
Collection和Map
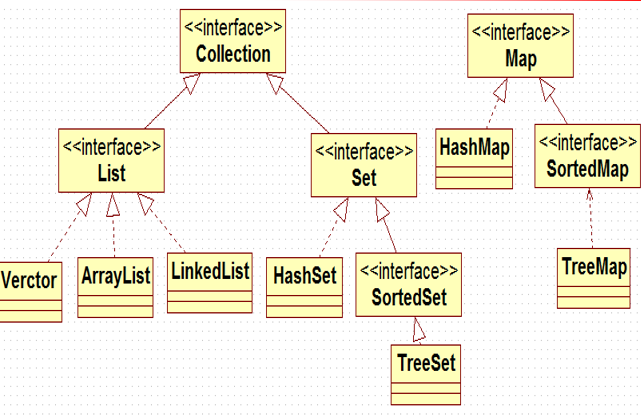
LIST 集合
arraylist
arraylist源代码:
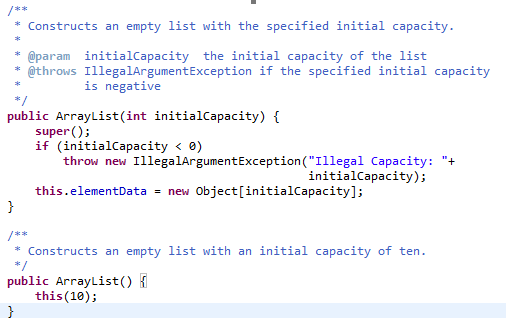
1.ArrayList 底层采用数组实现,当使用不带参数的构造方法生成 ArrayList 对象时,实际上会在底层生成一个长度为 10 的Object 类型数组
2.如果增加的元素个数超过了10个,那么ArrayList底层会新生成一个数组,长度为原数组的两倍,然后将原数组的内容复制到新数组当中,并且后续增加的内容都会放到新数组当中。当新数组无法容纳增加的元素时,重复该过程。
3.remove 对于ArrayList元素的删除操作,需要将被删除元素的后续元素向前移动,代价比较高,所以arraylist常用来查询。
4.集合当中只能放置对象的引用,无法放置原生数据类型,我们需要使用原生数据类型的包装类才能加入到集合当中
5.集合当中放置的都是Object类型,因此取出来的也是Object类型,那么必须要使用强制类型转换将其转换为真正的类型(放置进去的类型)。
linkedlist
LinkedList类是双向列表,列表中的每个节点都包含了对前一个和后一个元素的引用.
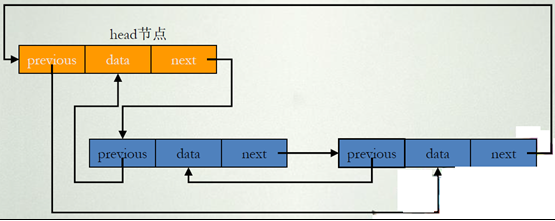
内部代码实现:定义一个entry类
- private static class Entry {
- Object element;
- Entry next; //定义一个后继节点
- Entry previous; //定义一个前驱节点
- }
arraylist 和 linkedlist 的区别
a) ArrayList底层采用数组实现,LinkedList底层采用双向链表实现。
b) 当执行插入或者删除操作时,将一个元素加到LinkedList的最开端只是简单的未这个元素分配一个记录,然后调整两个连接,所以采用LinkedList比较好。
c) 当执行搜索操作时,arrayList的内部实现是基于基础的对象数组的,因此,它使用get方法访问列表中的任意一个元素时(random access),它的速度要比LinkedList快,所以采用ArrayList比较好。
MAP
Map(映射):Map的keySet()方法会返回key的集合,因为Map的键是不能重复的,因此keySet()方法的返回类型是Set;而Map的值是可以重复的,因此values()方法的返回类型是Collection,可以容纳重复的元素。
hashset
查看HashSet源代码:

HashSet底层是使用HashMap实现的,此类允许使用null元素。map的key是不允许重复的,而hashset在添加元素的时候,实际上是将要添加的元素当作key放进hashmap里面去,hashmap内部有一个哈希表用来存储数据,当map往哈希表里面放东西的时候,再用key值的hashcode去查有没有存在。是这样达到去重复的目的的,因此该实现所存储的元素不能重复
hashmap
查看HashMap源代码
1.HashMap底层维护一个数组,我们向HashMap中所放置的对象实际上是存储在该数组当中;
2. 当向HashMap中put一对键值时,它会根据key的hashCode值计算出一个位置,该位置就是此对象准备往数组中存放的位置。
3.如果该位置没有对象存在,就将此对象直接放进数组当中;如果该位置已经有对象存在了,则顺着此存在的对象的链开始寻找(Entry类有一个Entry类型的next成员变量,指向了该对象的下一个对象),如果此链上有对象的话,再去使用equals方法进行比较,如果对此链上的某个对象的equals方法比较为false,则将该对象放到数组当中,然后将数组中该位置以前存在的那个对象链接到此对象的后面。
4.使用了Entry<K,V>的键字对的形式作为了数据结构。允许使用 null 值和 null 键。
5.键(key)值是set类型的,不可重复且无序,它的键通过hash算法去重。值(value)是collection型,可以重复。
6.HashMap不是线程安全的,效率高于hashtable。
hashtable
1.HashTable是线程安全的一个Collection。
2.除了不允许空值作为key值,和是同步的之外其余方法的特点与HashMap相同。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号