


Bug记录
1. 获取GPU
model.to('cuda:0')
2. 代码跑起来之后中途卡死:调用到其他显卡 则会卡死
3. 报错:RuntimeError: cuDNN error: CUDNN_STATUS_NOT_INITIALIZED
(1)检查是否放在GUP上
(2)batch_size. num_worker
(3)这次更改了torch安装就好了....绝
pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html
4. 从git上down的代码报红线错(格式错误),可能是对齐问题
5. pixelUnshuffle支持torch版本1.8及以上,如果使用torch版本低,可以替换为
import torch.nn.functional as F def pixel_unshuffle(input, downscale_factor): batch_size, channels, height, width = input.size() unfolded = F.unfold(input, kernel_size=downscale_factor, stride=downscale_factor) # 将展开后的二维张量重塑为指定形状的三维张量 output = unfolded.view(batch_size, channels, downscale_factor ** 2, height // downscale_factor, width // downscale_factor) # 交换维度以符合输出要求的形状 output = output.permute(0, 1, 3, 2, 4).contiguous() output = output.view(batch_size, channels * downscale_factor ** 2, height // downscale_factor, width // downscale_factor) return output
6. 安装yaml时
执行
pip install pyyaml
7. 出现Cuda没有初始化的错误,安装torch的时候应该+cuda版本
错误:RuntimeError: cuDNN error: CUDNN_STATUS_NOT_INITIALIZED
解决办法:
pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html
8. ValueError: Expected more than 1 value per channel when training, got input size [1, 16, 1, 1]

大佬链接:https://blog.csdn.net/thy0000/article/details/123435996
9. 代码没有执行完就返回,应该是报错
10.ValueError: Expected more than 1 value per channel when training, got input size [1, 16, 1, 1](解决方案)

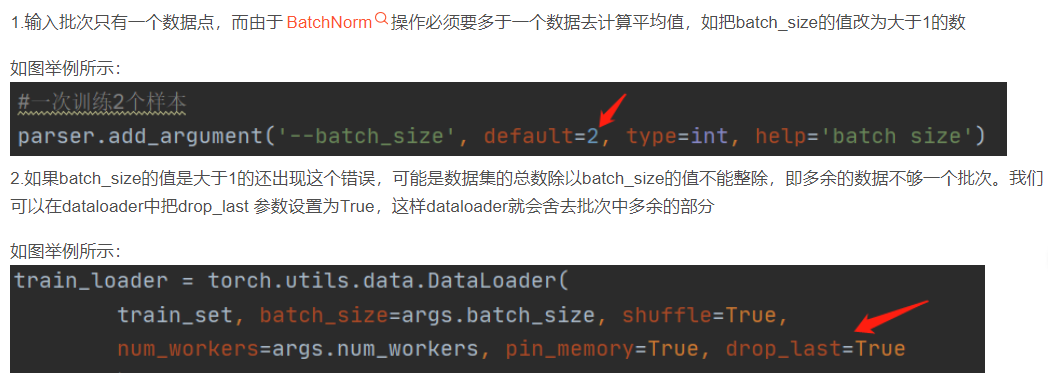
大佬链接:https://blog.csdn.net/thy0000/article/details/123435996
11. nn.AdaptiveAvgPool2d:对输入信号,提供2维的自适应平均池化操作 对于任何输入大小的输入,可以将输出尺寸指定为H*W,但是输入和输出特征的数目不会变化
m = nn.AdaptiveAvgPool2d((1,1)) input = torch.randn(1, 64, 10, 9) output = m(input) print(output.size())
输出:torch.Size([1, 64, 1, 1])
大佬链接:PyTorch中AdaptiveAvgPool函数用法及原理解析 - Jerry_Jin - 博客园 (cnblogs.com)
12 ssim训练一段时间后由正常值变为0
以下是一些可能导致 SSIM 降为 0 的原因:
-
过拟合:如果模型训练的 epoch 数量太多,可能导致过拟合,即模型对训练集的拟合过高,而对测试集的预测能力下降。这种情况下,网络对未见过的数据可能会产生不准确的预测,从而导致 SSIM 降为 0。
-
学习率过大或过小:学习率是指模型在每次迭代中更新权重的步长。学习率过大会导致权重更新过快,模型可能无法充分收敛,并产生过拟合。学习率过小则会导致模型收敛速度过慢,训练时间过长,并可能陷入局部最优解而无法进一步提升性能。这两种情况都可能导致 SSIM 降为 0。
-
数据质量问题:如果训练数据受到噪声、伪像或者其他因素的干扰,可能会导致模型过度拟合,并降低测试集上的性能。此外,如果测试集与训练集不匹配,也可能导致 SSIM 降为 0。
-
网络结构问题:如果网络结构选择不当,例如网络太浅不足以提取图像中的关键特征,或者网络太深复杂度过高导致梯度消失或爆炸,则可能导致模型性能下降,从而导致 SSIM 降为 0。
要解决 SSIM 降为 0 的问题,可以尝试以下方法:
-
提前停止训练:通过设置合适的训练 epoch 数量,及时停止训练来避免过拟合问题。
-
调整学习率:通过调整学习率来使模型更好地收敛。
-
减少噪声或伪像等干扰:通过预处理数据、增强数据等方式减少噪声或伪像等干扰。
-
调整网络结构:选择合适的网络结构,提高网络的性能。
综上所述,SSIM 降为 0 可能与过拟合、学习率设置不合适、数据质量问题、网络结构问题等多种因素有关,需要进行综合分析并根据具体情况采取相应的解决方法。
13 FFA跑通问题
(1)cuda内存溢出:
检查:batch_size,crop 是否裁剪
(2)stact_dict加载错误:
RuntimeError: Error(s) in loading state_dict for FFA: Missing key(s) in state_dict: "g1.gp.19.weight", "g1.gp.19.bias", "g2.gp.19.weight", "g2.gp.19.bias", "g3.gp.19.weight", "g3.gp.19.bias". Unexpected key(s) in state_dict: "g1.gp.20.weight", "g1.gp.2
将option.py中blocks改成了19
(3) 测试的时候生成的图像一直是黄色的
不知道为啥需要对数据进行这样的预处理,可能是训练的时候进行了这样的预处理,测试也需要
haze1 = tfs.Compose([ tfs.ToTensor(), tfs.Normalize(mean=[0.64, 0.6, 0.58], std=[0.14, 0.15, 0.152]) ])(haze)
14 测试时间慢
可能是网络、数据没放到gpu上
15 训练过程中指标不一致问题
应该设置固定的种子
16 cuda内存溢出
(1)batch_size
(2)num_workers
(3)图片裁剪大小
17、锁死种子,应该在程序入口锁死
18. ValueError: win_size exceeds image extent. Either ensure that your images are at least 7x7; or pass

pip instal scikit-image==0.19.3
19. wandb.errors.UsageError: api_key not configured (no-tty). call wandb.login(key=[your_api_
https://blog.csdn.net/weixin_52890053/article/details/132111731
20. AttributeError: module ‘distutils‘ has no attribute ‘version‘
https://blog.csdn.net/hahhahahhaja/article/details/128003170

 浙公网安备 33010602011771号
浙公网安备 33010602011771号