

一、安装Spark
检查基础环境hadoop,jdk
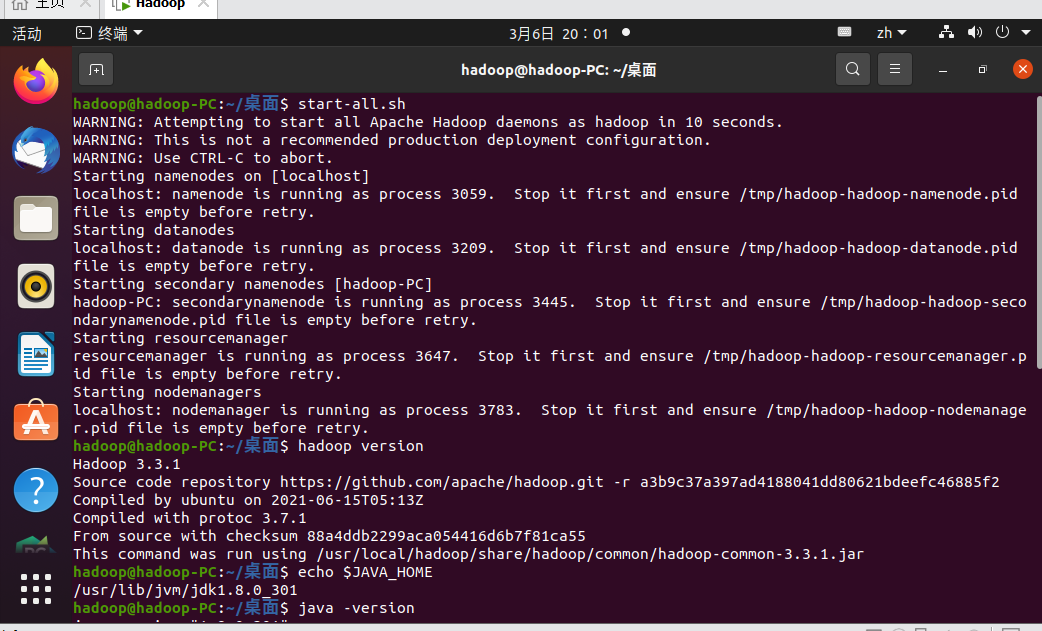
下载Spark
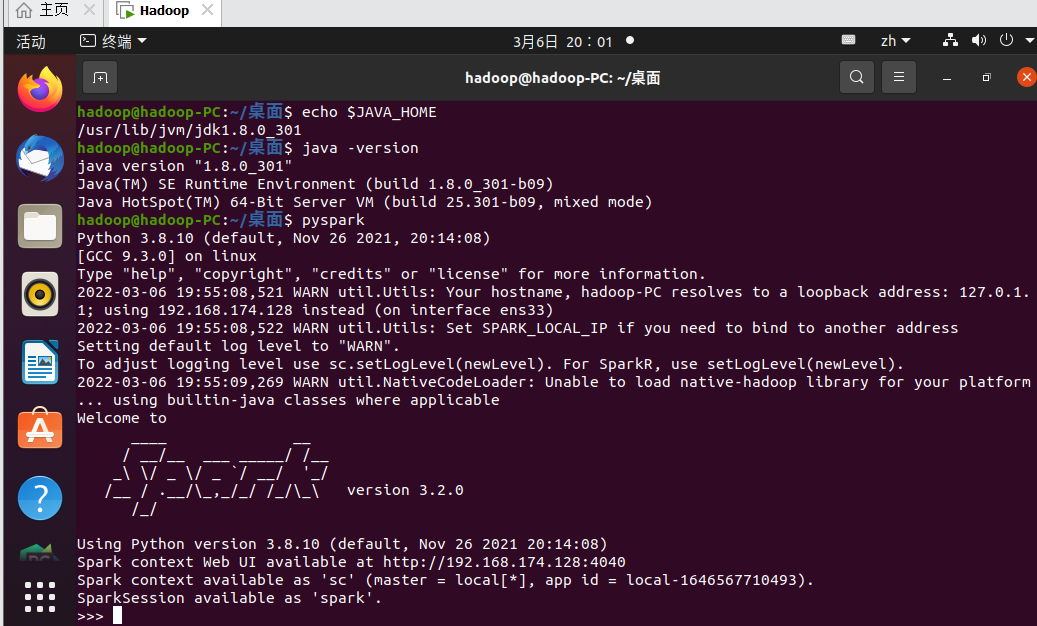
二.Python编程练习:英语文本的词频统计
源代码
# 导入模块 # 导入字符串模块 import string # 2读取文件,并分词 list_dict = {} # 创建一个空字典,放词频与单词,无序排列 data = [] # 创建一个空列表,放词频与单词,有序:从多到少 f = open('test.txt', 'r') # 打开文件 content = f.read() # 读取文件 f.close() # 关闭文件 content = content.replace('-', ' ') # 连字符—用空格代替 words = content.split() # 字符串按空格分割--分词 # 迭代处理:将字典变列表,存入数据 for i in range(len(words)): words[i] = words[i].strip(string.punctuation) # 去掉标点符号,去掉首尾 words[i] = words[i].lower() # 统一大小写 if words[i] in list_dict: # 统计词频与单词 list_dict[words[i]] = list_dict[words[i]] + 1 # 不是第一次 else: list_dict[words[i]] = 1 # 第一次 # print(list_dict) # 打印字典(词频与单词,无序) # 遍历字典 for key, value in list_dict.items(): # 遍历字典
temp = [value, key] # 变量,变量值 data.append(temp) # 添加数据 data.sort(reverse=True) # 排序 print(data) # 打印列表(词频与单词,有序,从多到少)
结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号