.com)</title>
</head>
<body>
<h1>我的第一个标题</h1>
<p>我的第一个段落。</p>
</body>
</html>'''
import re
def getChinese(html):
html_unicode=html.strip()
string=re.compile('[^\u4e00-\u9fff]')
chinese="".join(string.split(html_unicode))
return chinese
from bs4 import BeautifulSoup
soup=BeautifulSoup(html)
print("获取head标签内容:")
print(soup.head)
print("学号号数为32")
print()
print("获取body标签内容:")
print(soup.body)
print()
print(soup.title)
print()
print("获取html中的中文字符")
print(getChinese(html))
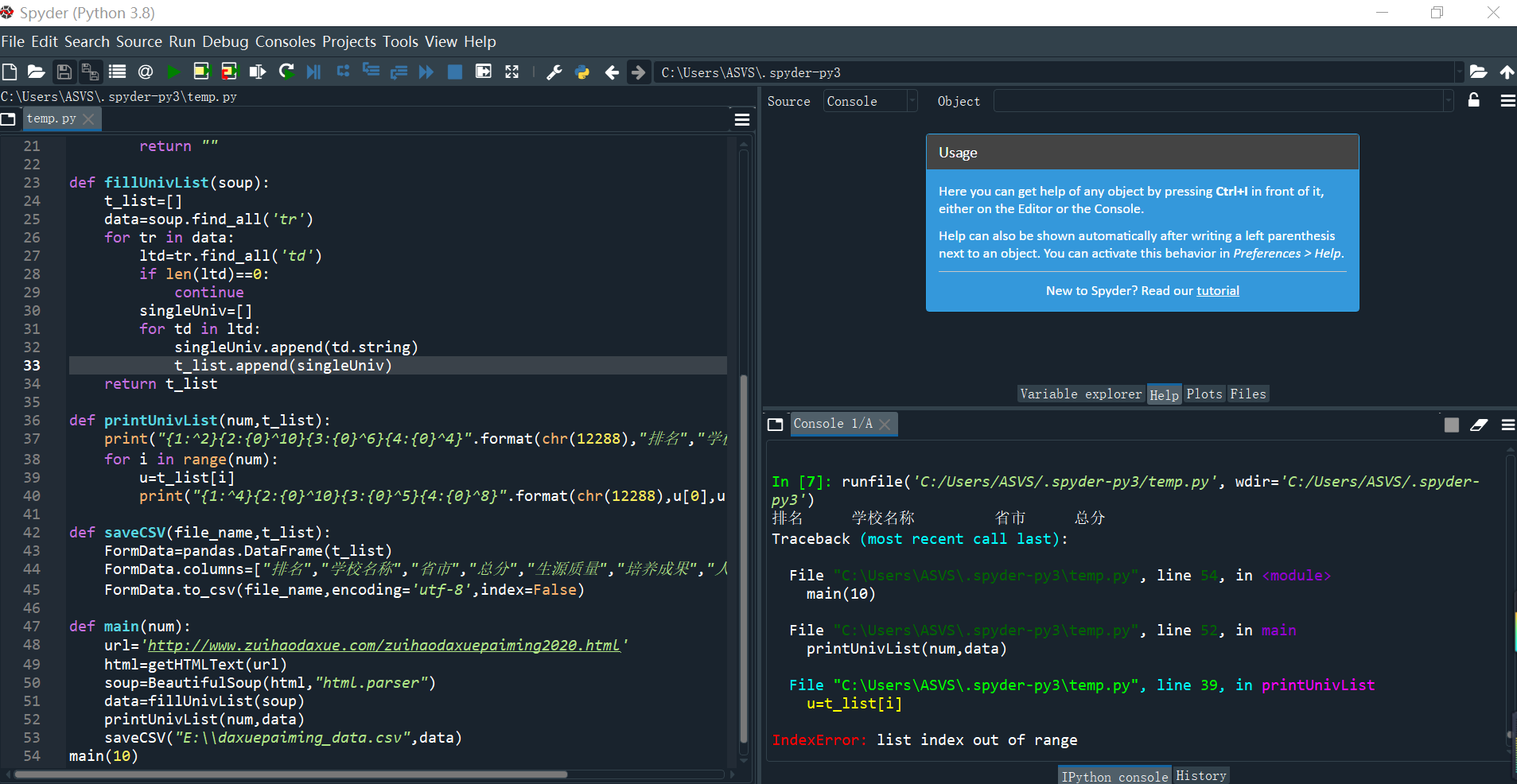
(3) 爬中国大学排名网站内容(2020年)
'''
爬取中国大学排名
author:xiayiLL
'''
import requests
from bs4 import BeautifulSoup
import pandas
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding='utf-8'
return r.text
except:
return ""
def fillUnivList(soup):
t_list=[]
data=soup.find_all('tr')
for tr in data:
ltd=tr.find_all('td')
if len(ltd)==0:
continue
singleUniv=[]
for td in ltd:
singleUniv.append(td.string)
t_list.append(singleUniv)
return t_list
def printUnivList(num,t_list):
print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^4}".format(chr(12288),"排名","学校名称","省市","总分"))
for i in range(num):
u=t_list[i]
print("{1:^4}{2:{0}^10}{3:{0}^5}{4:{0}^8}".format(chr(12288),u[0],u[1],u[2],eval(u[3])))
def saveCSV(file_name,t_list):
FormData=pandas.DataFrame(t_list)
FormData.columns=["排名","学校名称","省市","总分","生源质量","培养成果","人才培养得分"]
FormData.to_csv(file_name,encoding='utf-8',index=False)
def main(num):
url='http://www.zuihaodaxue.com/zuihaodaxuepaiming2020.html'
html=getHTMLText(url)
soup=BeautifulSoup(html,"html.parser")
data=fillUnivList(soup)
printUnivList(num,data)
saveCSV("E:\\daxuepaiming_data.csv",data)
main(10)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号