
python爬虫与数据可视化——python爬虫:补充BeautifulSoup
网页解析,获取数据--爬完网页把里面的数据进行拆分
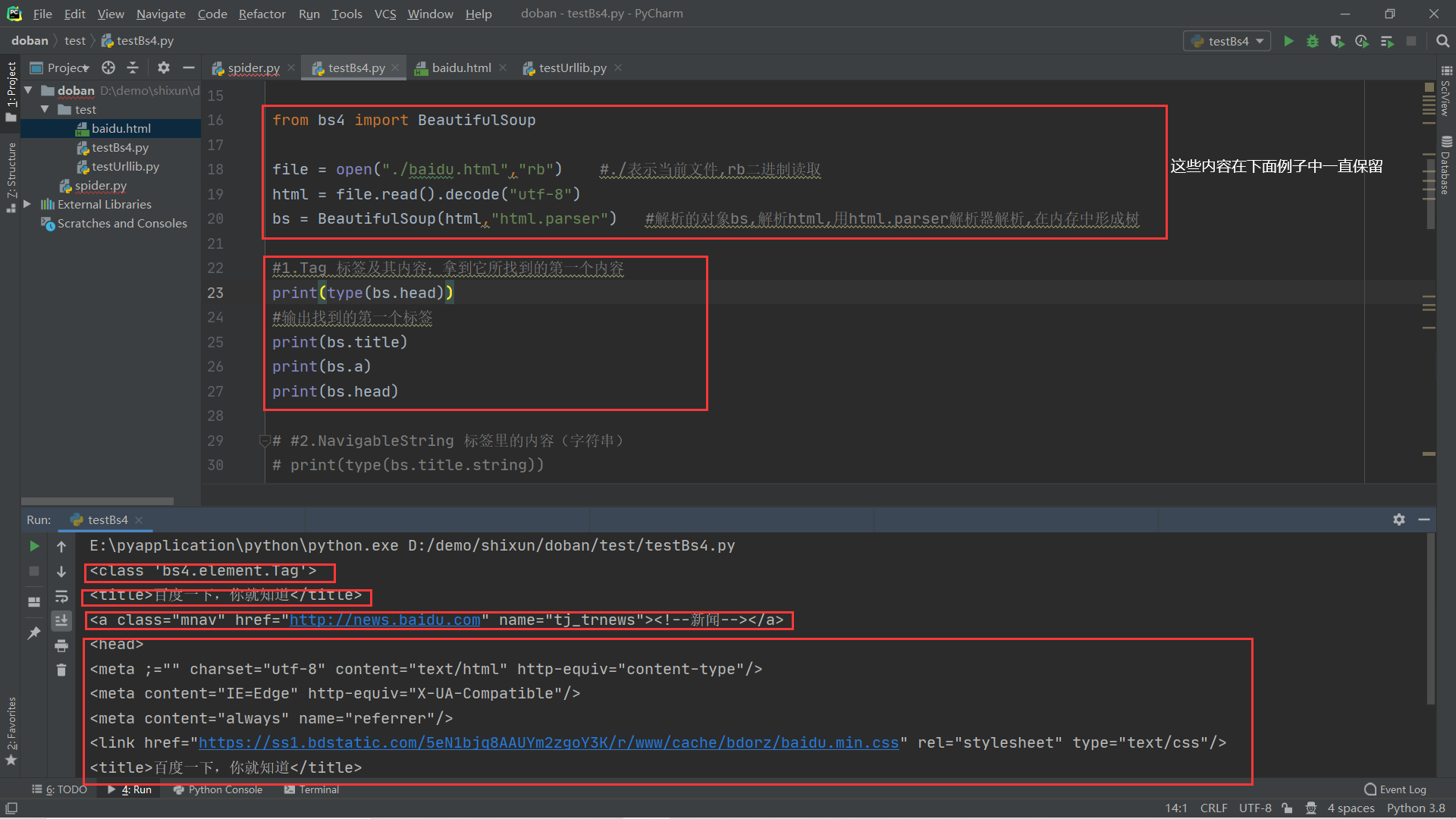
BeautifulSoup4将复杂html文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
- Tag
- NavigableString
- BeautifulSoup
- Comment
1.Tag 标签及其内容;拿到它所找到的第一个内容
2.NavigableString 标签里的内容(字符串)
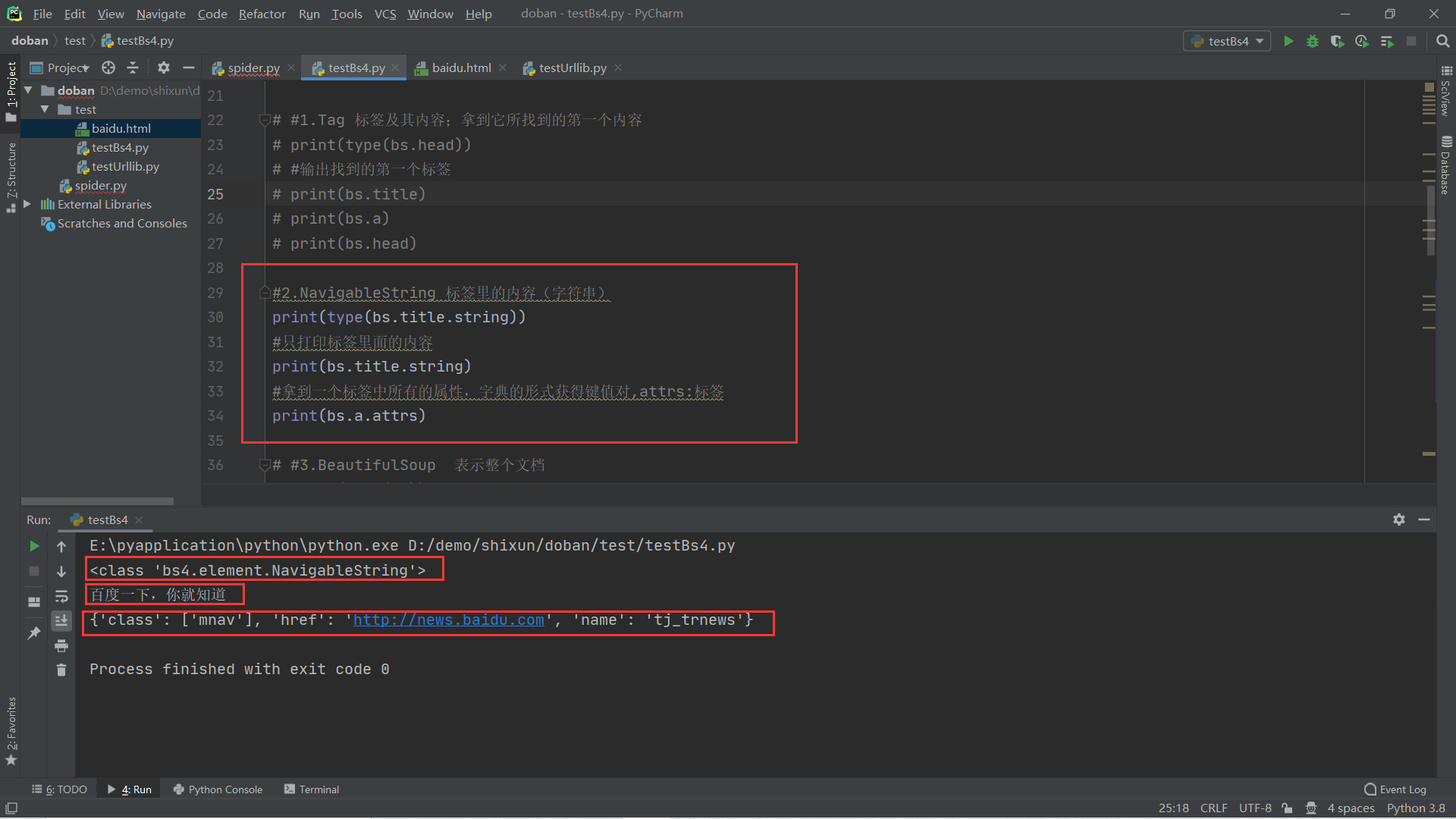
3.BeautifulSoup 表示整个文档

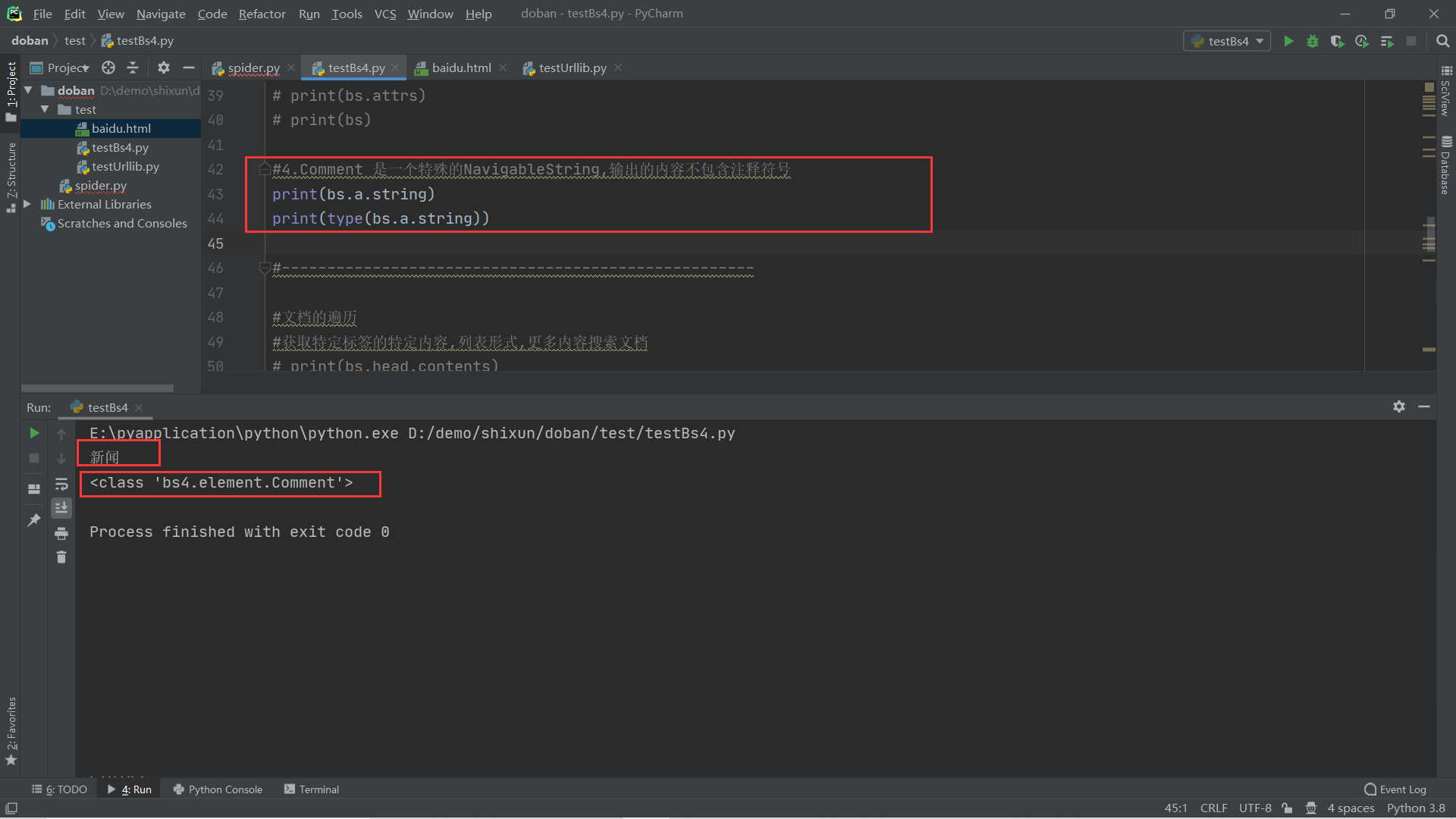
4.Comment 是一个特殊的NavigableString,输出的内容不包含注释符号
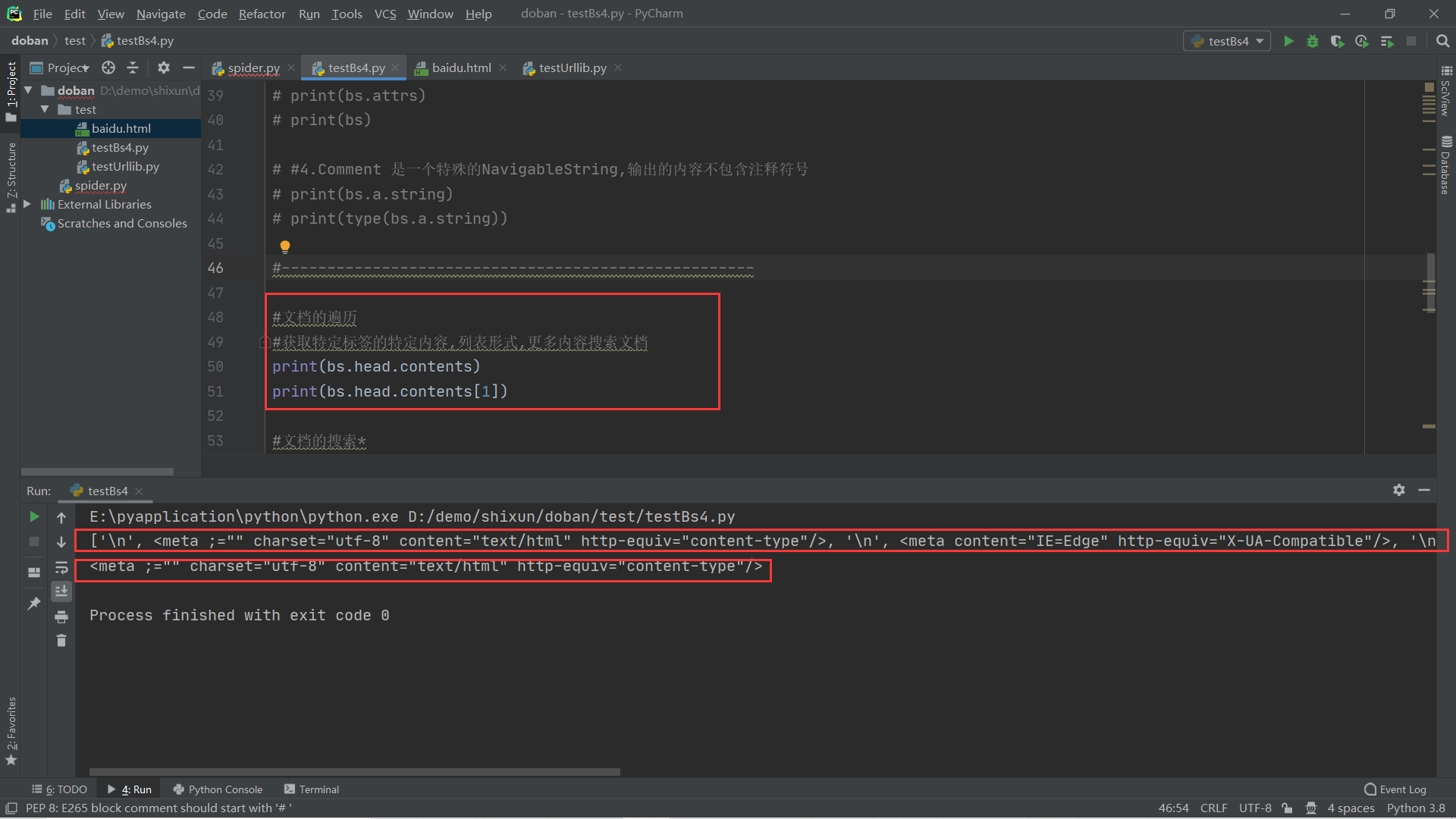
5.文档的遍历



6.文档的搜索
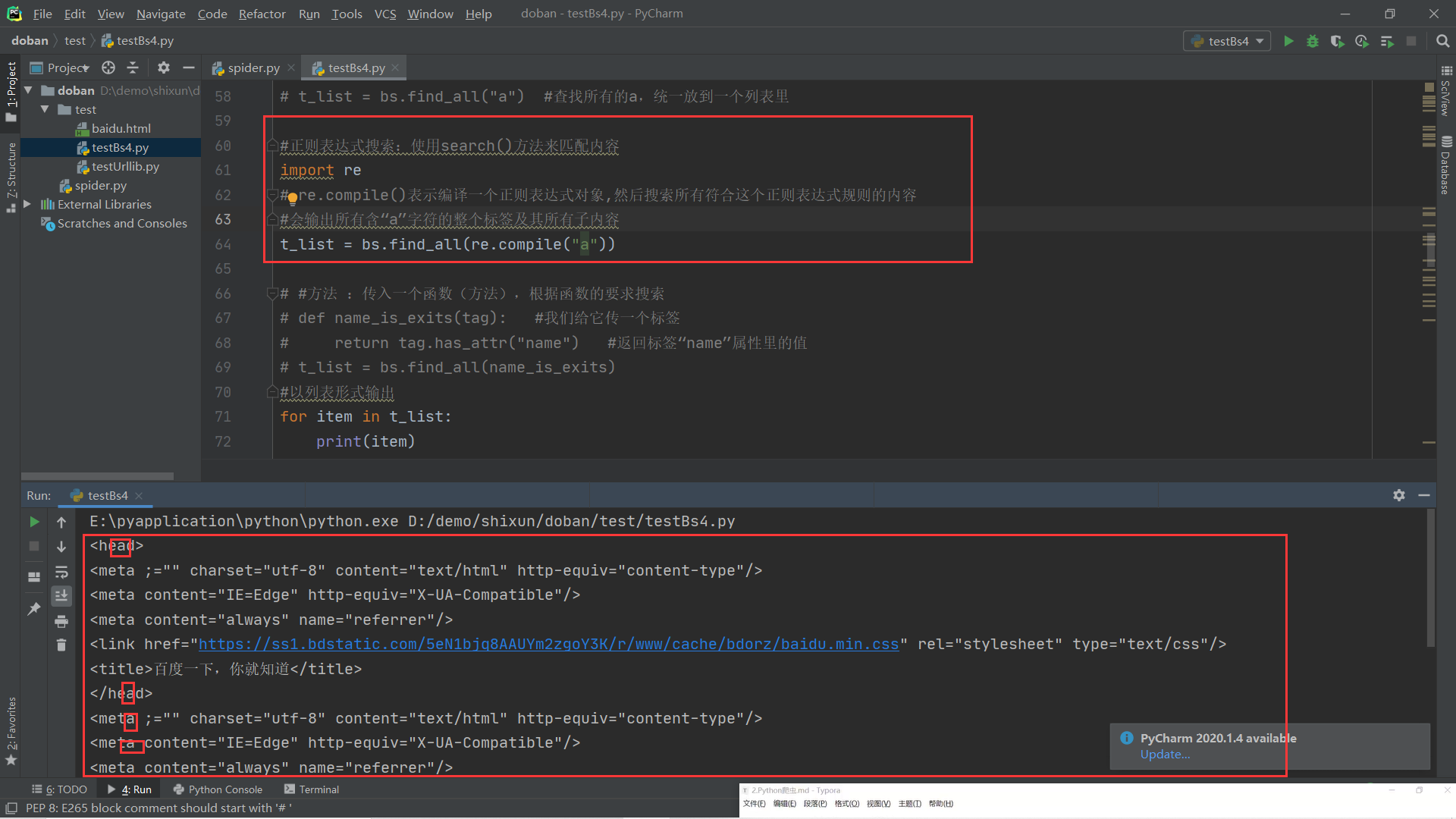
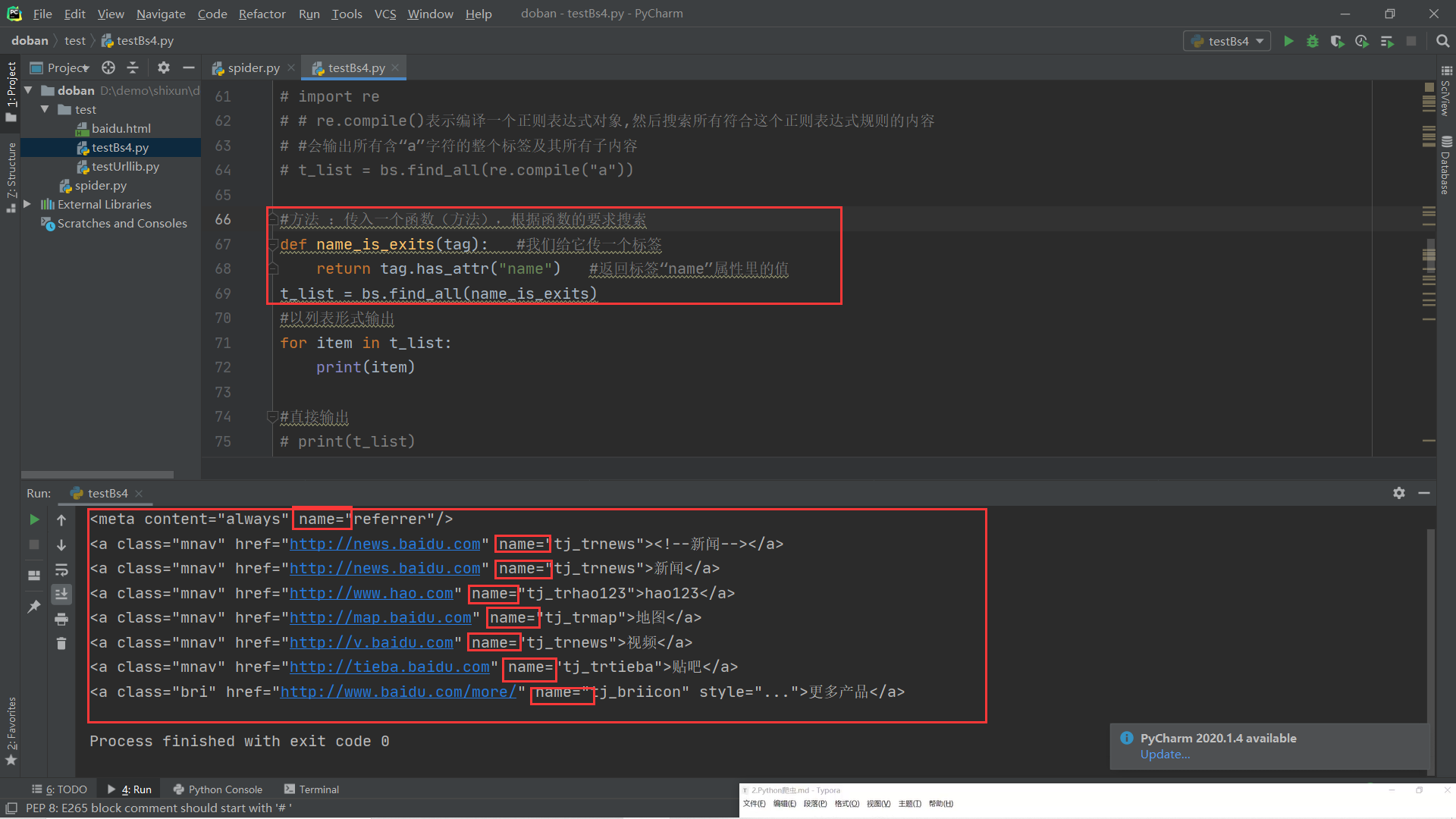
(1).find all()查找所有括号中的内容:字符串过滤,正则表达式搜索,根据函数要求搜索

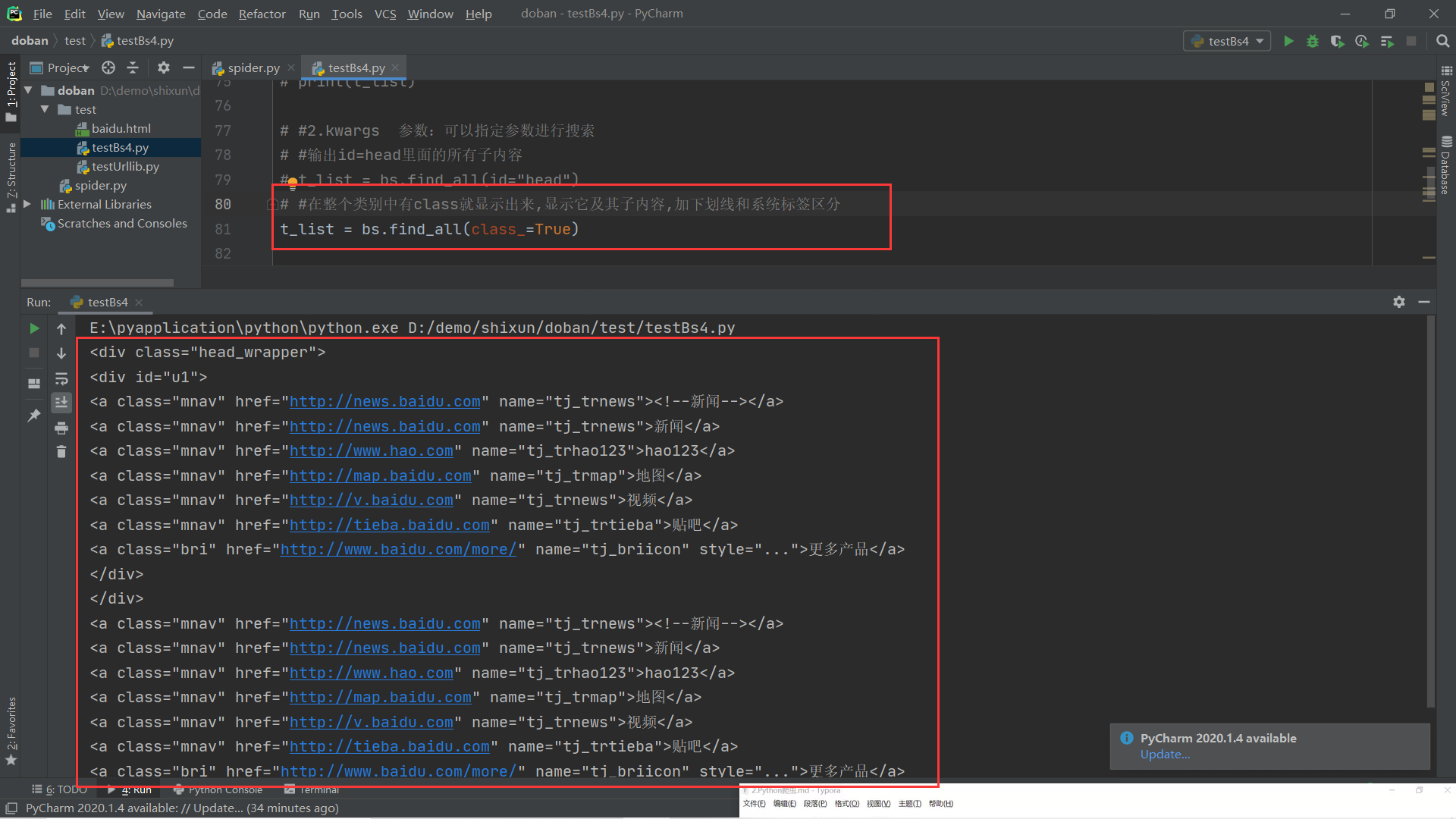
(2).kwargs:指定参数搜索

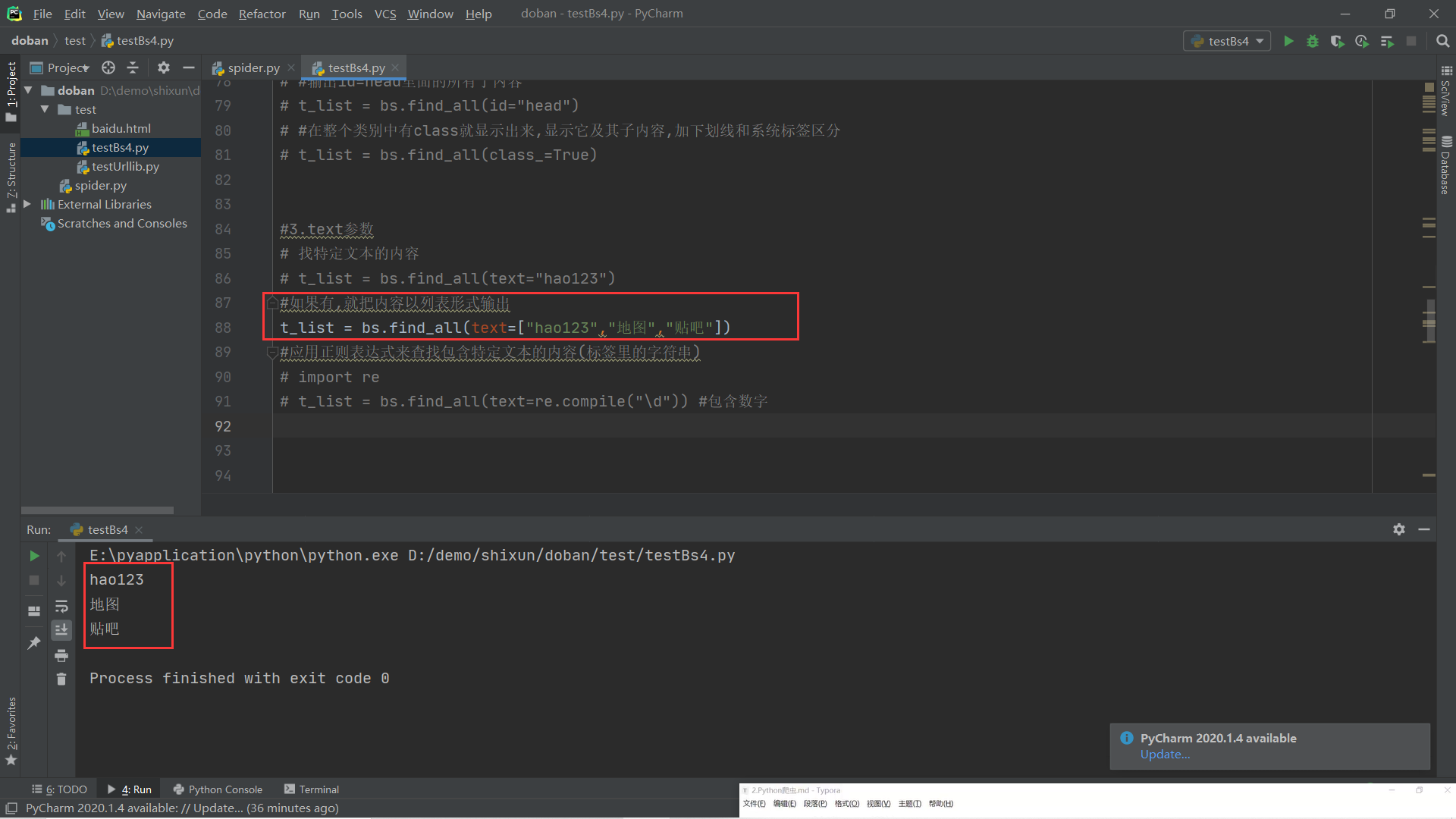
(3).text参数


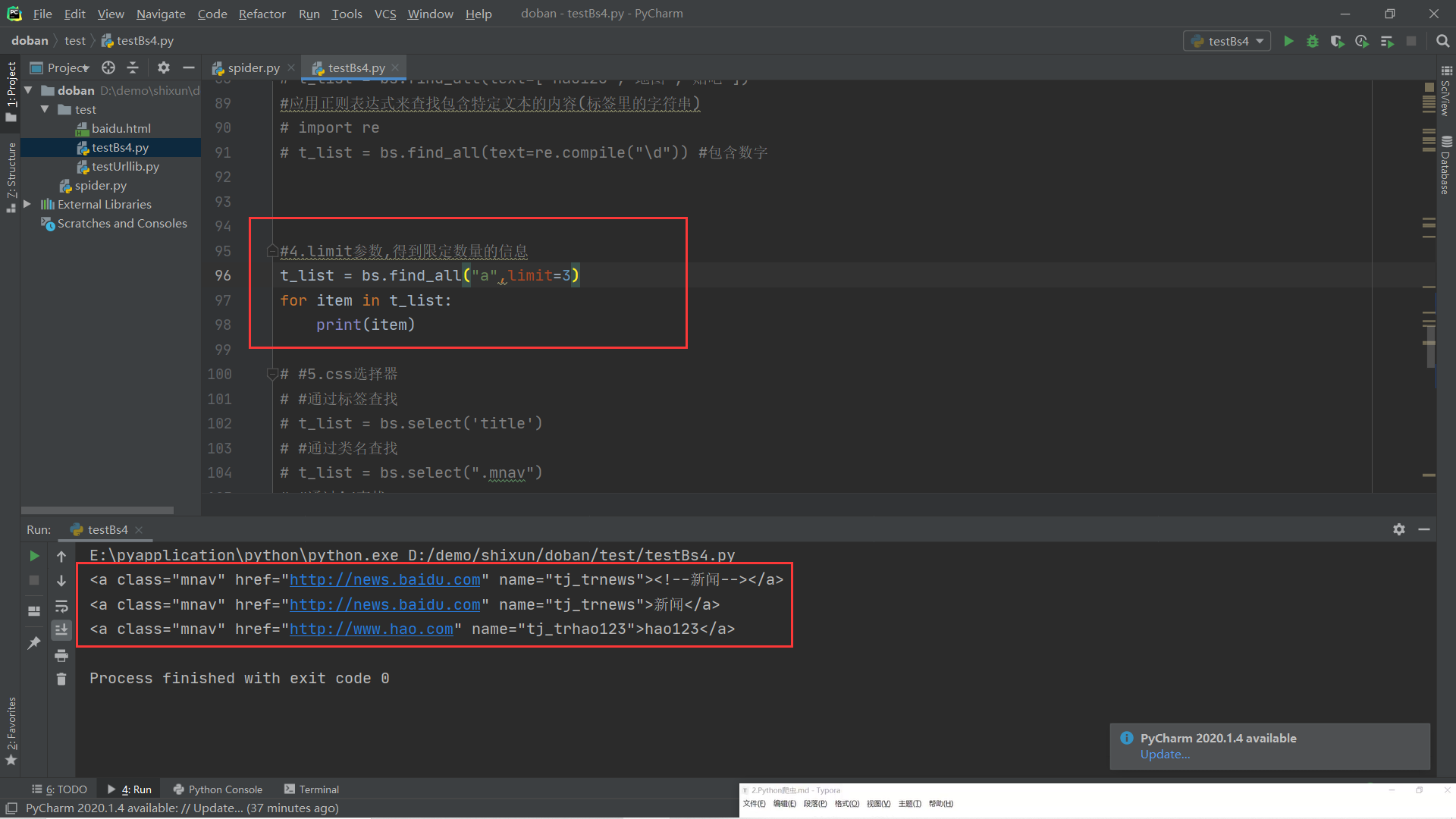
(4).limit参数,得到限定数量的信息
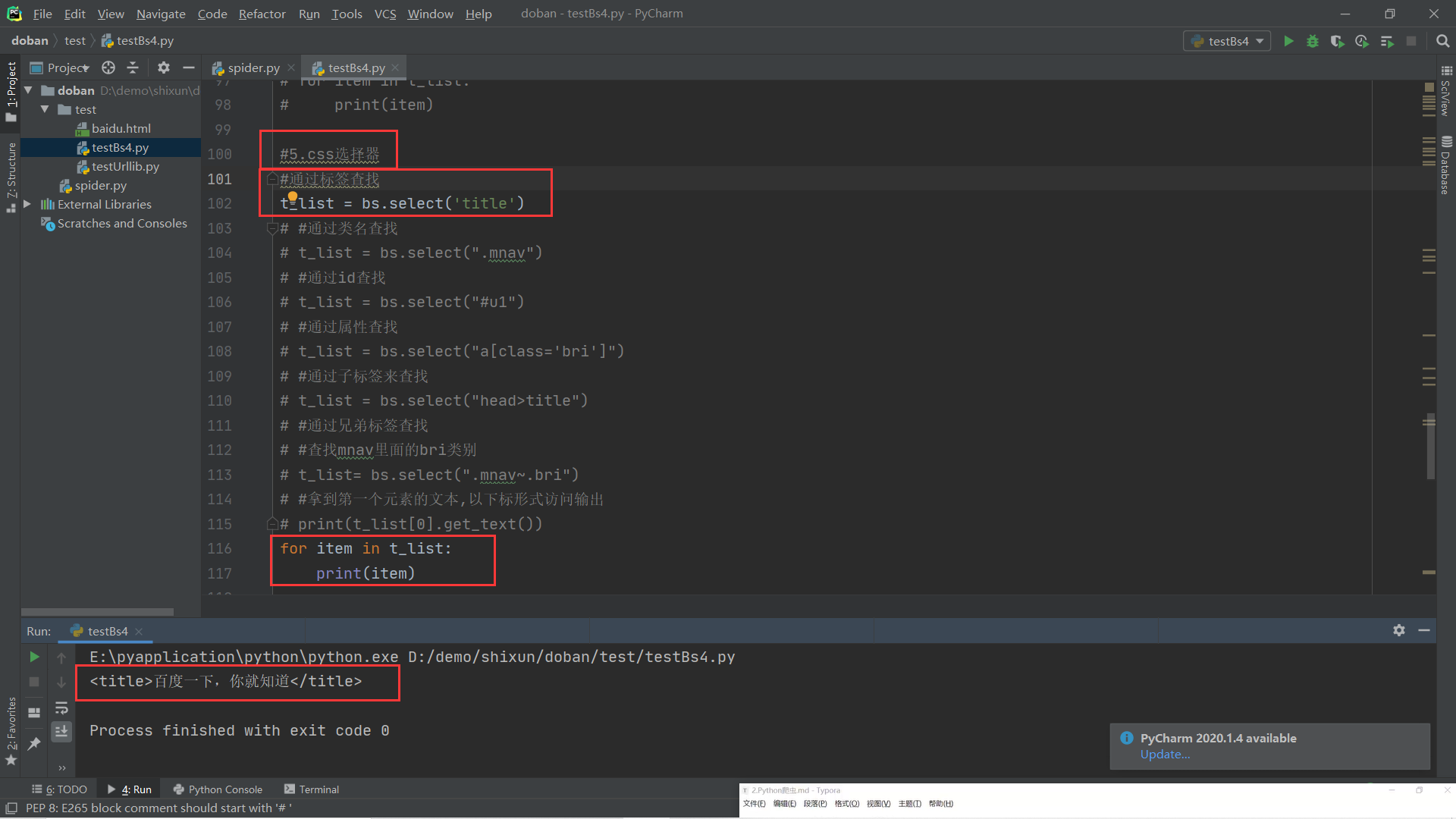
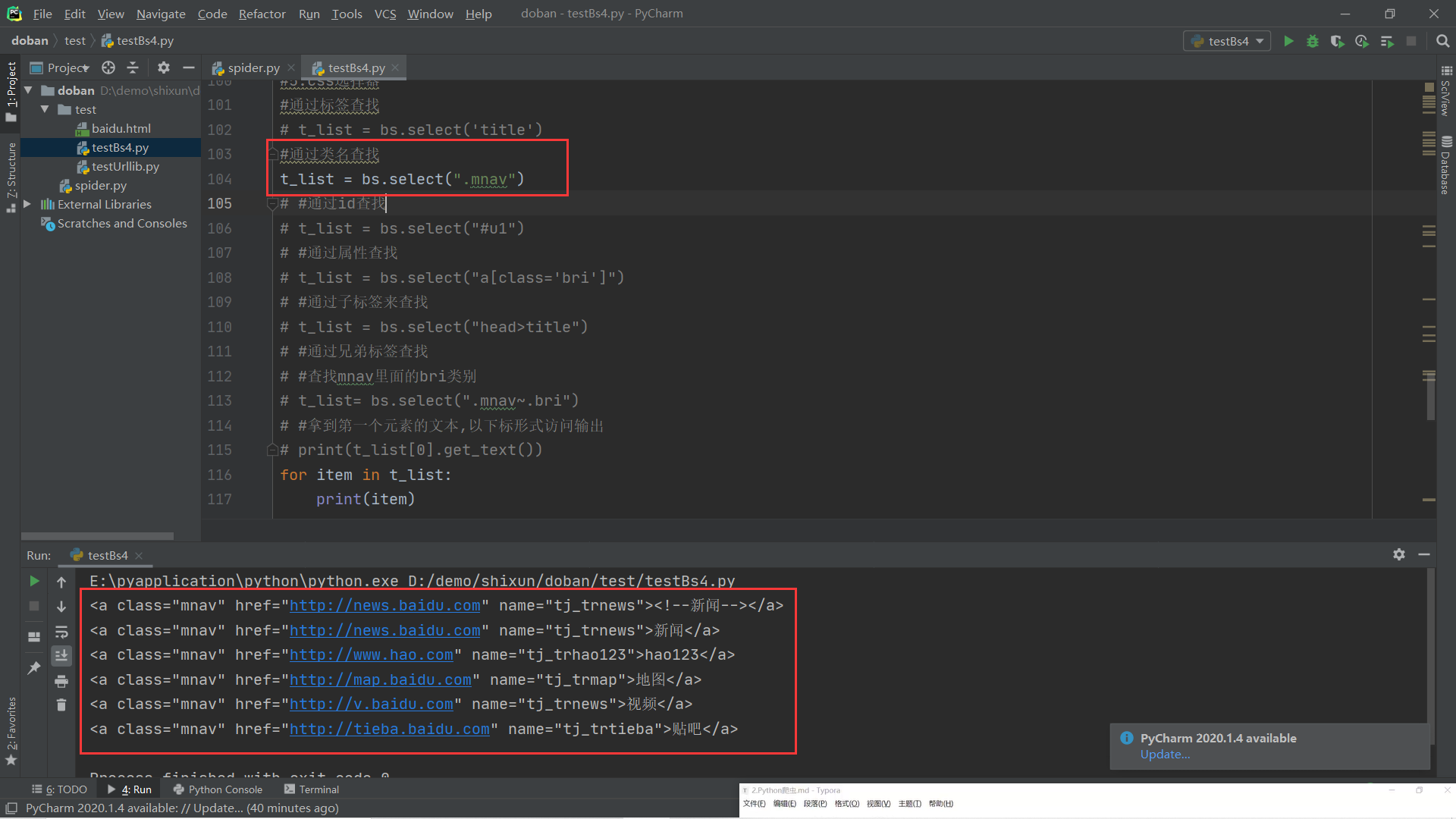
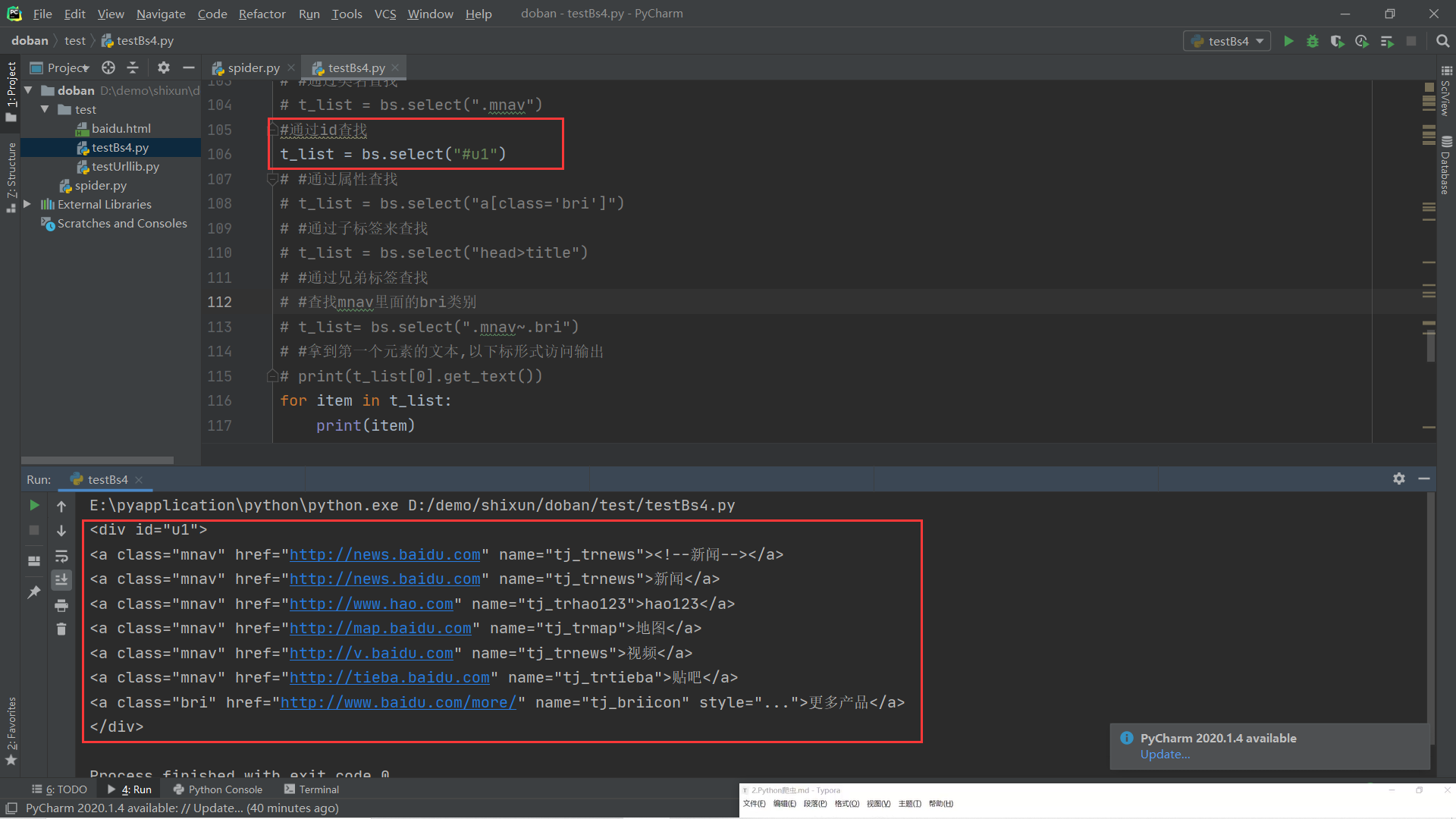
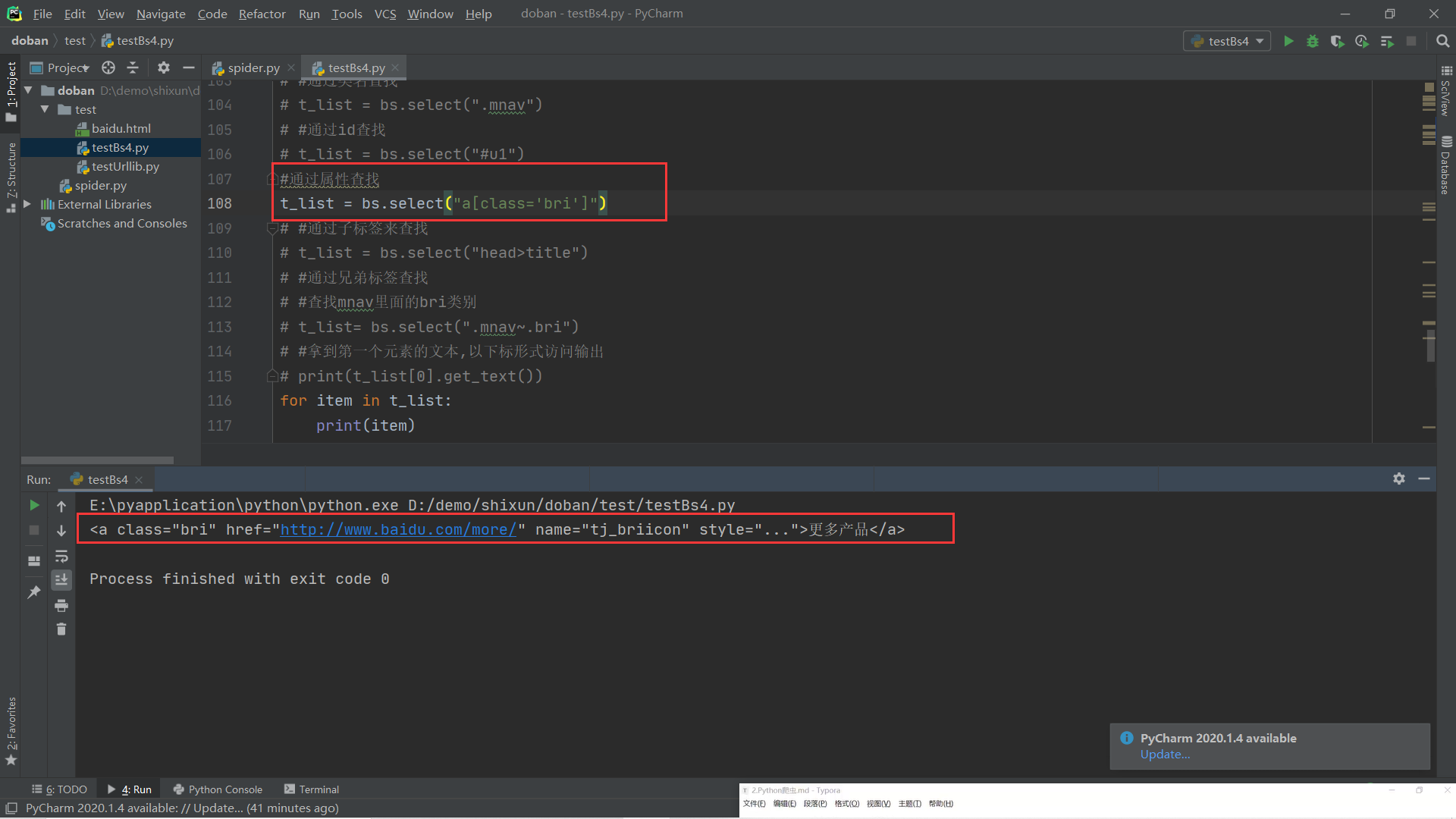
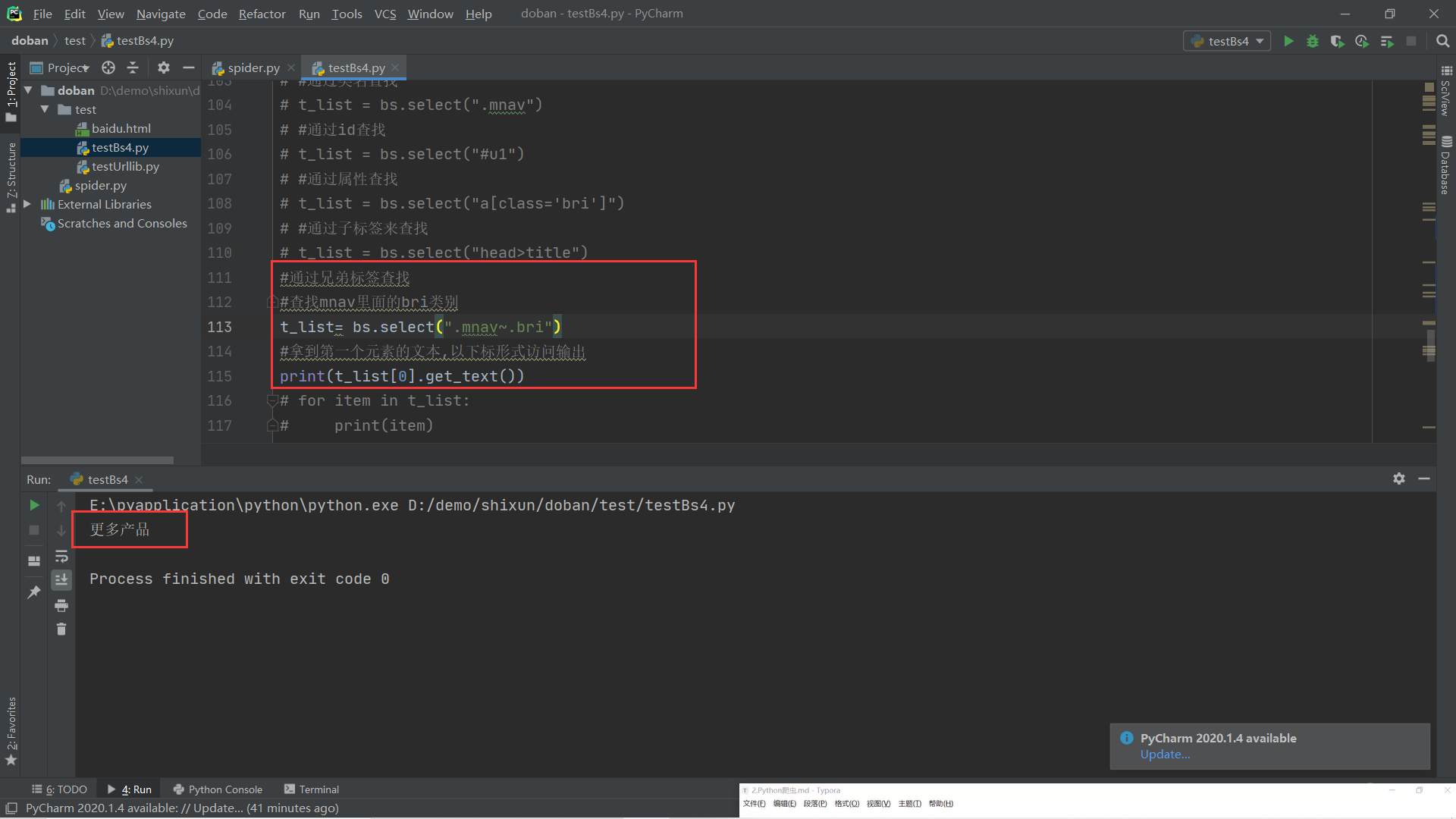
(5).css选择器:通过标签、类名、Id、属性、子标签、兄弟标签、以下标形式访问


 浙公网安备 33010602011771号
浙公网安备 33010602011771号