python-day39_管道_进程池_线程_条件_定时器_队列_线程池
1,管道
双向的,一端进,就从另一端出
每一端都要手工close()
from multiprocessing import Pipe,Process def func(conn1,conn2): conn2.close() while True: try : msg = conn1.recv() print(msg) except EOFError: conn1.close() break if __name__ == '__main__': conn1, conn2 = Pipe() Process(target=func,args = (conn1,conn2)).start() conn1.close() for i in range(20): conn2.send('吃了么') conn2.close()
数据安全,加锁,防止多进程写数据时出现冲突和不准确
from multiprocessing import Manager,Process,Lock def main(dic,lock): lock.acquire() dic['count'] -= 1 lock.release() if __name__ == '__main__': m = Manager() l = Lock() dic=m.dict({'count':100}) p_lst = [] for i in range(50): p = Process(target=main,args=(dic,l)) p.start() p_lst.append(p) for i in p_lst: i.join() print('主进程',dic)
2,进程池
# 为什么会有进程池的概念
# 可提高效率
# 每开启进程,开启属于这个进程的内存空间
# 寄存器 堆栈 文件
# 进程过多 操作系统的调度
# 进程池
# python中的 先创建一个属于进程的池子
# 这个池子指定能存放n个进程
# 先讲这些进程创建好
# 更高级的进程池
# n,m 从n到m,根据需要自动新增和减少进程
# 3 三个进程
# + 进程
# 20 20个
import time from multiprocessing import Pool,Process def func(n): for i in range(10): print(n+1) if __name__ == '__main__': start = time.time() pool = Pool(5) # 5个进程 pool.map(func,range(100)) # 100个任务,任务必须是可迭代的;map自带有join() t1 = time.time() - start start = time.time() p_lst = [] for i in range(100): p = Process(target=func,args=(i,)) p_lst.append(p) p.start() for p in p_lst :p.join() t2 = time.time() - start print(t1,t2)
import os import time from multiprocessing import Pool def func(n): print('start func%s'%n,os.getpid()) time.sleep(1) print('end func%s' % n,os.getpid()) if __name__ == '__main__': p = Pool(5) for i in range(10): p.apply_async(func,args=(i,)) # p.apply()进程间是同步的,前一个进程结束后,再开下个进程。apply_async是异步的 p.close() # 结束进程池接收任务,apply_async时需配置 p.join() # 感知进程池中的"任务"执行结束,apply_async时需配置
3,回调函数
func2是回调函数,在主进程中运行
import os from multiprocessing import Pool def func1(n): print('in func1',os.getpid()) return n*n def func2(nn): print('in func2',os.getpid()) print(nn) if __name__ == '__main__': print('主进程 :',os.getpid()) p = Pool(5) for i in range(10): p.apply_async(func1,args=(10,),callback=func2) p.close() p.join()
4,socket
server:
import socket from multiprocessing import Pool def func(conn): conn.send(b'hello') print(conn.recv(1024).decode('utf-8')) conn.close() if __name__ == '__main__': p = Pool(5) sk = socket.socket() sk.bind('127.0.0.1',8080) sk.listen() while True: conn,addr == sk.accept() p.apply_async(func,args=(conn,)) sk.close()
5,
C:\Users\Administrator>pip3 install requests
C:\Users\Administrator>pip3 list
爬取数据例子:
import requests from urllib.request import urlopen from multiprocessing import Pool # 200 网页正常的返回 # 404 网页找不到 # 502 504 def get(url): response = requests.get(url) if response.status_code == 200: return url,response.content.decode('utf-8') def get_urllib(url): ret = urlopen(url) return ret.read().decode('utf-8') def call_back(args): url,content = args print(url,len(content)) if __name__ == '__main__': url_lst = [ 'https://www.cnblogs.com/', 'http://www.baidu.com', 'https://www.sogou.com/', 'http://www.sohu.com/', ] p = Pool(5) for url in url_lst: p.apply_async(get,args=(url,),callback=call_back) p.close() p.join()
爬虫:


import re from urllib.request import urlopen from multiprocessing import Pool def get_page(url,pattern): response=urlopen(url).read().decode('utf-8') return pattern,response # 正则表达式编译结果 网页内容 def parse_page(info): pattern,page_content=info res=re.findall(pattern,page_content) for item in res: dic={ 'index':item[0].strip(), 'title':item[1].strip(), 'actor':item[2].strip(), 'time':item[3].strip(), } print(dic) if __name__ == '__main__': regex = r'<dd>.*?<.*?class="board-index.*?>(\d+)</i>.*?title="(.*?)".*?class="movie-item-info".*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>' pattern1=re.compile(regex,re.S) url_dic={'http://maoyan.com/board/7':pattern1} p=Pool() res_l=[] for url,pattern in url_dic.items(): res=p.apply_async(get_page,args=(url,pattern),callback=parse_page) res_l.append(res) for i in res_l: i.get()
6,线程
有了进程为什么要有线程
进程有很多优点,它提供了多道编程,让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计算机的利用率。很多人就不理解了,既然进程这么优秀,为什么还要线程呢?其实,仔细观察就会发现进程还是有很多缺陷的,主要体现在两点上:
-
进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。
-
进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行。
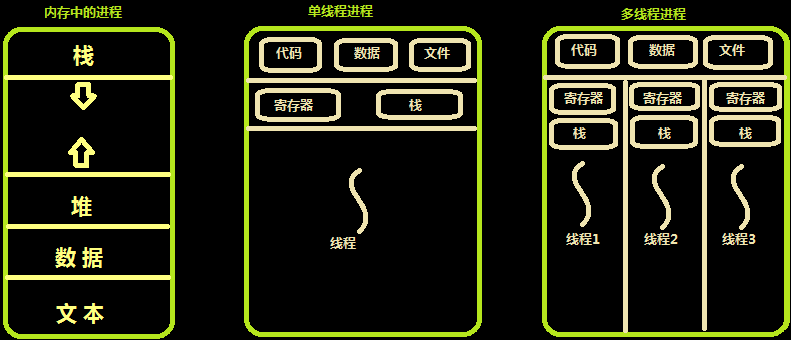
import os from threading import Thread def func(a,b): global g g = 0 # 跟主程序是同一个进程,变量也是同一个 print(g,os.getpid()) g = 100 t_lst = [] for i in range(10): t = Thread(target=func,args=(i,5)) t.start() t_lst.append(t) for t in t_lst: t.join() print(g)
import time from threading import Thread class Mytread(Thread): def __init__(self,arg): super().__init__() self.arg = arg def run(self): # 内置方法 time.sleep(1) print(self.arg) t = Mytread(10) t.start() # 实际是调用run()
# 进程 是 最小的 内存分配单位
# 线程 是 操作系统调度的最小单位
# 线程直接被CPU执行,进程内至少含有一个线程,也可以开启多个线程
# 开启一个线程所需要的时间要远远小于开启一个进程
# 多个线程内部有自己的数据栈,数据不共享
# 全局变量在多个线程之间是共享的
# GIL锁(即全局解释器锁)
锁的是线程
# 在Cpython解释器下的python程序 在同一时刻 多个线程中只能有一个线程被CPU执行
# 高CPU : 计算类程序 --- 高CPU利用率
# 高IO : 爬取网页 200个网页
# qq聊天 send recv
# 处理日志文件 读文件
# 处理web请求
# 读数据库 写数据库
GIL对程序有啥影响
1.Python中的多线程不适合计算机密集型的程序;
2.如果程序需要大量的计算,利用多核CPU资源,可以使用多进程来解决。
7,线程的一些方法
import time import threading def wahaha(n): time.sleep(0.5) print(n,threading.current_thread(),threading.get_ident()) for i in range(10): threading.Thread(target=wahaha,args=(i,)).start() print(threading.active_count()) # 11 print(threading.current_thread()) print(threading.enumerate())
8,条件
# 一个条件被创建之初 默认有一个False状态
# False状态 会影响wait一直处于等待状态
# notify(int数据类型) 造钥匙
from threading import Thread,Condition def func(con,i): con.acquire() con.wait() # 等钥匙 print('在第%s个循环里'%i) con.release() con = Condition() for i in range(10): Thread(target=func,args = (con,i)).start() while True: num = int(input('>>>')) con.acquire() con.notify(num) # 造钥匙 con.release()
9,定时器
import time from threading import Timer def func(): print('时间同步') #1-3 while True: t = Timer(5,func).start() # 非阻塞的 time.sleep(5)
10,队列
import queue q = queue.Queue() # 队列 先进先出 q.put(1) print(q.get()) print(q.get_nowait()) # q.put_nowait() # 当队列空或满,不会阻塞,直接报错 # q.get_nowait() # q = queue.LifoQueue() # 栈 先进后出 # q.put(1) # q.put(2) # q.put(3) # print(q.get()) # print(q.get()) q = queue.PriorityQueue() # 优先级队列,优先级小的优先,然后值的ASCII码小的优先 q.put((20,'a')) q.put((10,'b')) q.put((30,'c')) q.put((-5,'d')) q.put((1,'?')) print(q.get())
11,线程池
import time from concurrent.futures import ThreadPoolExecutor def func(n): time.sleep(2) print(n) return n*n def call_back(m): print('结果是%s'%m.result()) tpool = ThreadPoolExecutor(max_workers=5) # 默认 不要超过cpu个数*5 t_lst = [] for i in range(20): t = tpool.submit(func,i) t_lst.append(t) # tpool.shutdown() # 相当于close+join # print('主线程') for t in t_lst: print('***',t.result())
import time from concurrent.futures import ThreadPoolExecutor def func(n): time.sleep(2) print(n) return n*n def call_back(m): print('结果是 %s'%m.result()) tpool = ThreadPoolExecutor(max_workers=5) # 默认 不要超过cpu个数*5 for i in range(20): tpool.submit(func,i).add_done_callback(call_back)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号