
Restormer Efficient Transformer for High-Resolution Image Restoration——2022CVPR
大佬链接:Restormer: Efficient Transformer for High-Resolution Image Restoration - 知乎 (zhihu.com)
一. Motivation
1.CNN感受野有限,因此无法对长距离像素相关性进行建模;卷积滤波器在推理时具有静态权重,因此不能灵活地适应输入内容
2. Transformer模型缓解了CNN的缺点(有限的感受野和对输入内容的不适应性),但是self-attention在捕捉远距离像素交互方面非常有效,但其计算复杂度随着空间分辨率的增加而呈二次方增长,因此无法应用于高分辨率图像
二. Contribution
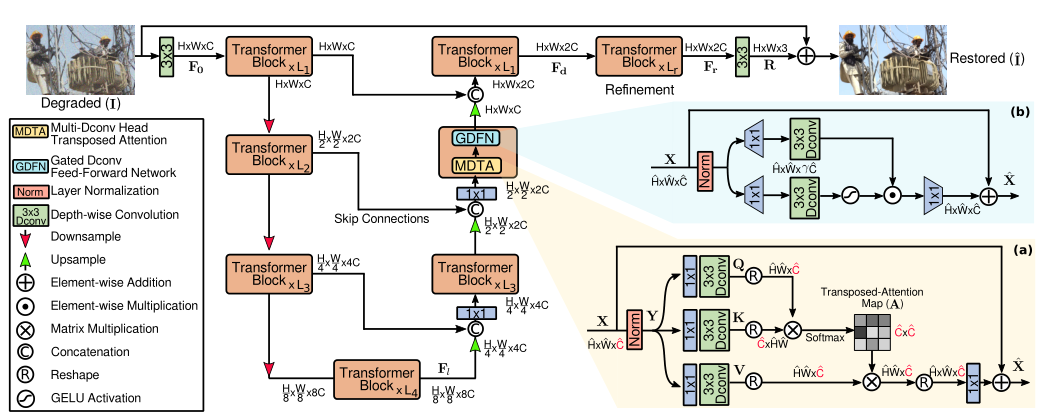
1. 提出MDTA,将Self-attention应用于通道维度而不是空间维度,计算特征通道之间的交叉协方差 ,以从(key-query projected)输入特征获得注意力图
2. 提出GDFN增加门控机制,控制哪些互补特征应该向前流动,并允许网络层次结构中的后续层专门关注更精细的图像属性,从而获得高质量的输出
三.Network

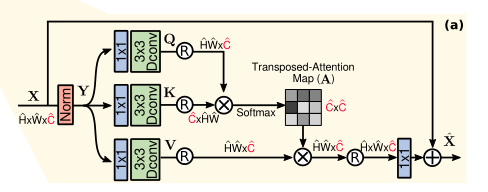
MDTA:


Gated-Dconv Feed-Forward Network(GDFN):
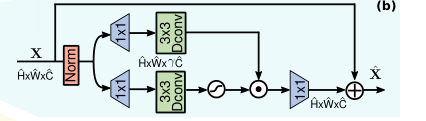

在本文中,作者进行了两个改进:
(1)gating mechanism——门控机制
被表示为线性变换层的两条平行路径的元素级乘积,其中一条通过 GELU非线性激活
(2)depth-wise convolutions
在这里依然使用了 depth-wise convolution,以对空间相邻像素位置的信息进行编码,这有助于学习局部图像结构以进行有效恢复


 浙公网安备 33010602011771号
浙公网安备 33010602011771号