


第一次个人编程作业
链接
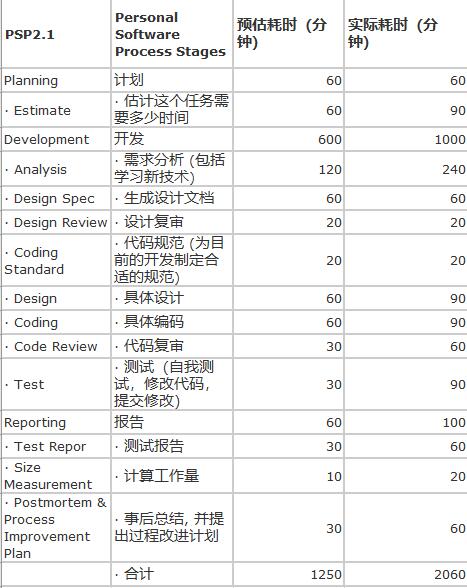
PSP表格
一开始以为时间不会耗费太长,但是实际开始发现真的什么都不会,不仅仅只是编写一个代码那么简单,一开始查阅就是十几个浏览器窗口,有时候看不明白就和同学讨论,就这样感觉时间一直不够, 拥抱开源,半蒙半会的看了半天有了点思路,慢慢的写了出来(但还是和前几个提交的大佬相比差了好多)
算法流程
作为刚开始学python的小白,当作业布置的时候就想着刚好来练练手(一上手就是整个项目,真有你的),在查阅了许多的资料,了解到各种各样的库后,一开始想用杰卡德系数来写,但运行之后发现对于后面的几个dis文档,杰卡德系数不管用了,相似度变成了1,当然全抄是不可能。再次寻找其他算法,发现可以利用了jieba库的分词加上tfidf算法来进行相似度的计算。以下为流程图:
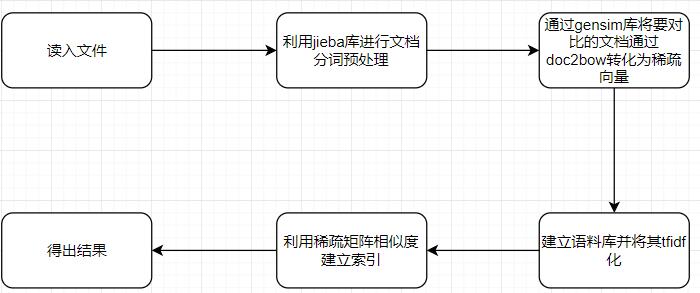
所谓TF-IDF:
词频 (term frequency, TF)指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)但是, 需要注意, 一些通用的词语对于主题并没有太大的作用, 反倒是一些出现频率较少的词才能够表达文章的主题, 所以单纯使用是TF不合适的。权重的设计必须满足:一个词预测主题的能力越强,权重越大,反之,权重越小。所有统计的文章中,一些词只是在其中很少几篇文章中出现,那么这样的词对文章的主题的作用很大,这些词的权重应该设计的较大。IDF就是在完成这样的工作.
TF=在某一类中词条w出现的次数/该类中所有的词条数目
逆向文件频率 (inverse document frequency, IDF) IDF的主要思想是:如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
公式:
IDF=log(语料库的文档总数包含词条w的文档数+1/包含词条w的文档数+1),分母之所以要加1,是为了避免分母为0
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TF−IDF=TF∗IDF
关于这的详细介绍我也贴在下面:
关于jieba库
关于tfidf算法
关键代码
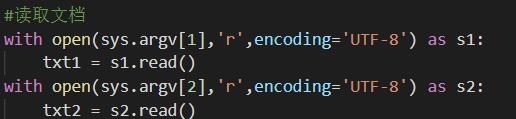
首先当然是读与写文件:
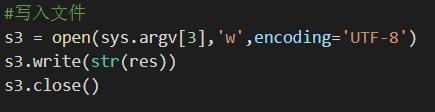
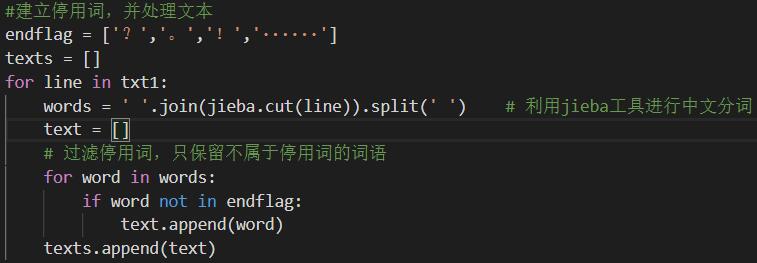
之后对文本进行处理并分词:
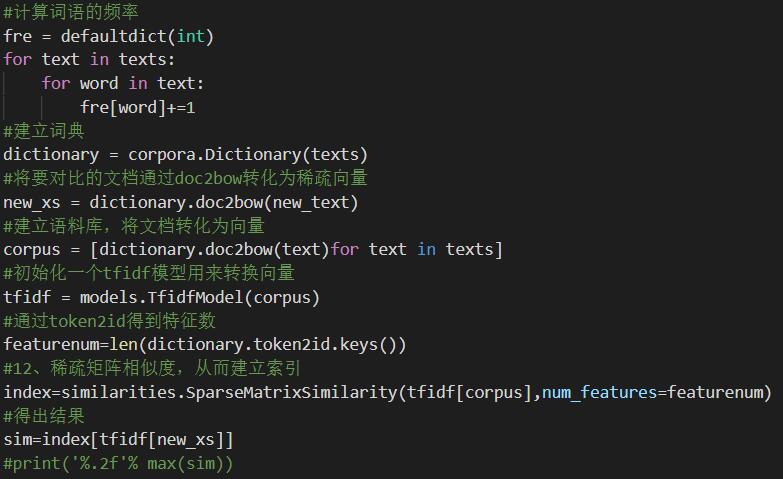
再者就是核心算法,计算词频,建立字典,并利用tfidf建立索引,返回结果:
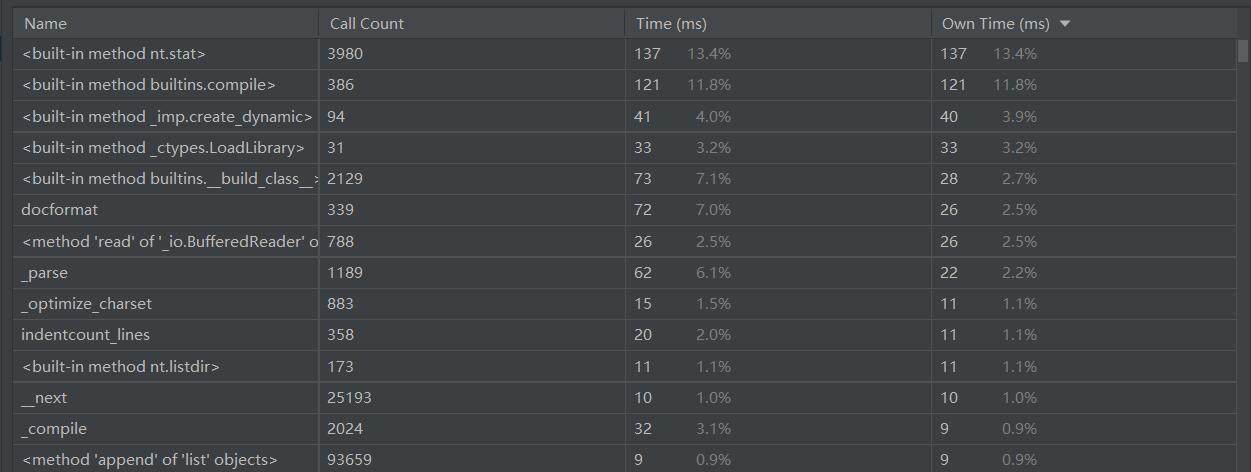
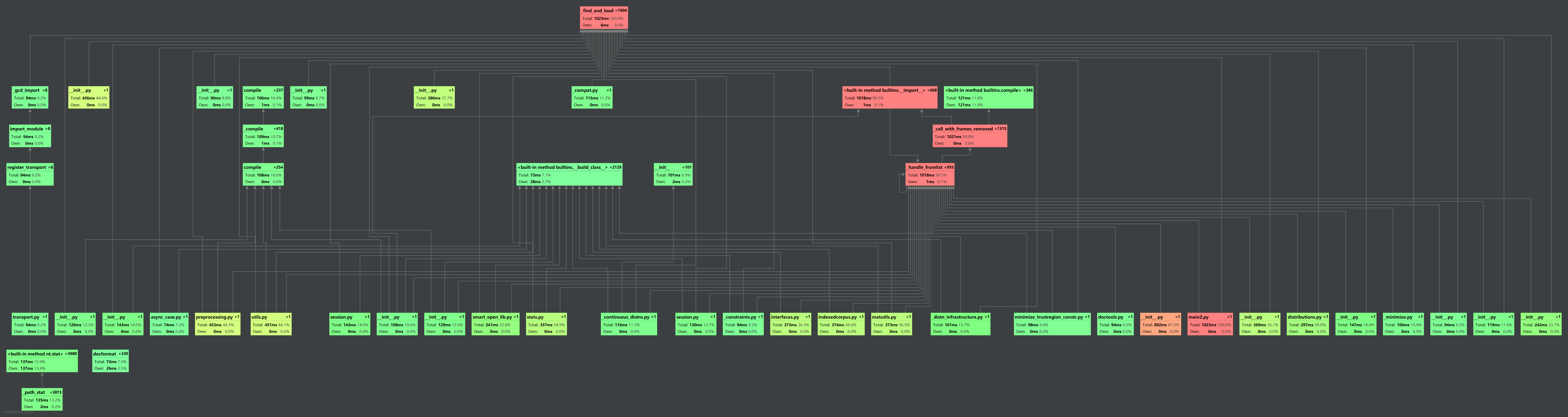
测试性能函数(使用了psutil库)输出了当前CPU使用及所耗时间:

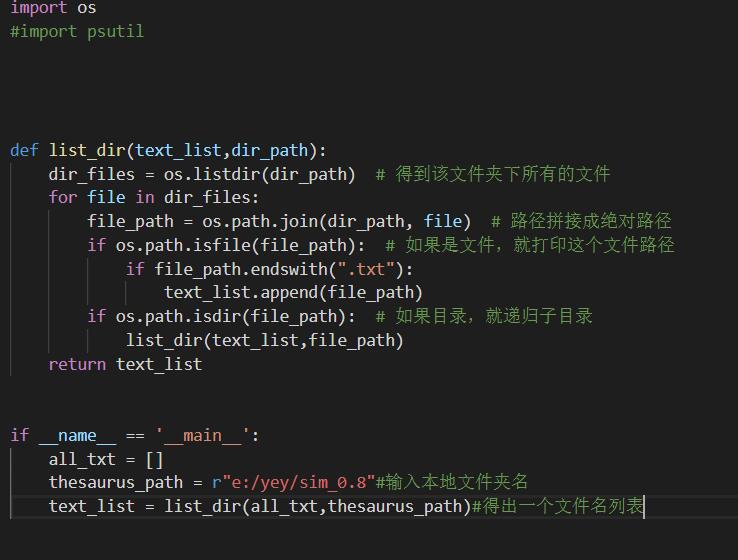
单元测试模块
因为写unittest模块一直出错,所以就选择了一种简单的方法,直接读取测试文件夹,循环测试相似度:

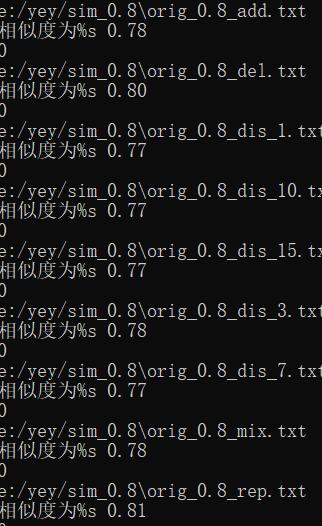
之后也用了pycharm跑了一次得出
可以看出都是符合要求的(松了一口气)
优化
一开始只是单纯的利用jieba库进行分词操作,没有去掉某些特殊符号,导致相似度过高,后面建立了停止词库辅助进行分词操作,提高了准确率。
(由于一直在源文件上改动,之前的忘了留截图QAQ)
反思与总结
刚开始学python,就上手做一个编程项目,既是挑战也是机会吧,确实什么都不会,但也确实学到了好多东西,不说别的,但是python第三方库就认识了好几个(不是)。代码的格式规范化也慢慢的在改进,美中不足的就是这次没把单元测试模块及异常结果处理模块完善好,对于真正意义上的完整项目还是有很大差距的。
与君共勉:
人生如棋子,我为卒,虽慢,但可曾见我后退半步?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号