re模块:
import re
s = """
eva jason tony yuan
jason jason
jason a
"""
# ret = re.findall('j.*?n', s) # 返回所有满足匹配条件的结果,放在列表里
# print(ret)
"""
findall(正则,文本数据)
在匹配的时候是全局匹配不会因为匹配到一个就停止
返回的结果是一个列表 内部包含正则匹配到的所有的内容
"""
# 暂时了解
# res = re.finditer('j.*?n', s)
# for i in res:
# print(i.group())
"""
finditer(正则,文本数据)
返回的结果是一个迭代器(更加节省内存) 只有主动索要才会产生数据 否则永远只占一块空间
"""
# 匹配到一个符号条件的数据就结束
# res = re.search('j.*?n', s)
# print(res)
# 只能从头开始匹配 头部不符合直接停止
# res1 = re.match('j.*?n', s)
# print(res1)
import re
ret = re.findall('www.(oldboy).com', 'www.oldboy.com')
print(ret)
"""
findall分组优先展示
会优先展示括号内正则表达式匹配到的内容
"""
ret1 = re.findall('www.(?:oldboy).com', 'www.oldboy.com')
print(ret1)
# 取消分组优先展示
ret2 = re.findall('www.(?:oldboy).com', 'www.oldboy.com')
print(ret2)
# ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com')
# print(ret)
爬虫模块之requests:
# 作用
可以模拟浏览器发送网络请求获取数据
# 先下载
pip3 install requests
1.切换源(自己网上搜索pip源,换为国内的,加快下载速度)
2.针对报错(找关键词,并寻求解决方法)
,
# 再导入
import requests
网络请求方法:
网络方法一般有八个之多 但是目前需要我们掌握的只有两个
# get请求
朝别人索要数据
eg:浏览器地址栏输入百度网址回车其实就是在发送get请求朝百度服务器索要百度首页
get请求也可以携带额外的数据 但是数据量有限制最多2~4KB 并且是直接写在网址的后面
url?xxx=yyy&zzz=mmm
# post请求
朝别人提交数据
eg:用户注册登录需要输入用户名和密码,之后点击按钮发送post请求,将数据提交给远程服务器
post请求也可以携带额外的数据,并且数据大小没有限制,敏感性的数据都是由post请求携带
数据放在请求体中
HTTP协议 :
# 规定了浏览器与服务端之间数据交互的方式
1.四大特性(重要)
1.基于请求响应
2.基于TCP、IP作用于应用层之上的协议
3.无状态 # 一直发送一直响应,刚响应完就忘
不保存客户端的状态
4.无连接
2.数据请求格式(重要) # 请求头和请求体,响应头和响应体之间一定要空一行!!!
请求数据格式
请求首行(请求方法 地址...)
请求头(一大堆K:V键值对)
请求体(get请求没有请求体 post请求有 里面是敏感数据)
响应数据格式
响应首行(响应状态码 协议版本...)
响应头(一大堆K:V键值对)
响应体(一般都是给浏览器展示给用户看的数据)
3.响应状态码(重要)
用简单的数字来表示一串中文意思(制定暗号)
1XX:服务端已经成功接收到了你的数据正在处理 你可以继续提交或者等待
2XX:200 OK请求成功,服务端发送了响应
3XX:重定向(原本想访问A页面但是内部自动跳到了B页面) # 跳转外部链接
4XX:403 请求不符合条件,404 请求资源不存在
5XX:服务器内部错误
"""
公司还会自己自定义响应状态码(HTTP的状态码太少不够用)
10001
10002
参考网址:聚合数据
"""
requests模块基本使用:
发送网络请求
import requests
requests.get(url) # 发送get请求
requests.post(url) # 发送post请求
# 1.简单的get请求获取页面并报错
import requests
# 朝百度发送get请求获取首页数据
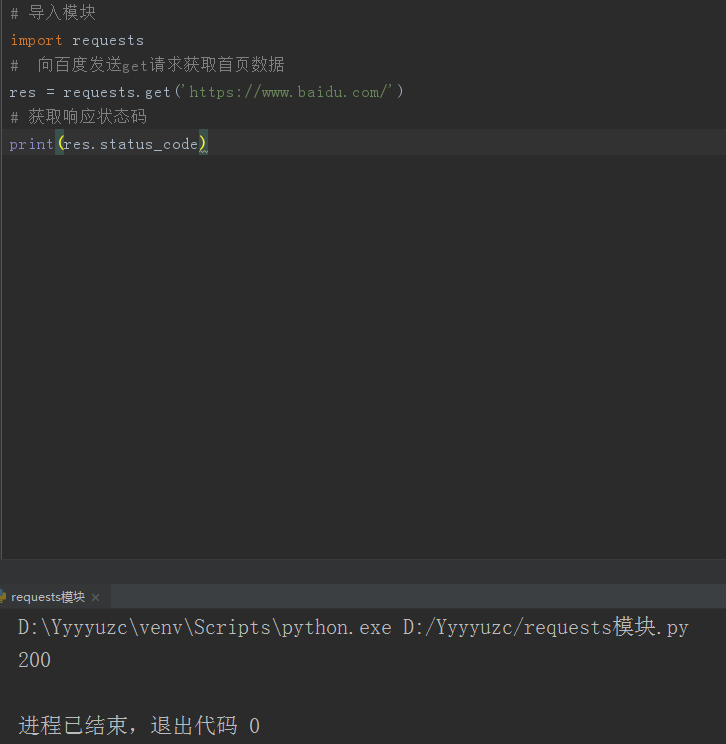
res = requests.get('https://www.baidu.com/')
# print(res.status_code) # 获取响应状态码,如下图所示
# 指定字符编码
# print(res.text) # 获取网页字符串数据,如下图 所示(爬取数据出现乱码是因为字符编码不对,如下方红线所划,于是要在此命令前加上一行 res.encoding = 'utf8')
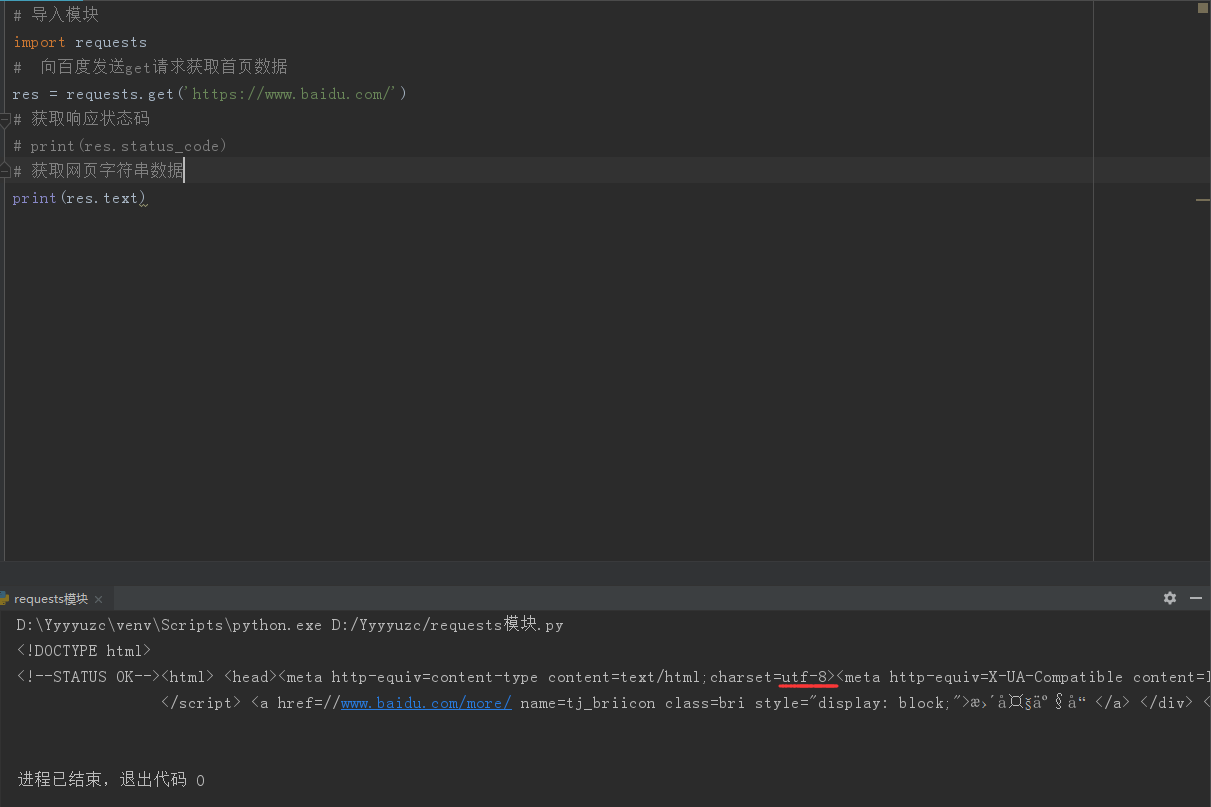
# 输出结果即为下图 所示

# print(res.content) # 获取bytes类型的数据(在python中可以直接看成是二进制)
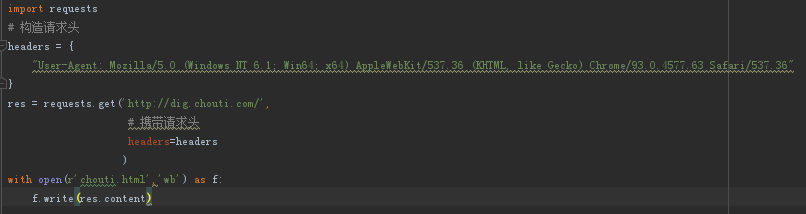
with open(r'baidu.html', 'wb') as f:
f.write(res.content)
# 将获取的数据保存,名为baidu.html
# 2.携带参数的get请求
requests.get(url,params={})
# 3.如何携带请求头数据
requests.get(url,headers={})
防爬措施:
# 基于爬虫来说,会增加网页负担且爬取数据,所以一般情况下,网站都备有防爬措施。(如下图所示,为最基础的防爬)

# 解决方法如图 所示
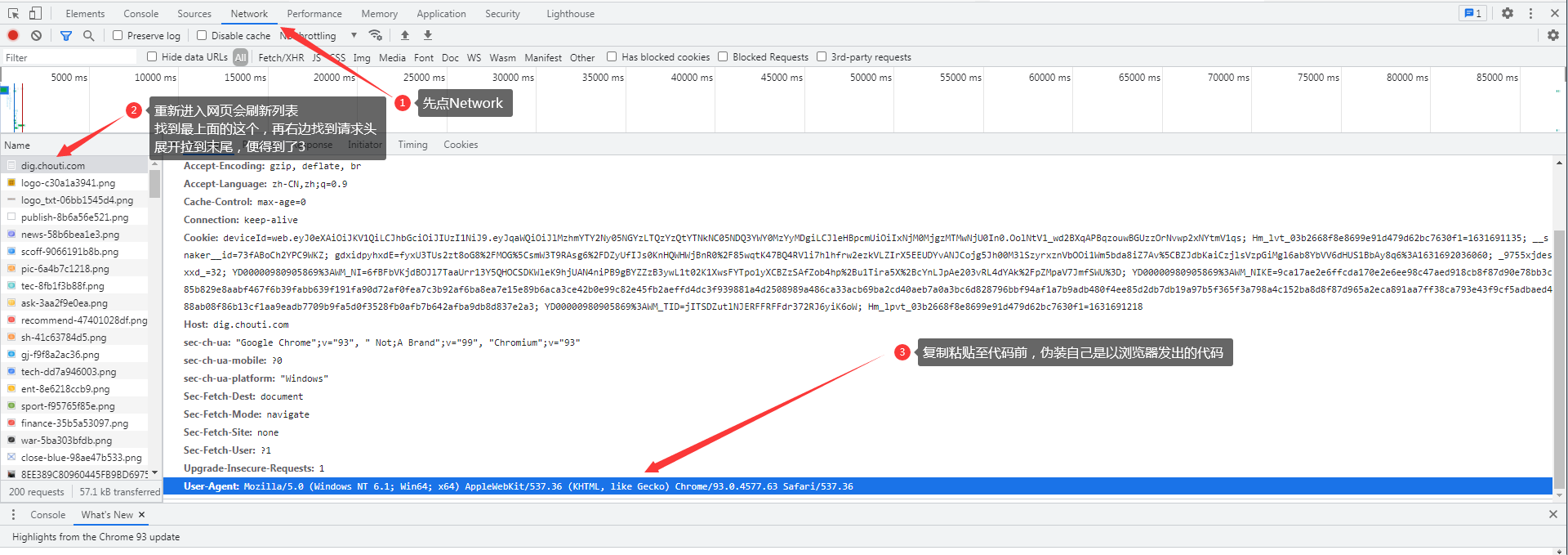
1.校验当前请求是否是浏览器发出的
用于校验的核心就在于请求头里面的User-Agent键值对
只要请求里面含有该键值对就表示你是个浏览器没有则不是浏览器
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36
解决措施在请求头中加上即可
requests.get(url,headers={...})
# 如图所示