
Hadoop+Spark:集群环境搭建
- 环境准备:
在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.04.2-server-amd64.iso):
192.168.1.200 master
192.168.1.201 node1
192.168.1.202 node2
- 在Master上安装Spark环境:
Spark集群环境搭建:
搭建hadoop集群使用hadoop版本是hadoop2.6.4(这里hadoop我已经安装完成,具体如何安装hadoop具体请参考我的文章:《Hadoop:搭建hadoop集群》)
搭建spark这里使用spark版本是spark1.6.2(spark-1.6.2-bin-hadoop2.6.tgz)
1、下载安装包到master虚拟服务器:
在线下载:
hadoop@master:~/ wget http://mirror.bit.edu.cn/apache/spark/spark-1.6.2/spark-1.6.2-bin-hadoop2.6.tgz
离线上传到集群:
2、解压spark安装包到master虚拟服务器/usr/local/spark下,并分配权限:
#解压到/usr/local/下
hadoop@master:~$ sudo tar -zxvf spark-1.6.2-bin-hadoop2.6.tgz -C /usr/local/ hadoop@master:~$ cd /usr/local/ hadoop@master:/usr/local$ ls bin games include man share src etc hadoop lib sbin spark-1.6.2-bin-hadoop2.6
#重命名 为spark hadoop@master:/usr/local$ sudo mv spark-1.6.2-bin-hadoop2.6/ spark/ hadoop@master:/usr/local$ ls bin etc games hadoop include lib man sbin share spark src
#分配权限 hadoop@master:/usr/local$ sudo chown -R hadoop:hadoop spark hadoop@master:/usr/local$
3、在master虚拟服务器/etc/profile中添加Spark环境变量:
编辑/etc/profile文件
sudo vim /etc/profile
在尾部添加$SPARK_HOME变量,添加后,目前我的/etc/profile文件尾部内容如下:
export JAVA_HOME=/usr/lib/jvm/java-8-oracle export JRE_HOME=/usr/lib/jvm/java-8-oracle export SCALA_HOME=/opt/scala/scala-2.10.5 # add hadoop bin/ directory to PATH export HADOOP_HOME=/usr/local/hadoop export SPARK_HOME=/usr/local/spark export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$JAVA_HOME:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$SPARK_HOME/bin:$PATH export CLASSPATH=$CLASS_PATH::$JAVA_HOME/lib:$JAVA_HOME/jre/lib
生效:
source /etc/profile
- 在Master配置Spark:
1、配置master虚拟服务器hadoop-env.sh文件:
sudo vim /usr/local/spark/conf/hadoop-env.sh
注意:默认情况下没有hadoop-env.sh和slaves文件,而是*.template文件,需要重命名:
hadoop@master:/usr/local/spark/conf$ ls docker.properties.template metrics.properties.template spark-env.sh fairscheduler.xml.template slaves.template log4j.properties.template spark-defaults.conf.template hadoop@master:/usr/local/spark/conf$ sudo vim spark-env.sh hadoop@master:/usr/local/spark/conf$ mv slaves.template slaves
在文件末尾追加如下内容:
export STANDALONE_SPARK_MASTER_HOST=192.168.1.200 export SPARK_MASTER_IP=192.168.1.200 export SPARK_WORKER_CORES=1 #every slave node start work instance count export SPARK_WORKER_INSTANCES=1 export SPARK_MASTER_PORT=7077 export SPARK_WORKER_MEMORY=1g export MASTER=spark://${SPARK_MASTER_IP}:${SPARK_MASTER_PORT} export SCALA_HOME=/opt/scala/scala-2.10.5 export JAVA_HOME=/usr/lib/jvm/java-8-oracle export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://192.168.1.200:9000/SparkEventLog" export SPARK_WORKDER_OPTS="-Dspark.worker.cleanup.enabled=true" export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
2、配置master虚拟服务器下slaves文件:
sudo vim /usr/local/spark/conf/slaves
在slaves文件中内容如下:
192.168.1.201 192.168.1.202
注意:每行写一个机器的ip。
3、Master虚拟机下/usr/local/spark/目录下创建logs文件夹,并分配777权限:
hadoop@master:/usr/local/spark$ mkdir logs hadoop@master:/usr/local/spark$ chmod 777 logs
- 复制Master虚拟服务器上的/usr/loca/spark下文件到所有slaves节点(node1、node2)下:
1、复制Master虚拟服务器上/usr/local/spark/安装文件到各个salves(node1、node2)上:
注意:拷贝钱需要在ssh到所有salves节点(node1、node2)上,创建/usr/local/spark/目录,并分配777权限。
hadoop@master:/usr/local/spark/conf$ cd ~/ hadoop@master:~$ sudo chmod 777 /usr/local/spark hadoop@master:~$ scp -r /usr/local/spark hadoop@node1:/usr/local scp: /usr/local/spark: Permission denied hadoop@master:~$ sudo scp -r /usr/local/spark hadoop@node1:/usr/local hadoop@node1's password: scp: /usr/local/spark: Permission denied hadoop@master:~$ sudo chmod 777 /usr/local/spark hadoop@master:~$ ssh node1 Welcome to Ubuntu 14.04.2 LTS (GNU/Linux 3.16.0-30-generic x86_64) * Documentation: https://help.ubuntu.com/ System information as of Fri Sep 23 16:40:31 UTC 2016 System load: 0.08 Processes: 400 Usage of /: 12.2% of 17.34GB Users logged in: 0 Memory usage: 5% IP address for eth0: 192.168.1.201 Swap usage: 0% Graph this data and manage this system at: https://landscape.canonical.com/ New release '16.04.1 LTS' available. Run 'do-release-upgrade' to upgrade to it. Last login: Wed Sep 21 16:19:25 2016 from master hadoop@node1:~$ cd /usr/local/ hadoop@node1:/usr/local$ sudo mkdir spark [sudo] password for hadoop: hadoop@node1:/usr/local$ ls bin etc games hadoop include lib man sbin share spark src hadoop@node1:/usr/local$ sudo chmod 777 ./spark hadoop@node1:/usr/local$ exit hadoop@master:~$ scp -r /usr/local/spark hadoop@node1:/usr/local ........... hadoop@master:~$ ssh node2 Welcome to Ubuntu 14.04.2 LTS (GNU/Linux 3.16.0-30-generic x86_64) * Documentation: https://help.ubuntu.com/ System information as of Fri Sep 23 16:15:03 UTC 2016 System load: 0.08 Processes: 435 Usage of /: 13.0% of 17.34GB Users logged in: 0 Memory usage: 6% IP address for eth0: 192.168.1.202 Swap usage: 0% Graph this data and manage this system at: https://landscape.canonical.com/ Last login: Wed Sep 21 16:19:47 2016 from master hadoop@node2:~$ cd /usr/local hadoop@node2:/usr/local$ sudo mkdir spark [sudo] password for hadoop: hadoop@node2:/usr/local$ sudo chmod 777 ./spark hadoop@node2:/usr/local$ exit logout Connection to node2 closed. hadoop@master:~$ scp -r /usr/local/spark hadoop@node2:/usr/local ...........
2、修改所有salves节点(node1、node2)上/etc/profile,追加$SPARK_HOME环境变量:
注意:一般都会遇到权限问题。最好登录到各个salves节点(node1、node2)上手动编辑/etc/profile。
hadoop@master:~$ ssh node1 Welcome to Ubuntu 14.04.2 LTS (GNU/Linux 3.16.0-30-generic x86_64) * Documentation: https://help.ubuntu.com/ System information as of Fri Sep 23 16:42:44 UTC 2016 System load: 0.01 Processes: 400 Usage of /: 12.2% of 17.34GB Users logged in: 0 Memory usage: 5% IP address for eth0: 192.168.1.201 Swap usage: 0% Graph this data and manage this system at: https://landscape.canonical.com/ New release '16.04.1 LTS' available. Run 'do-release-upgrade' to upgrade to it. Last login: Fri Sep 23 16:40:52 2016 from master hadoop@node1:~$ sudo vim /etc/profile [sudo] password for hadoop: hadoop@node1:~$ exit logout Connection to node1 closed. hadoop@master:~$ ssh node2 Welcome to Ubuntu 14.04.2 LTS (GNU/Linux 3.16.0-30-generic x86_64) * Documentation: https://help.ubuntu.com/ System information as of Fri Sep 23 16:44:42 UTC 2016 System load: 0.0 Processes: 400 Usage of /: 13.0% of 17.34GB Users logged in: 0 Memory usage: 5% IP address for eth0: 192.168.1.202 Swap usage: 0% Graph this data and manage this system at: https://landscape.canonical.com/ New release '16.04.1 LTS' available. Run 'do-release-upgrade' to upgrade to it. Last login: Fri Sep 23 16:43:31 2016 from master hadoop@node2:~$ sudo vim /etc/profile [sudo] password for hadoop: hadoop@node2:~$ exit logout Connection to node2 closed. hadoop@master:~$
修改后的所有salves上/etc/profile文件与master节点上/etc/profile文件配置一致。
- 在Master启动spark并验证是否配置成功:
1、启动命令:
一般要确保hadoop已经启动,之后才启动spark
hadoop@master:~$ cd /usr/local/spark/ hadoop@master:/usr/local/spark$ ./sbin/start-all.sh
2、验证是否启动成功:
方法一、jps
hadoop@master:/usr/local/spark$ ./sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-master.out 192.168.1.201: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node1.out 192.168.1.202: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node2.out hadoop@master:/usr/local/spark$ jps 1650 NameNode 1875 SecondaryNameNode 3494 Jps 2025 ResourceManager 3423 Master hadoop@master:/usr/local/spark$ cd ~/ hadoop@master:~$ ssh node1 Welcome to Ubuntu 14.04.2 LTS (GNU/Linux 3.16.0-30-generic x86_64) * Documentation: https://help.ubuntu.com/ System information as of Fri Sep 23 17:33:40 UTC 2016 System load: 0.06 Processes: 402 Usage of /: 13.9% of 17.34GB Users logged in: 0 Memory usage: 21% IP address for eth0: 192.168.1.201 Swap usage: 0% Graph this data and manage this system at: https://landscape.canonical.com/ New release '16.04.1 LTS' available. Run 'do-release-upgrade' to upgrade to it. Last login: Fri Sep 23 17:33:10 2016 from master hadoop@node1:~$ jps 1392 DataNode 2449 Jps 2330 Worker 2079 NodeManager hadoop@node1:~$ exit logout Connection to node1 closed. hadoop@master:~$ ssh node2 Welcome to Ubuntu 14.04.2 LTS (GNU/Linux 3.16.0-30-generic x86_64) * Documentation: https://help.ubuntu.com/ System information as of Fri Sep 23 17:33:40 UTC 2016 System load: 0.07 Processes: 404 Usage of /: 14.7% of 17.34GB Users logged in: 0 Memory usage: 20% IP address for eth0: 192.168.1.202 Swap usage: 0% Graph this data and manage this system at: https://landscape.canonical.com/ New release '16.04.1 LTS' available. Run 'do-release-upgrade' to upgrade to it. Last login: Fri Sep 23 16:51:36 2016 from master hadoop@node2:~$ jps 2264 Worker 2090 NodeManager 1402 DataNode 2383 Jps hadoop@node2:~$
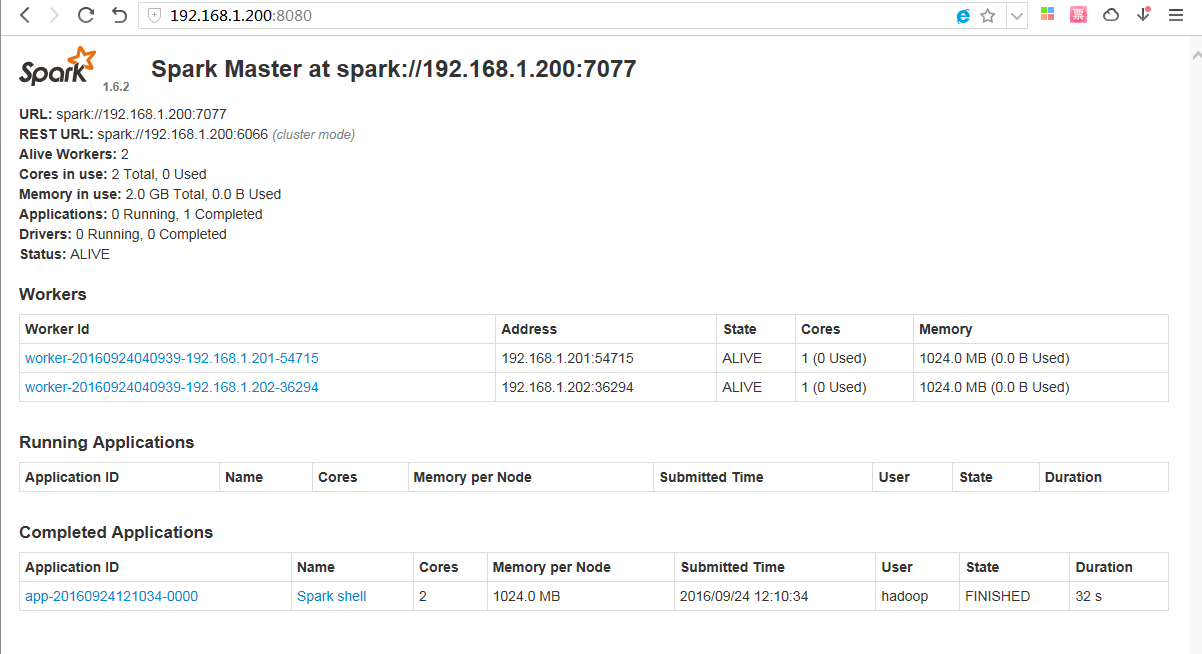
方法二、web方式http://192.168.1.200:8080看是否正常:
基础才是编程人员应该深入研究的问题,比如:
1)List/Set/Map内部组成原理|区别
2)mysql索引存储结构&如何调优/b-tree特点、计算复杂度及影响复杂度的因素。。。
3)JVM运行组成与原理及调优
4)Java类加载器运行原理
5)Java中GC过程原理|使用的回收算法原理
6)Redis中hash一致性实现及与hash其他区别
7)Java多线程、线程池开发、管理Lock与Synchroined区别
8)Spring IOC/AOP 原理;加载过程的。。。
【+加关注】。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号