
爬虫
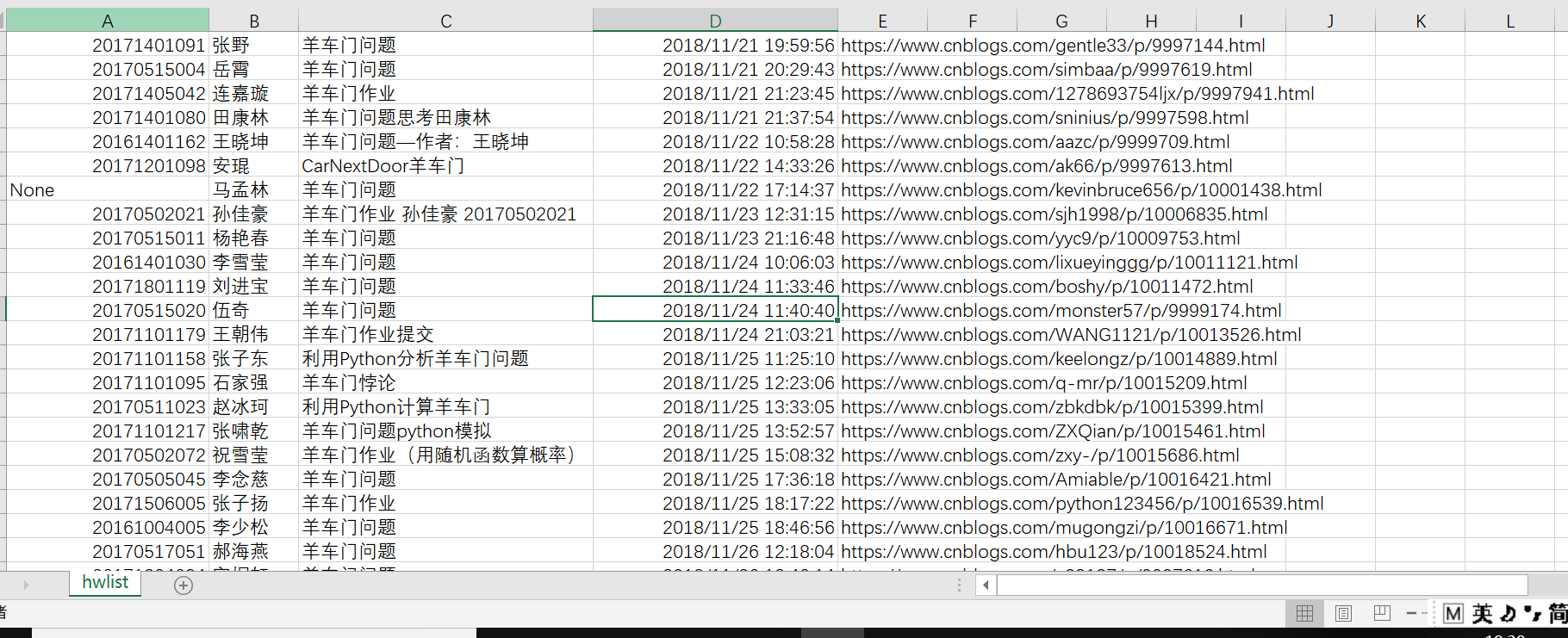
1.爬出来的结果如下,直接爬出来的数据时间格式不对,在excel中进行的修改
2.代码如下:
import requests
import json "判断网址是否请求成功" try: r=requests.get('https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1543716986749') r.raise_for_status() r.text except: print('网络请求不成功') '把文本变成字典' json_data=json.loads(r.text)['data'] '提取所需信息' jieguo='' for j in json_data: jieguo+=str(j['StudentNo'])+','+j['RealName']+','+j['DateAdded'].replace('T',' ')+','+j['Title']+','+j['Url']+'\n' '写入文件' with open('hwlist.csv','w')as f: f.write(jieguo)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号