

数据采集作业四
数据采集作业四
作业①:
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头
(1)代码如下:
import mysql.connector
def establish_db_connection_and_create_schema():
# 连接到MySQL数据库
conn = mysql.connector.connect(
host="host",
user="username",
passwd="password"
)
cursor = conn.cursor()
# 定义数据库和表名
db_name = "stock_market_data"
table_name = "shenzhen_stocks"
# 创建数据库(如果不存在)
create_db_query = f"CREATE DATABASE IF NOT EXISTS {db_name}"
cursor.execute(create_db_query)
# 使用创建的数据库
use_db_query = f"USE {db_name}"
cursor.execute(use_db_query)
# 定义表的创建语句
create_table_query = f"""
CREATE TABLE IF NOT EXISTS {table_name} (
record_id INT AUTO_INCREMENT PRIMARY KEY,
stock_number VARCHAR(255),
stock_name VARCHAR(255),
last_trade_price VARCHAR(255),
percentage_change VARCHAR(255),
change_amount VARCHAR(255),
trading_volume VARCHAR(255),
total_trading_amount VARCHAR(255),
price_range VARCHAR(255),
daily_high VARCHAR(255),
daily_low VARCHAR(255),
opening_price VARCHAR(255),
previous_close VARCHAR(255)
)
"""
# 执行表的创建语句
cursor.execute(create_table_query)
# 提交更改
conn.commit()
# 关闭游标和连接
cursor.close()
conn.close()
# 调用函数以创建数据库和表
establish_db_connection_and_create_schema()
爬取“沪深A股”、“上证A股”、“深证A股”
点击查看代码
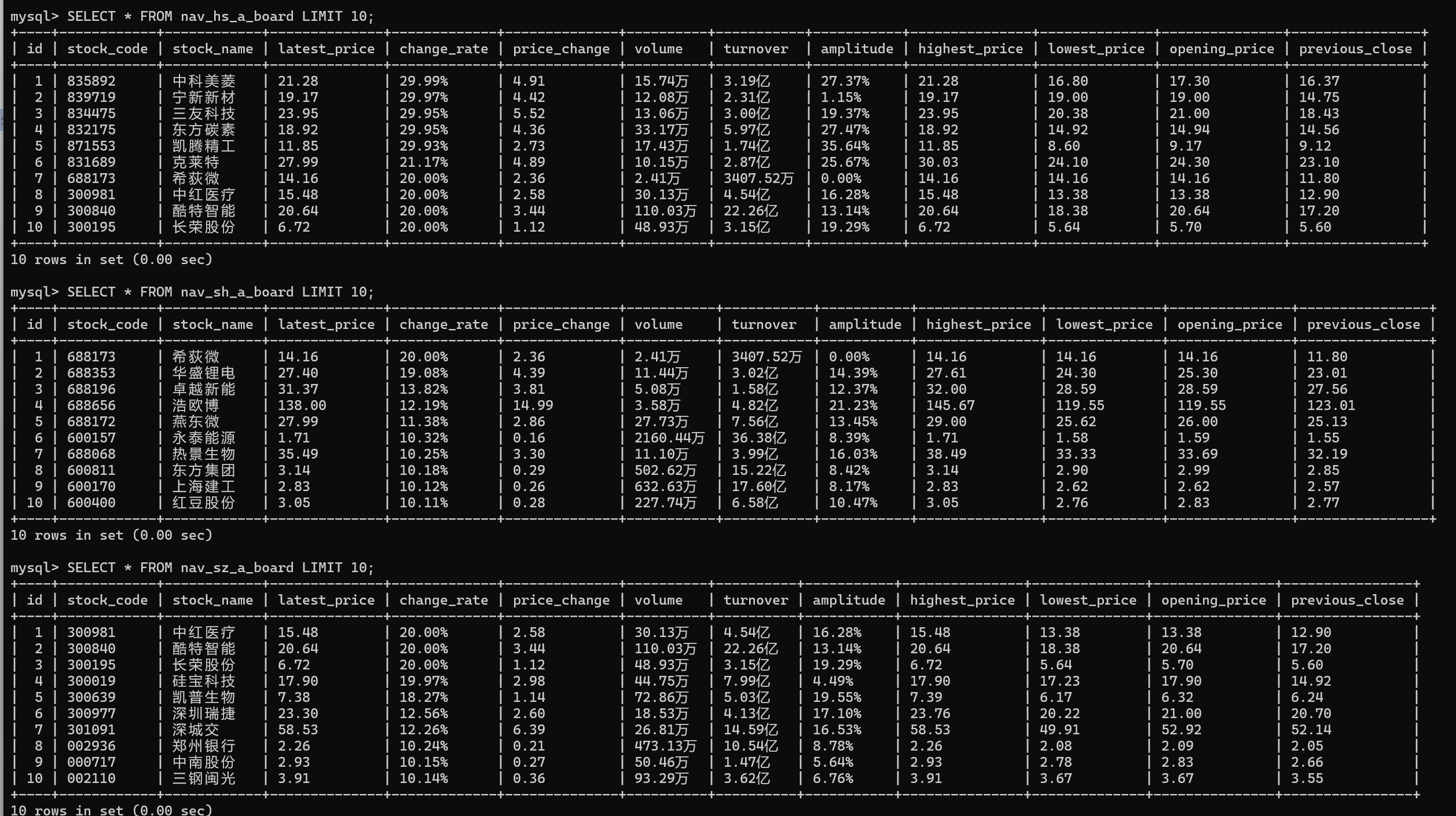
(2)运行结果
结果如下:
(3)感悟
通过这次实践,我借助 Selenium 精准定位 HTML 元素、处理 Ajax 加载、模拟用户操作,有效应对复杂网页的数据提取需求。同时,将爬取的数据存储到 MySQL 数据库中,不仅考验了数据结构设计能力,还强化了对数据库操作的理解。在这一过程中,我学会了从问题分析到代码实现的完整流程,提升了代码的鲁棒性和复用性,也对网页爬虫技术与数据库存储有了更深入的认识,为后续的数据分析与开发实践奠定了扎实的基础。
作业②:
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式
(1)代码如下:
import time
import mysql.connector
from selenium import webdriver
from selenium.webdriver.common.by import By
# 初始化数据库连接
db = mysql.connector.connect(
host="host",
user="user",
password="password",
database="database"
)
cursor = db.cursor()
# 初始化WebDriver
driver = webdriver.Chrome() # 确保已安装ChromeDriver
def wait_for_page_load():
time.sleep(5) # 等待页面加载,这里可以使用更先进的等待方法,如WebDriverWait
def scrape_course_details(course_element):
course_name = course_element.find_element(By.XPATH, './/h3').text
college_name = course_element.find_element(By.XPATH, './/p[@class="_2lZi3"]').text
teacher_name = course_element.find_element(By.XPATH, './/div[@class="_1Zkj9"]').text
participant_count = course_element.find_element(By.XPATH, './/div[@class="jvxcQ"]/span').text
progress = course_element.find_element(By.XPATH, './/div[@class="jvxcQ"]/div').text
return course_name, college_name, teacher_name, participant_count, progress
def scrape_teacher_team(driver):
teacher_names = []
next_button_xpath = '//div[@class="um-list-slider_next f-pa"]'
teacher_item_xpath = '//div[@class="um-list-slider_con_item"]/h3[@class="f-fc3"]'
while True:
teachers = driver.find_elements(By.XPATH, teacher_item_xpath)
for teacher in teachers:
teacher_names.append(teacher.text.strip())
next_button = driver.find_element(By.XPATH, next_button_xpath)
if not next_button:
break
next_button.click()
wait_for_page_load()
return ','.join(teacher_names)
def scrape_course_brief(driver):
brief_xpath = '//*[@id="j-rectxt2"]'
content_section_xpath = '//*[@id="content-section"]/div[4]/div//*'
brief = driver.find_element(By.XPATH, brief_xpath).text
if not brief:
elements = driver.find_elements(By.XPATH, content_section_xpath)
brief = ' '.join(element.text for element in elements)
# 转义引号
brief = brief.replace('"', r'\"').replace("'", r"\'")
return brief.strip()
def scrape_and_save_course_data(course_url):
driver.get(course_url)
wait_for_page_load()
course_elements = driver.find_elements(By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[1]/div')
for course_element in course_elements:
course_name, college_name, teacher_name, participant_count, progress = scrape_course_details(course_element)
course_element.click()
wait_for_page_load()
# 切换到新标签页
new_tab = [handle for handle in driver.window_handles if handle != driver.current_window_handle][0]
driver.switch_to.window(new_tab)
course_brief = scrape_course_brief(driver)
teacher_team = scrape_teacher_team(driver)
# 关闭新标签页并返回原页面
driver.close()
driver.switch_to.window(driver.window_handles[0])
try:
cursor.execute('INSERT INTO courseMessage (course_name, college_name, teacher_name, teacher_team, participant_count, progress, brief) VALUES (%s, %s, %s, %s, %s, %s, %s)', (
course_name, college_name, teacher_name, teacher_team, participant_count, progress, course_brief))
db.commit()
except mysql.connector.Error as e:
print("数据库插入数据失败:", e)
# 使用示例(假设有一个课程列表页面的URL)
course_list_url = "your_course_list_url_here"
scrape_and_save_course_data(course_list_url)
# 关闭数据库连接和WebDriver
cursor.close()
db.close()
driver.quit()
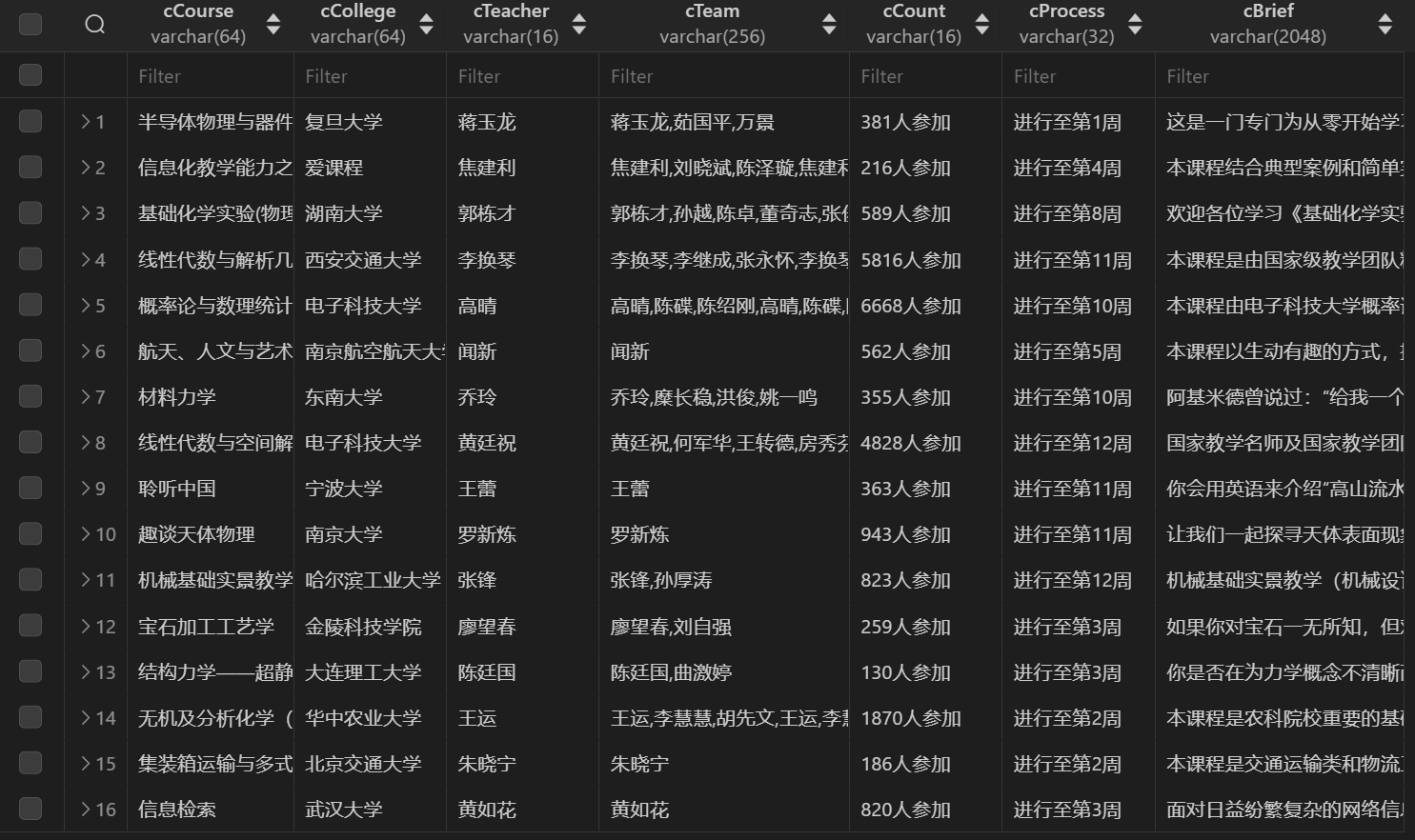
(2)结果如下
(3)感悟
结合 MySQL 数据库对爬取的数据进行存储和管理,锻炼了我在设计表结构、处理数据完整性和提高查询效率方面的能力。整个过程中,我学会了分析复杂网页结构、应对动态加载的挑战,以及如何高效地组织和持久化大规模数据,为后续更复杂的数据采集和分析任务积累了宝贵的经验。
3.华为云_大数据实时分析处理实验手册-Flume日志采集实验
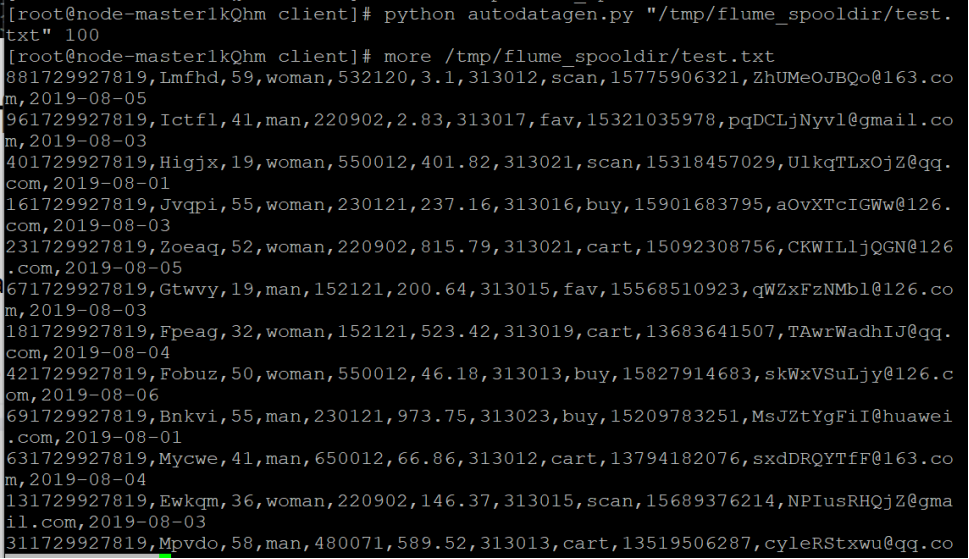
任务一:Python脚本生成测试数据
执行脚本测试
使用more命令查看生成的数据
任务二:下载安装并配置Kafka
安装Kafka运行环境
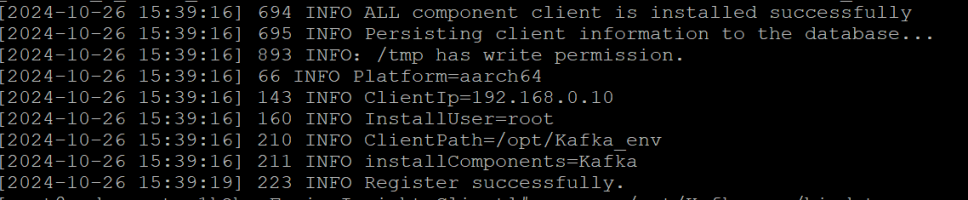
安装Kafka客户端

任务三:安装Flume客户端
安装Flume运行环境
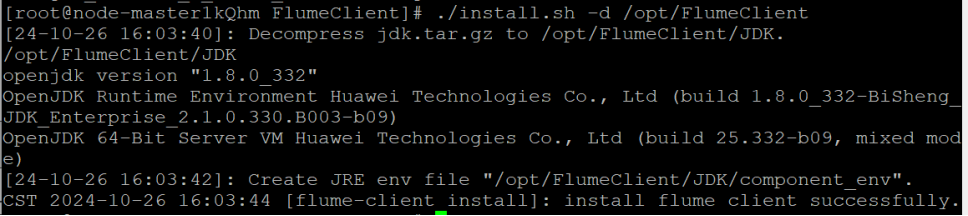
安装Flume客户端

任务四:配置Flume采集数据
修改配置文件
创建消费者消费kafka中的数据
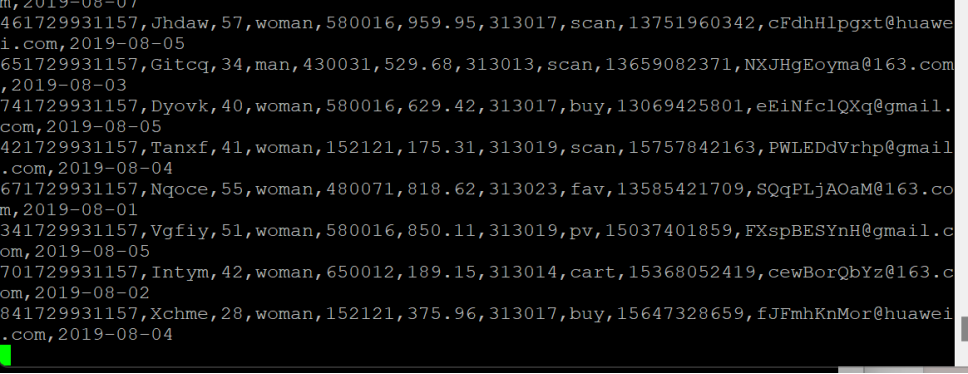
感悟
通过本次实验,进一步巩固了我对分布式数据处理的理解。这次实践让我深刻认识到流式数据处理在大数据实时分析中的重要性,同时强化了我在配置环境、处理错误、优化数据流管道等方面的能力,为日后复杂的大数据项目开发提供了宝贵的经验。
