

python爬虫与数据可视化——python爬虫:准备工作
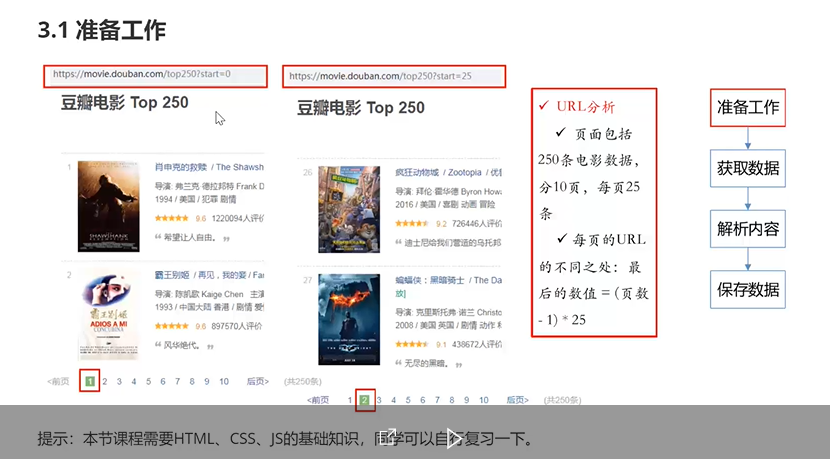
分页和网址链接之间的关系:start=29,页面就会展示第30条开始的25条记录,filter=表示没有过滤器。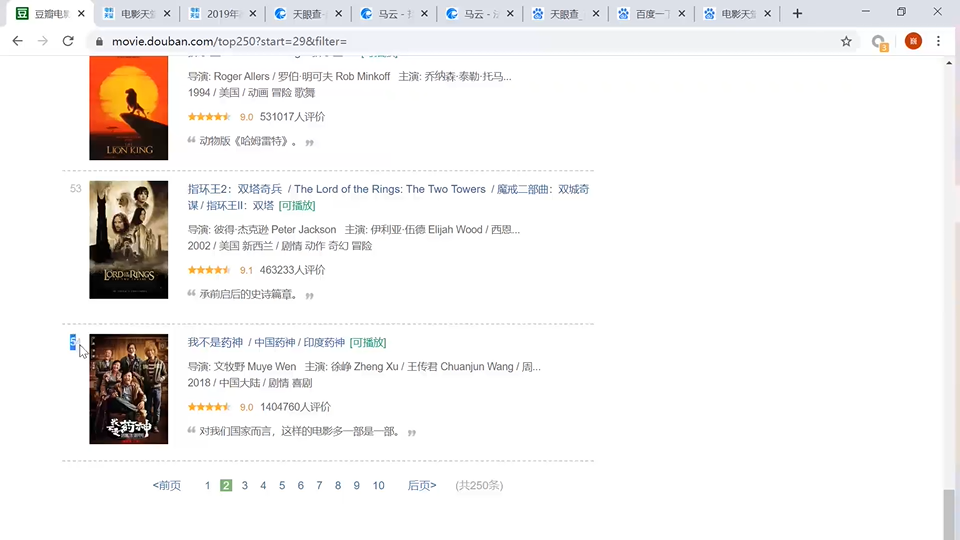
爬虫就是模仿人工在谷歌浏览器中使用Fn+F12查看源代码,用左上角小箭头点击需要爬取字段并且复制的过程。
Network是浏览器向服务器发送请求的日志记录。点击小红点可以使其停止记录,方便进行分析。我们写一个网页链接后我们的浏览器通过Headers先向服务器发送请求。
Elements可以帮助我们找到元素的层级,让我们快速锁定元素位置。



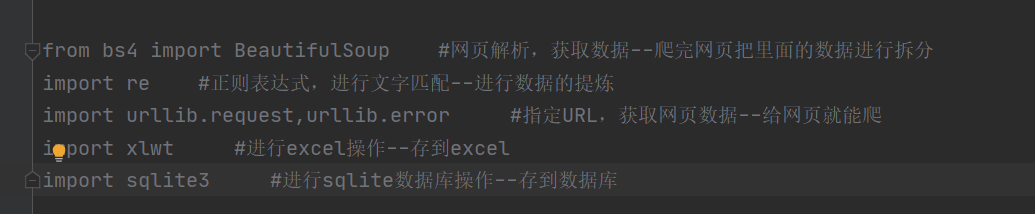
只需安装bs4和xlwt,其他的py3自带

 浙公网安备 33010602011771号
浙公网安备 33010602011771号