


代码
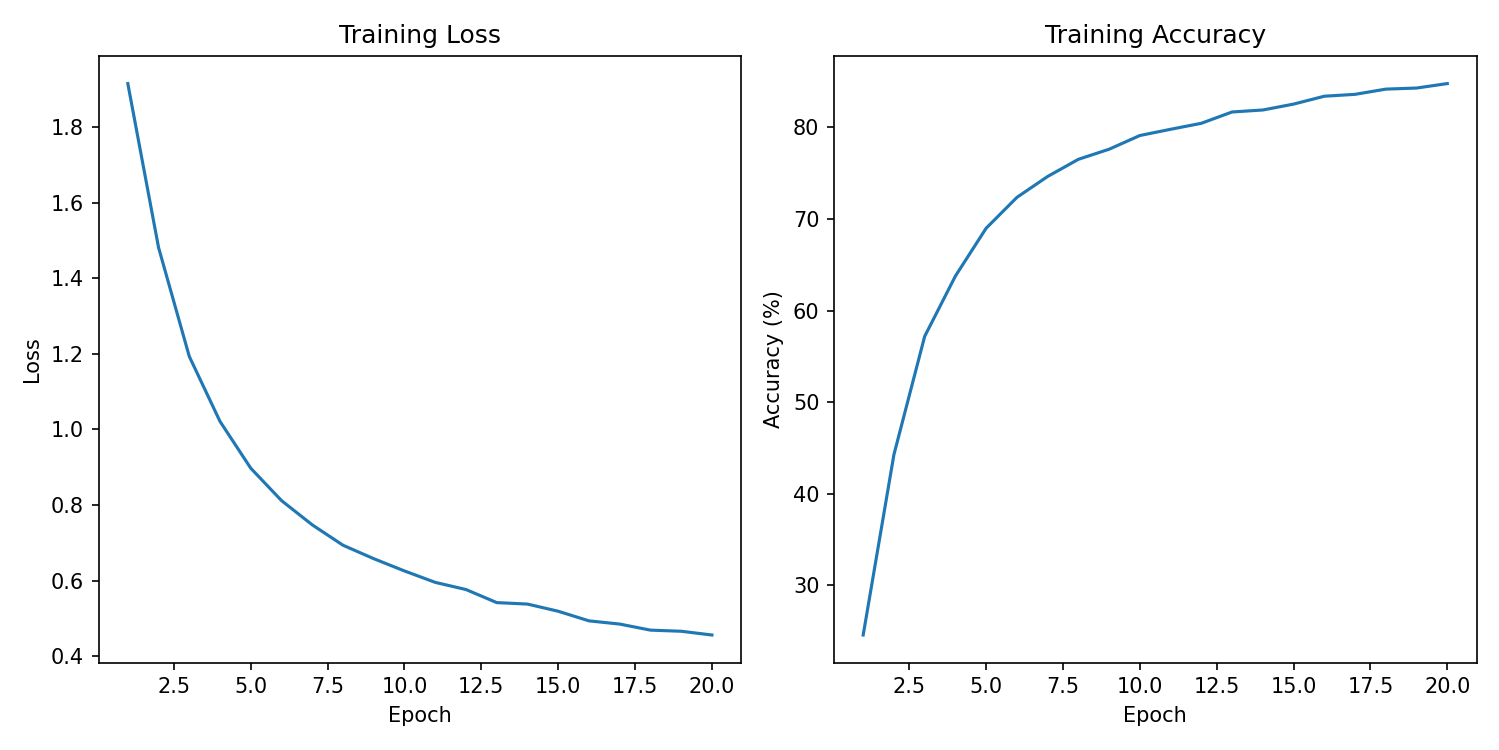
import torch from torch import optim, nn from torchvision import datasets, transforms from torch.utils.data import DataLoader import torch.nn.functional as F import numpy as np from sklearn.metrics import classification_report from PIL import Image import time from matplotlib import pyplot as plt device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') #数据加载 transform_train = transforms.Compose([ transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), ]) transform_test = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), ]) # 加载CIFAR-10数据集 def load_data(): train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train) test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test) train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=2) test_loader = DataLoader(test_dataset, batch_size=128, shuffle=False, num_workers=2) return train_loader, test_loader, test_dataset #定义MYVGG模型 class MYVGG(nn.Module): def __init__(self, num_classes=10): super(MYVGG, self).__init__() self.features = nn.Sequential( # Block 1 nn.Conv2d(3, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(64, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(2, 2), # Block 2 nn.Conv2d(64, 128, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(2, 2), # Block 3 nn.Conv2d(128, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(2, 2), # Block 4 nn.Conv2d(256, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(2, 2), # Block 5 nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(2, 2), ) self.classifier = nn.Sequential( nn.Dropout(0.5), nn.Linear(512, num_classes) ) def forward(self, x): x = self.features(x) x = x.view(x.size(0), -1) x = self.classifier(x) return x #训练函数 model = MYVGG().to(device) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) def train(model, train_loader, criterion, optimizer, epoch_num=50): model.train() train_loss = [] train_acc = [] for epoch in range(epoch_num): start_time = time.time() running_loss = 0.0 current = 0 total = 0 for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) output = model(data) loss = criterion(output, target) optimizer.zero_grad() loss.backward() optimizer.step() running_loss += loss.item() _, predicted = torch.max(output.data, 1) total += target.size(0) current += (predicted == target).sum().item() epoch_loss = running_loss / len(train_loader) epoch_acc = 100.0 * current / total train_loss.append(epoch_loss) train_acc.append(epoch_acc) end_time = time.time() print(f"Epoch [{epoch+1}/{epoch_num}], Loss: {epoch_loss:.4f}, Acc: {epoch_acc:.2f}%, Time: {end_time-start_time:.2f}s") return train_loss, train_acc #测试函数 def test(model, test_loader): model.eval() all_pred = [] all_label = [] with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) outputs = model(data) _, predicted = torch.max(outputs.data, 1) all_pred.extend(predicted.cpu().numpy()) all_label.extend(target.cpu().numpy()) all_pred = np.array(all_pred) all_label = np.array(all_label) accuracy = (all_pred == all_label).mean() accuracy = 100.0 * accuracy print(f'测试准确率: {accuracy:.4f}%') print("分类效果评估:") target_names = [str(i) for i in range(10)] report = classification_report(all_label, all_pred, target_names=target_names) print(report) if __name__ == '__main__': print(f"24信计2班 殷永琪 2024310143104") print(f"device:{device}") epoch_num = 20 train_loader, test_loader, test_dataset = load_data() train_loss, train_acc = train(model, train_loader, criterion, optimizer, epoch_num) test(model, test_loader) #绘制结果 plt.figure(figsize=(10, 5)) plt.subplot(1, 2, 1) plt.plot(range(1, epoch_num+1), train_loss) plt.title("Training Loss") plt.xlabel("Epoch") plt.ylabel("Loss") plt.subplot(1, 2, 2) plt.plot(range(1, epoch_num+1), train_acc) plt.title("Training Accuracy") plt.xlabel("Epoch") plt.ylabel("Accuracy (%)") plt.tight_layout() plt.show()
运行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号