HDFS-NameNode元数据和SecondaryNameNode、联邦机制
HDFS元数据是怎么管理的?
总所周知,HDFS的元数据都是保存在NameNode的内存里,放内存的好处很多,读写快,响应快,但是也会有要两个问题:
- 如果服务器重启后内存就会被清空,数据会丢失,数据怎么持久化?
- 单点NameNode的内存是有极限的,怎么扩展? (HDFS集群的性能瓶颈取决NameNode的内存大小)
HDFS是怎么解决第一个问题:( FsImage / Eidts / SecondaryNameNode )
NameNode里面有持久化机制,所有的元数据除了在内存对外提供使用,还会保存在两个重要的文件
- FsImage (元数据信息的镜像)
- FsImage是NameNode中关于元数据的镜像,一般称为检查点,存放比较完整的元数据信息
- 由于是完整的镜像,所以每次加载到内存都非常耗内存和CPU,所以一般都会先把操作记录在Eidts
- 包含了所有当前NameNode下管理的所有DataNode文件和文件block及block的元数据信息
- 随着Eidts内容增大,需要在一定时间点和FsImage合并
- Eidts (客户端的操作日志)
- 存放了客户端最近的操作日志
- 客户端写文件进HDFS时会首先写进Eidts
- Eidts修改时元数据也会更新
FsImage和Eidts 在哪?
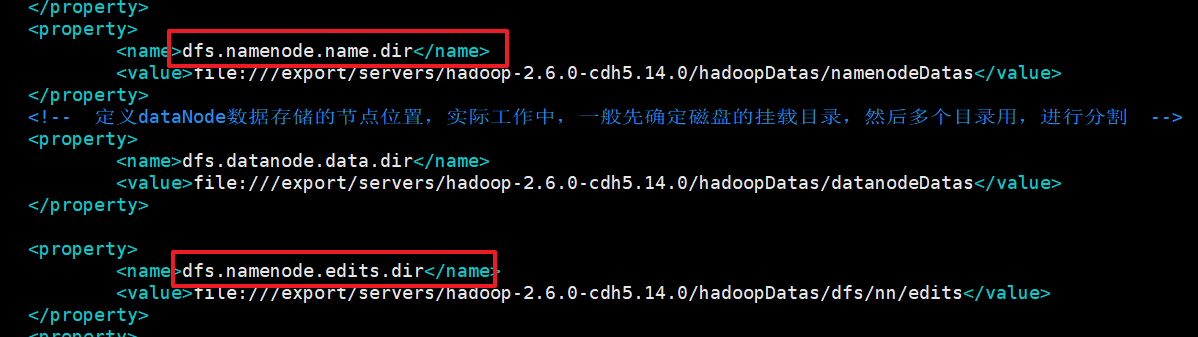
通过hdfs-site.xml 查看和配置:
<!-- FsImage 配置路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/namenodeDatas</value>
</property>
<!-- Edits 配置路径 -->
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/edits</value>
</property>
怎么查看FsImage和Eidts?
#FsImage
hdfs oiv -i fsimage_000001 -p XML -o myfsimage.xml
#Eidts
hdfs oev -i eidts_000001 -p XML -o myedit.xml
延申:当FsImage和Eidts两个文件容量越来越大时,应该怎么解决?(SecondaryNameNode 的辅助就很重要了,但是高可用架构就不需要了)
SecondaryNameNode的作用:定期合并FsImage和Eidts,把Eidts控制在范围内。
第二问题怎么解决:(HA+Federation)联邦机制
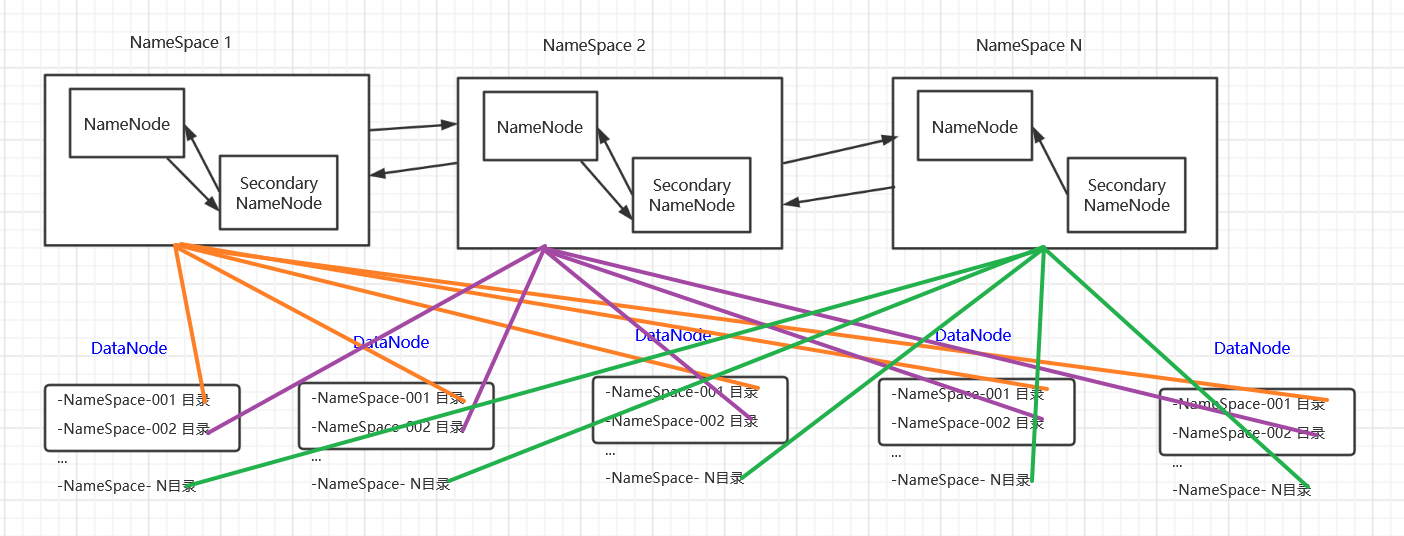
当集群大到一定程度的时候,NameNode进程使用的内存可能会达上百G,NameNode就成为了性能的瓶颈,所以HDFS提出NameNode水平扩展方案,即联邦机制(Federation).这个时候一个NameNode和SecondaryNode就看作是一个整体,即一个NameSpace。
-
多个NameNode共用一个集群的资源,每台NameNode都可以单独对外提供服务
-
每个NameNode都会定义一个存储池,有单独的ID,每个DataNode都为所有存储池提供存储,具体见于每个DataNode都会有单独的目录存储不同NameNode的数据,例如:NameNode-01目录、NameNode-02目录、NameNode-03目录...
-
DataNode 会按照存储池id向其对应的NameNode汇报块信息,例如NameNode-01目录向NameNode1汇报等。同时DataNode会向所有的NameNode汇报本地存储可用资源情况。
Federation的不足:由于Federation并没有完全解决单点故障问题,所以每个NameNode都跟单点部署一样需要配置SecondaryNameNode来辅助恢复还原挂掉的NameNode元数据信息。
所以一般集群规模很大的时候,就会采用HA(高可用)+Federation(联邦)的部署方案,也就是每个联合的NameNode(NameSpace)都是HA的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号