DO447学习笔记
DO447----高级自动化:可靠的最佳实践
课程内容摘要
• 了解高效实用地使用 Ansible 实现自动化的推荐做法。
• 借助 Ansible 自动化操作执行滚动更新。
• 使用 Ansible 的高级功能来处理数据,包括过滤器和插件。
• 借助 Ansible Playbook,通过 REST API 控制应用。
• 实施红帽 Ansible Tower,以集中协调和扩展红帽 Ansible 自动化。
• 利用红帽 Ansible Tower 的功能来管理复杂的自动化工作流。
• 借助 Git 和红帽 Ansible Tower,实现 CI/CD 业务流程自动化。
******借助 Ansible Playbook,通过 REST API 控制应用******
在Firefox浏览器中,访问https://tower.lab.example.com/api/。你应该看到你的Ansible Tower服务器的可浏览API。
【 job_templates": "/api/v2/job_templates/" 】
JSON-PP必须安装:
[student@workstation ~]$ sudo yum install perl-JSON-PP
[student@workstation ~]$ curl -X GET --user admin:redhat https://tower.lab.example.com/api/v2/job_templates/?name="Demo Job Template" -k -s |json_pp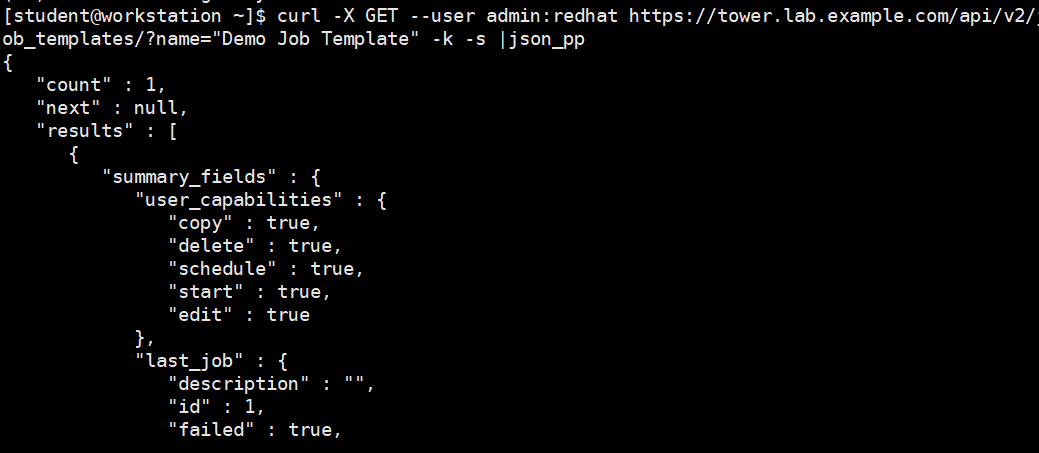
用python3:
[student@workstation ~]$ curl -X GET --user admin:redhat https://tower.lab.example.com/api/v2/job_templates/?name="Demo Job Template" -k -s |python3 -m json.tool
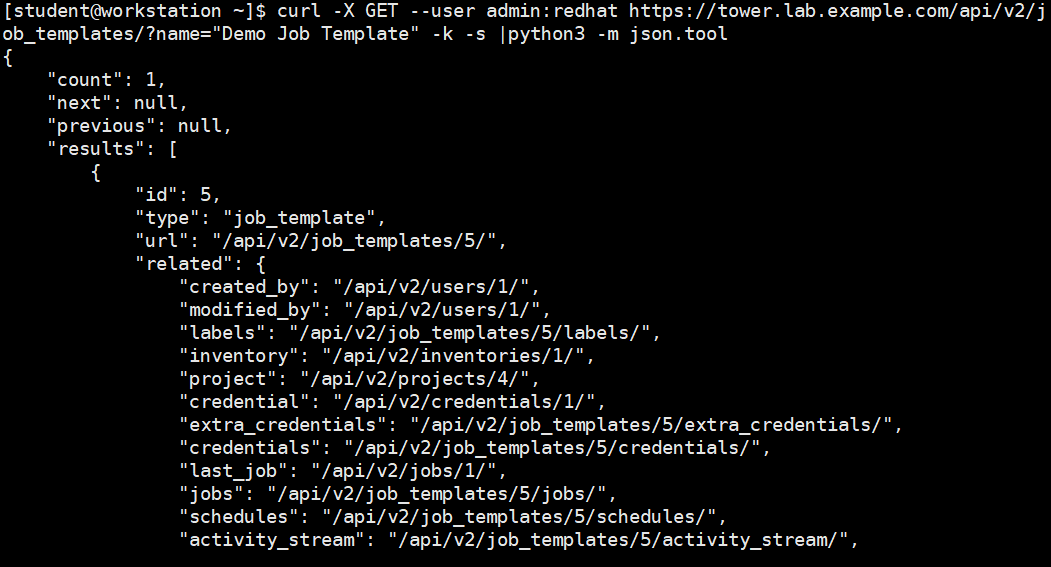
对于这个命令,-k(--insecure)选项指示curl操作,即使它不能验证SSL证书。使用 -s(--silent)选项,curl只显示返回的数据,而不显示进度状态或错误消息。
切换分支:
[student@workstation my_webservers_DEV]$ git branch
* master
[student@workstation my_webservers_DEV]$ git branch development
[student@workstation my_webservers_DEV]$ git branch
development
* master
[student@workstation my_webservers_DEV]$ git checkout development
Switched to branch 'development'
[student@workstation my_webservers_DEV]$ git branch
* development
master
大多数清单插件在默认情况下是禁用的。你可以在你的ansible.cfg配置文件中启用特定的插件,在inventory部分的enable_plugins指令中:
[inventory]
enable_plugins = host_list, script, auto, yaml, ini, toml
[lb_servers]
servera.lab.example.com
[web_servers]
serverb.lab.example.com
serverc.lab.example.com
[backend_server_pool]
server[b:f].lab.example.com
转换成yml文件格式
lb_servers:
hosts:
servera.lab.example.com:
web_servers:
hosts:
serverb.lab.example.com:
serverc.lab.example.com:
backend_server_pool:
hosts:
server[b:f].lab.example.com:
清单变量:
基于yaml的清单文件中直接设置清单变量,就像在基于inil的清单文件中一样。
变量及其值存储在清单的host_vars或group_vars文件中。
在一个基于ini的静态清单文件中,可以将主机localhost的ansible_connection变量设置为local,如下所示:

基于yaml的静态清单文件:

-------------------设置变量-----------------
* 在角色的defaults和vars目录中。
* 在清单文件中,可以作为主机变量或组变量。
* 在playbook或inventory的group_vars或host_vars子目录下的变量文件中。
* 在play, role, task中
--------------变量的精确优先级列表从低到高:---------
1 直接设置在清单文件或动态清单脚本中的组变量。
2 在清单的group_vars/all文件或子目录中设置所有变量组。
3 对剧本的group_vars/all文件或子目录中的所有设置的变量进行分组。
4 为清单的group_vars子目录中设置的其他组的变量分组。
5 为剧本的group_vars子目录中设置的其他组的变量分组。
6 主机变量直接设置在清单文件或由一个动态清单脚本。
7 主机变量设置在清单的host_vars子目录中。
8 在playbook的host_vars子目录中设置主机变量。
9 宿主事实和缓存事实。
-----------------------剧本变量的优先级列表从低到高:-------
1 剧本的vars部分设定的。
2 通过在剧本中使用vars_prompt部分提示用户来设置。
3 通过剧本的vars_files部分从外部文件列表中设置。
4 通过角色的rolename/vars/子目录中的文件设置。
5 为当前块设置一个vars部分。
6 设置当前任务的vars部分。
7 用include_vars模块动态加载。
8 通过使用set_fact模块或使用register来记录任务在主机上执行的结果来为特定的主机设置。
9 在剧本中的角色部分或使用include_role模块加载时为剧本中的角色设置的参数。
10 由include_tasks模块中包含的任务的vars部分设置。
* include_vars加载的变量具有较高的优先级,可以覆盖为角色和特定块和任务设置的变量。在许多情况下,如果不希望用外部变量文件覆盖这些值,则可能希望使用vars_files代替。
* set_fact模块和register指令都设置了特定于主机的信息,要么是一个事实,要么是任务在该主机上执行的结果。
* Extra变量使用ansible-playbook命令的-e选项设置的额外变量总是具有最高的优先级
##### ansibl变量的优先级 #####
1. extra vars变量(在命令行中使用 -e);优先级最高
2. 在inventory中定义的连接变量(比如ansible_ssh_user);优先级第二
3. 大多数的其他变量(命令行转换,play中的变量,include的变量,role的变量等);优先级第三
4. 在inventory定义的其他变量;优先级第四
5. 有系统发现的facts;优先级第五
6. "role默认变量",这个是最默认的值,很容易丧失优先权。优先级最小。
##### inventory清单列表里定义变量:单个主机定义的变量优先级高于主机组定义的变量 #####
ansible使用inventory定义变量的优先级顺序从高到低为:
1. host_vars下定义变量
2. inventory中单个主机定义变量
3. group_vars下定义变量
4. inventory中组定义变量
--------------------官网中的定义:----------(从低到高)
1. command line values (for example, -u my_user, these are not variables)
2. role defaults (defined in role/defaults/main.yml)
3. inventory file or script group vars
4. inventory group_vars/all
5. playbook group_vars/all
6. inventory group_vars/*
7. playbook group_vars/*
8. inventory file or script host vars
9. inventory host_vars/*
10. playbook host_vars/*
11. host facts / cached set_facts
12. play vars
13. play vars_prompt
14. play vars_files
15. role vars (defined in role/vars/main.yml)
16. block vars (only for tasks in block)
17. task vars (only for the task)
18. include_vars
19. set_facts / registered vars
20. role (and include_role) params
21. include params
22. extra vars (for example, -e "user=my_user")(always win precedence)
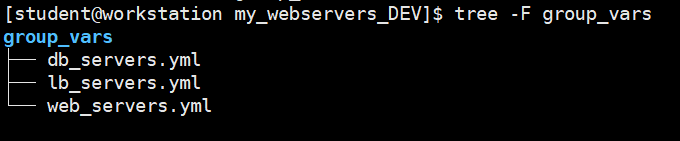
---> 更好的方法是将变量定义从清单文件移动到单独的变量文件中,每个主机组一个变量文件。每个变量文件以主机组命名,包含主机组的变量定义:
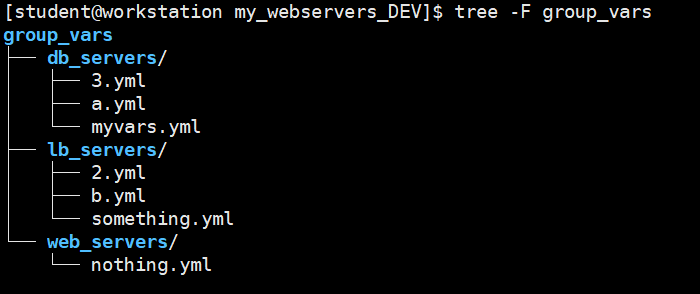
---> 一种更好的方法是在group_vars目录下为每个主机组创建子目录。Ansible解析这些子目录中的任何YAML,并根据父目录将变量与主机组关联:
2.2.4 特殊清单变量
ansible_connection: 用于访问托管主机的连接插件。缺省情况下,除了使用local的localhost,所有主机都使用ssh。
ansible_host: 连接到托管主机时要使用的实际IP地址或完全限定域名,而不是使用清单文件中的名称(inventory_hostname)。默认情况下,这个变量的值与清单主机名相同。
ansible_port: Ansible用于连接被管理主机。对于(默认的)SSH连接插件,值默认为22。
ansible_user: Ansible以这个用户连接到被管理的主机。Ansible的默认行为是使用与在控制节点上运行Ansible Playbook的用户相同的用户名连接到托管主机。
ansible_become_user: Ansible连接到托管主机,它将使用ansible_become_method(默认为sudo)切换到该用户。您可能需要以某种方式提供身份验证凭据。
ansible_python_interpreter: Ansible应该在托管主机上使用的Python可执行文件的路径。在Ansible2.8及以后版本,默认为auto,
2.2.5 使用变量识别当前主机
inventory_hostname: 当前正在处理的托管主机的名称,从清单中获取。
ansible_host: 用于连接受管理主机的实际IP地址或主机名。
ansible_facts['hostname'] : 作为事实从托管主机收集的短主机名。
ansible_facts['fqdn'] : 作为事实从托管主机收集的完全合格域名(FQDN)。
-----------------------管理任务执行---------------------------
提权升级指令::
become、become_user、become_method、become_flags。
配置特权升级::
如果将Ansible配置文件的[privilege_escalation]部分中的become布尔值设置为yes(或true),那么剧本中的所有剧本将默认使用privileqe_escalation。当运行在被管理的主机上时,这些play将使用当前的become_method方法切换到当前的become_user。
| CONFIGURATION DIRECTIVE | COMMAND-LINE OPTION |
| become | --become or -b |
| become_method | --become-method=BECOME_METHOD |
| become_user | --become-user=BECOME_USER |
| become_password | --ask-become-pass or -k |
剧本的特权升级:
第一个play中使用:become:true
连接变量的特权升级:
连接变量来配置特权升级。这些连接变量可以作为组或单个主机上的清单变量应用。
| configuration or playbook directive | CONNECTION VARIABLE |
| become | ansible_become |
| become_method | ansible_become_method |
| become_user | ansible_become_user |
| become_password | ansible_become_pass |
--------------特权升级方法----------
. 让你的剧本保持简单(Ansible最佳实践的关键原则)是首要的考虑。
. 其次要考虑的是,在可能的情况下以最小权限运行任务(以避免由于playbook错误而导致托管主机的意外损害)。
-------------控制任务执行-----------
--- - name: Ensure Apache is deployed hosts: localhost gather_facts: no tasks: - name: Open the firewall *******Ansible 会在打开防火墙之前执行角色的任务,
即使任务部分是先定义 firewalld: service: http permanent: yes state: enabled roles: - role: apache
pre_tasks :是在roles部分之前运行的tasks部分
post_tasks: 是在一个tasks部分之后运行的
------------------------执行顺序----------------------
Ansible按以下顺序运行play部分:
1 pre_tasks
2 pre_tasks部分中通知的处理程序
3 角色
4 任务
5 角色和任务部分中通知的处理程序
6 post_tasks
7 post_tasks 部分中通知的处理程序
--- - name: Testing host order hosts: localhost order: sorted ********order指令接受以下值**** tasks: - name: Createing a test file in /tmp copy: content: "This is a sample file" dest: /tmp/test.out
order指令接受的值:
1、inventory :清单order 这是默认值
2、reverse_inventory: 清单order的倒序
3、 sorted: 主机按字母顺序倒序排列
4、 revers_sorted: 主机按字母顺序
5、shuffle: 每次运行play时都是随机顺序
-----------标签ANSIBLE资源------------------
当使用ansible-playbook运行一个playbook时,
---->使用 --tags选项来过滤这个playbook,并只执行特定的带标签的play或任务。
---->使用 --skip-tags选项跳过带有特定标记的任务。
--- - name: Example play using tagging hosts: - servera.lab.example.com - serverb.lab.example.com tasks: - name: httpd is installed yum: name: httpd state: latest tags: webserver <----tags标签 - name: postfix is installed yum: name: postfix state: latest
[student@workstation yuan]$ ansible-playbook t1.yml --tags webserver <----运行标签处
[student@workstation yuan]$ ansible-playbook t1.yml --list-tags <----列出剧本中所有的标签
特殊标签:
(1) Ansible有一个特殊的方法,可以在剧本中分配:always.。标记了always的资源将始终运行,即使它与传递给 --tags的标签列表不匹配。唯一的例外是使用 --skip-tags always选项显式跳过它。
(2) never特殊标记标记的任务不会运行,除非您将 --tags选项设置为never或与该任务关联的另一个tag运行playbook。
三个额外的特殊tag:
(1) tagged的标记将使用显式标记运行任何资源。
(2) 未标记的tag将运行任何没有显式tag的资源,并排除所有标记的资源。
(3) all tag将包含play中的所有任务,无论他们是否有tag。这是Ansible的默认行为。
------------------变量类型----------------
字符串(字符序列)
数字(数值)
布尔值(真/假)
日期(ISO-8601日历日期)
Null(设置变量为未定义的变量)
列表或数组(值的排序集合)
字典(键值对的集合)
YAML格式允许定义多行字符串,使用pipe操作符(|)来保留换行符,
使用大于操作符(>)来抑制换行符。
string_with_breaks: |
This string
has several
line breaks
string_without_breaks: >
This string will not
contain any line breaks.
Separated lines are joined
by a space character.
字典:也称为映射或散列,是一种将字符串键与值链接起来以便直接访问的结构
my_dict: { Douglas: Human, Marvin: Robot, Arthur: Human }
my_dict:
Douglas: Human
Marvin: Robot
Arthur: Human
通过键来访问字典中的项,在字典名后面立即提供键,并用方括号括起来:
assert:
that:
- my_dict['Marvin'] == 'Robot'
-------------用过滤器处理数据-------------
下面的表达式对变量myname的值进行过滤,通过使用标准的Jinja2过滤器确保值的第一个字母大写:
{{ myname | capitalize }}
- name: Test to see if the assertion assert: that: - "{{ [1,4,2,2] | unique | sort }} is eq([1,2,4])"
Jinja2中正式可用的过滤器:
http://jinja.pocoo.org/docs/2.10/templates/#builtinfilters上记录的Jinja2过滤器提供了大量有用的实用函数。(https://jinja.palletsprojects.com/en/2.10.x/templates/#builtinfilters)(http://docs.jinkan.org/docs/jinja2/templates.html#id2)
mandatory:
如果变量没有定义值,则会失败并中止Ansible剧本。
{{ my_value | mandatory }}
default
如果变量没有定义值,那么这个过滤器将把它设置为括号中指定的值。如果括号中的第二个参数是True,那么如果变量的初始值是空字符串或布尔值False,过滤器也会将该变量设置为默认值。
{{ my_value | default(my_default, True) }}
提起列表元素:
- name: All three of these assertions are true assert: that: - "{{ [ 2, 4, 6, 8, 10, 12 ] | length }} is eq( 6 )" ---length 列表长度 - "{{ [ 2, 4, 6, 8, 10, 12 ] | first }} is eq( 2 )" ---first 列表第一个 - "{{ [ 2, 4, 6, 8, 10, 12 ] | last }} is eq( 12 )" ---last 列表的最后一个
random(随机)过滤器从列表中返回一个随机元素:
{{ ['Douglas', 'Marvin', 'Arthur'] | random }}
- name: reversion and sorting lists assert: that: - "{{[2,4,6,8,10] | reverse |list }}is eq([10,8,6,4,2])" ---把列表颠倒过来 - "{{[4,8,10,6,2] | sort|list}} is eq([2,4,6,8,10])" ---把列表顺序排列
合并列表:flatten过滤器递归地接受输入列表值中的任何内部列表
- name: Flatten turns nested lists on the left to list on the right assert: that: - "{{ [2,[4,[6,8]],10] | flatten }} is eq([2,4,6,8,10])" ---flatten合并列表
将列表作为集合进行操作:unique 唯一过滤器,
- name: unique leaves unique elements assert: that: --unique保证唯一,---list列表转成集合 - "{{ [1,1,2,2,2,3,4,4]|unique|list }}is eq([1,2,3,4])"
如果两个列表没有重复的元素,那么你可以对它们使用集合理论操作。
union联合过滤器返回一个集合,其中包含来自两个输入集合的元素。
intersect过滤器返回一个集合,该集合具有两个集合共有的元素。
difference过滤器返回一个集合,其中包含第一个集合中不存在于第二个集合中的元素。
- name: difference assert: that: -----difference 第一个集合中有的,第二个集合中没有的 - "{{[2,4,6,8,10] | difference([2,4,6,16])}} is eq([8,10])"
操纵字典:
字典是没有任何顺序的。它们只是键值对的集合。但是您可以使用过滤器来构造字典,并且您可以将它们转换为列表,或者将列表转换为字典。
- name: combine vars: expected: a: 234 b: 456 c: 890 assert: that: ----combine 字典联合起来 - "{{ {'a':234,'b':456} | combine({'b':456,'c':109 }) }} is eq(expected)"
重塑字典:
使用dict2items过滤器可以将一个字典重新塑造成一个条目列表,使用items2dict过滤器也可以将一个条目列表重新塑造成一个字典
- name: converting vars: c1: do1: Human do2: Robot do3: Human c2: - key: d1 value: Human - key: d3 value: Human ---dict2items 把列表转换成字典 assert: ---items2dict 把字典转换成列表 that: - "{{ c1 | dict2items }} is eq(c2)" - "{{ c2 | items2dict }} is eq(c1)"
对字符串进行哈希、编码和操作:hash哈希过滤器使用提供的哈希算法返回输入字符串的哈希值:
- name: SHA-1 hash vars: e1: '9ka0ka0akdfj912klkjasd334cal' assert: that: - "'{{ 'Arthur' | hash('sha1')}}' is eq(e1)"
使用password_hash过滤器来生成密码散列:
{{ 'secret_password'| password_hash('sha512')}}
编码的字符串
二进制数据可以通过b64encode过滤器转换成base64,再通过b64decode过滤器转换回二进制格式。
- name: Base64 assert: that: - "'{{ 'asdfkl'| b64encode }}'is eq('w8LDkkjj==')" - "'{{ 'w8kjsjd==' | b64encode }}'is eq('asdfkl')"
格式化文本
使用lower、upper或capitalize过滤器来强制输入字符串的大小写:
- name: cc assert: that: - "'{{ 'Marvin' | lower }}'is eq('marvin')" --全部转换为小写 - "'{{ 'Marvin' | upper }}'is eq('MARVIN')" --全部转换为大写 - "'{{ 'marvin' | capitalize }}'is eq('Marvin')" --首字母转换为大写
替换文本
当你需要替换输入字符串中出现的所有子字符串时,replace过滤器很有用:
- name: Replace assert: that: ---replace 替换 - "'{{ 'marvin, arthur' | replace('ar','**')}}'is eq('m**vin,**thur')"
更复杂的搜索和替换可以通过使用正则表达式和regex_search和regex_replace过滤器来实现。

解析和编码数据结构
数据结构通过to_json和to_yaml过滤器序列化为JSON或YAML格式。使用to_nice_json和to_nice_yaml过滤器来获得格式化的人类可读输出。
- name: Convert JSON and YAML format vars: hosts: - name: bastion ip: - 172.25.250.254 - 172.25.252.1 hosts_json: '[{"name":"bastion","ip":["172.25.250.254","172.25.252.1"]}]' assert: that: - "'{{ hosts | to_json}}'is eq(hosts_json)"
4.3 实现高级循环
使用循环迭代任务可以帮助简化您的Ansible Playbooks。loop关键字在项目的平面列表上循环。当与查找插件一起使用时,可以在循环列表中构造更复杂的数据。
loop关键字代替with_*样式循环有以下好处:
不需要记忆或找到一个with * style关键字来适应您的迭代场景。相反,使用插件和过滤器来使循环关键字任务适应您的用例。
重点学习Ansible中可用的插件和过滤器,它们的适用性比迭代更广泛。
可以通过ansible-doc -t lookup命令对查找插件文档进行命令行访问。这将帮助发现查找插件并使用它们设计自定义迭代场景。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号