


实用指南:HTTP和HTTPS
大规模使用的版本是HTTP/1.1
使用HTTP协议的场景:
1.浏览器打开网站(基本上)---》网页和后台服务器的交互
2.手机APP访问对应的服务器(大概率)----》app和后台服务器的交互
HTTP协议的报文格式
1.请求
2.响应
HTTP协议是一种”一问一答“结构模型的协议
一问一答(访问网站)
多问一答(上传文件)
一问一答(下载记录)
多问多答(串流/远程桌面)
如何查看到HTTP请求和响应的格式?
抓包工具:把网卡上经过的素材获取到并表现出来
Fiddler(专门抓HTTP的)
下载软件都要去官方网站
安装一路Next
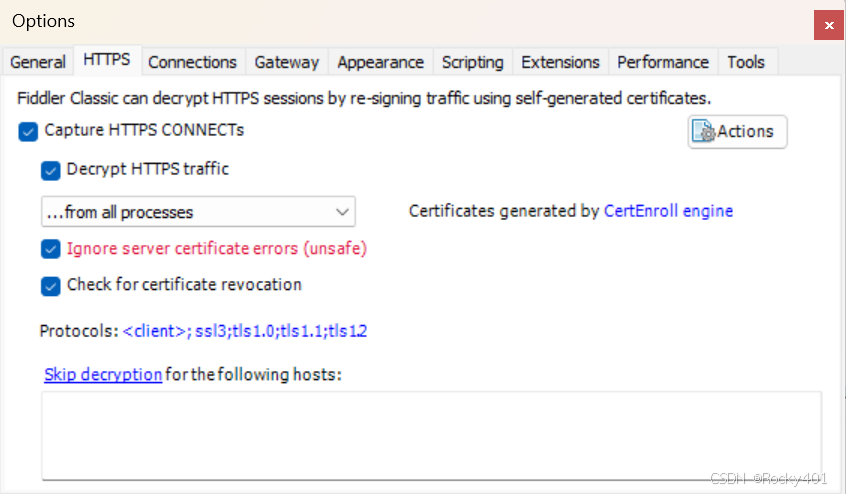
因为现在互联网环境,以HTTPS为主,纯的HTTP少见。
安装的fiddler应该手动开启HTTPS功能,并且安装证书。
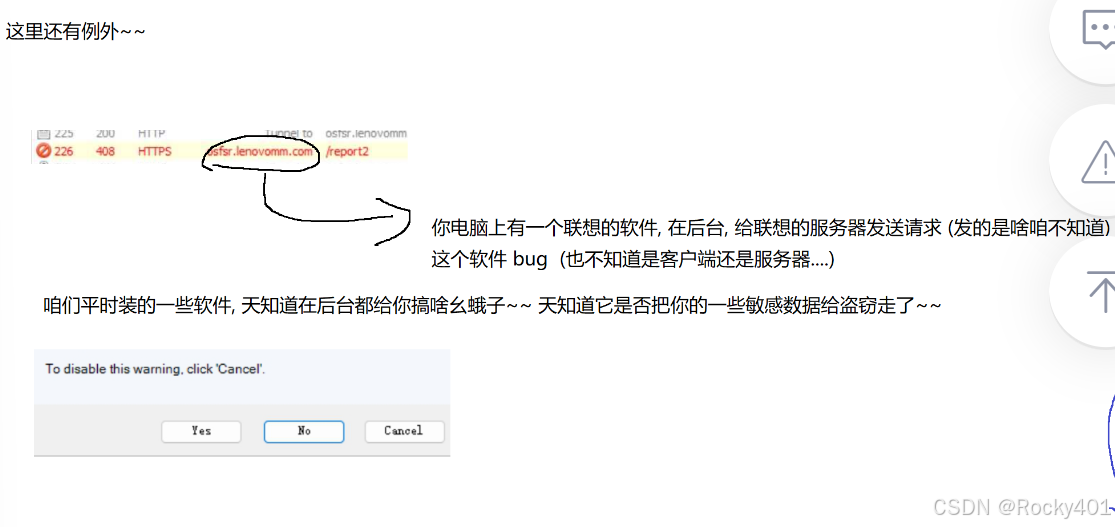
一个”代理“,可能会与其它代理软件冲突就是Fiddler本质上
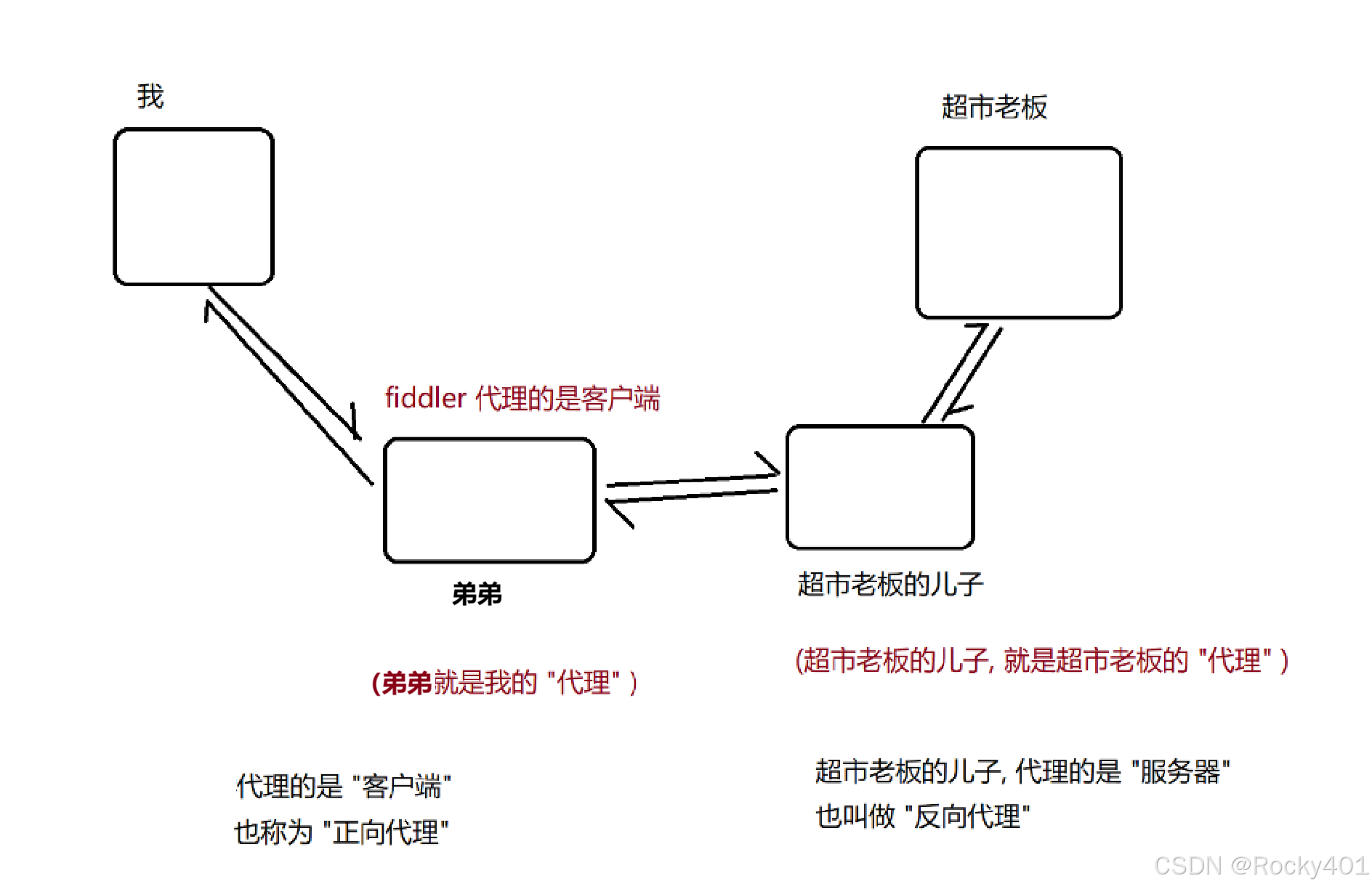
通过代理程序就能够获取到请求和响应的详细内容
其它代理程序
1)加速器
2)vpn
一个浏览器插件),还可以尝试不同的浏览器。就是使用fiddler不能抓包时,检查关闭之前的代理软件(有可能
Fiddler的利用:
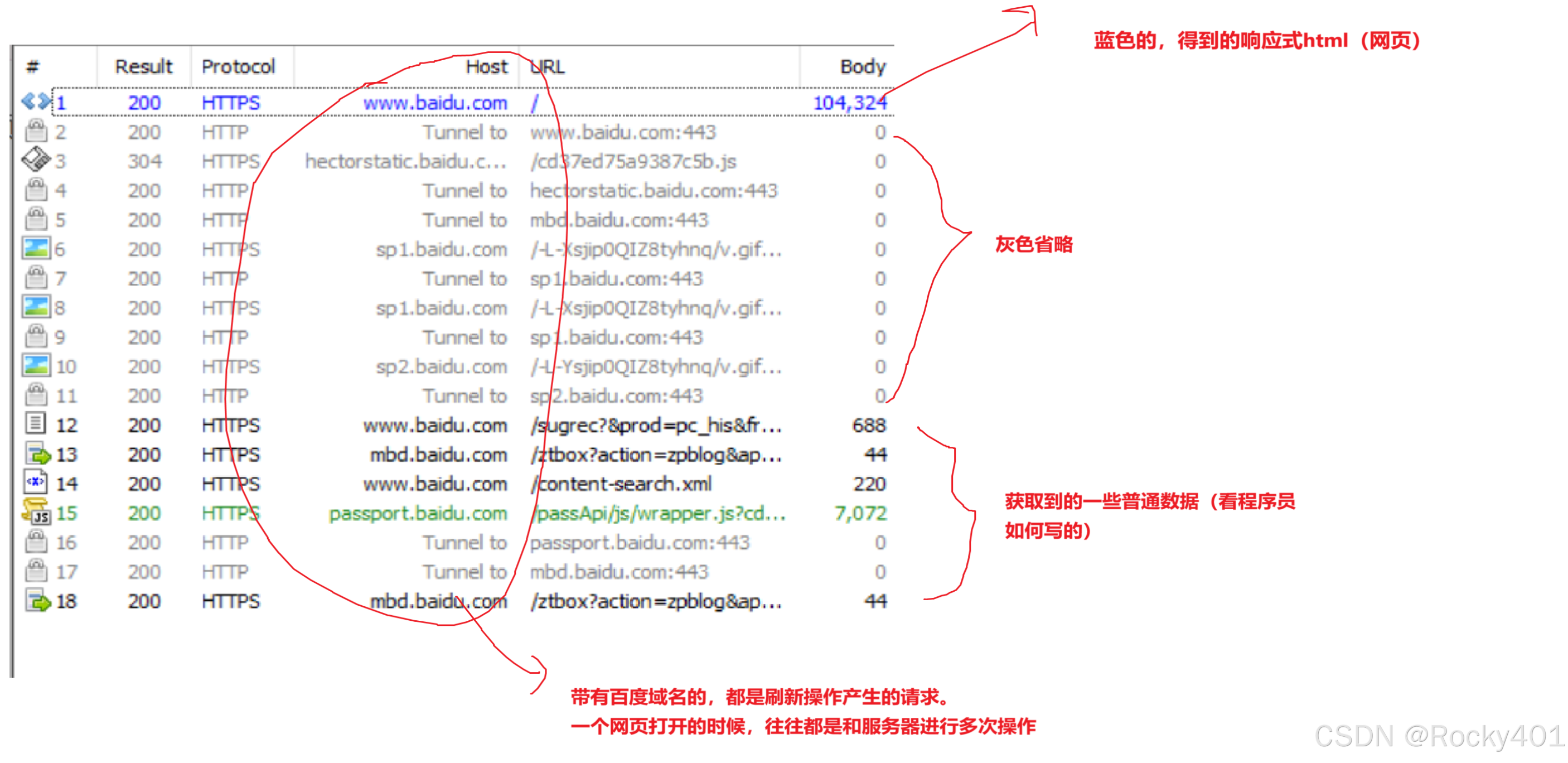
通过抓包,可能很好理解协议的格式。
分析清楚了请求的详细情况,就可以使用代码模拟构造出一样的请求,达到一些特定的效果。
(自动点赞。。。抢票。。。)
请求:
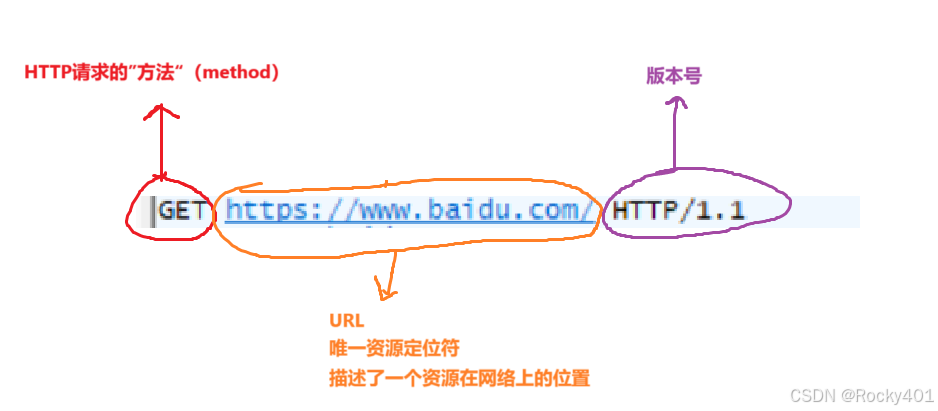
1.首行
HTTP请求的第一行,有三个部分信息,用空格分割开
2.请求头(header)
键值对结构
每个键值对独占一行
键和值之间,使用:空格来区分

3.空行
请求头的结束标记
4.正文(body)
有的HTTP请求有,有的没有
响应:
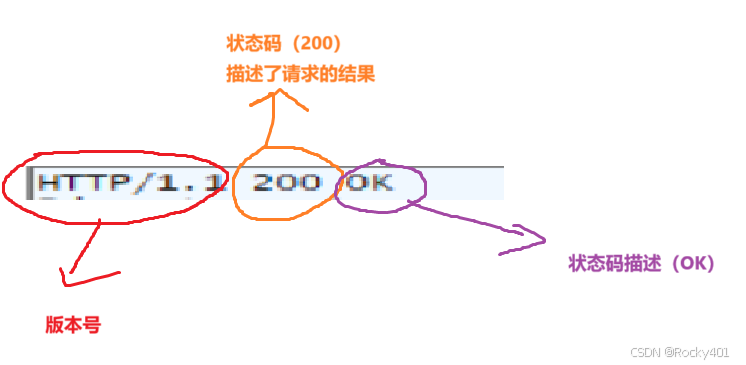
1.首行
2.响应头(header)
键值对
3.空行
响应头结束的标记
4.正文(body)
内容可能比较长,可能是多种格式
HTML,CSS,JS,JSON,XML,图片,字体,视频,音频

URL
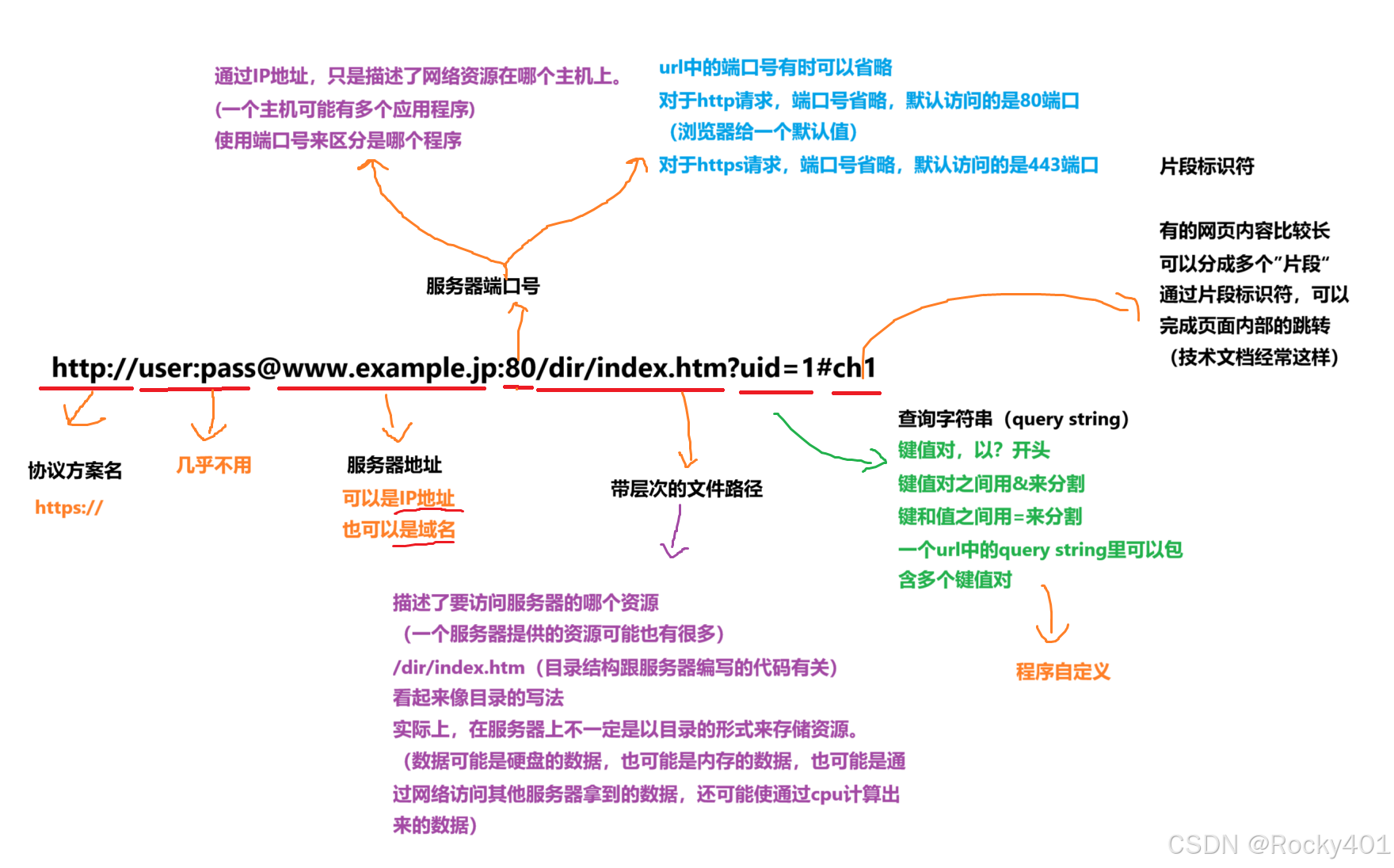
eg:
http://宁理餐厅:10/梅菜大饼/梅菜猪肉大饼?葱=不要&辣椒=不要
对于query string来说,如果value部分要包含一些特殊符号的话,往往应该进行urlencode
+?:/ ...... 这些符号在url中已经有特殊用途
假如在value中也包括特殊符号,可能就会使浏览器/http服务器,对于url的解析出现bug
urlencode本质上是一种"转义字符"
eg:
+的ascii就是2B,在前面加上%就是转义的结果
中文汉字都要求转义
!!!所以一定要记得做urlencode
方法:
POST
1)登录
2)上传文档
GET请求,通常会把要传给服务器的数据,加到url的query string中
POST请求,通常会把要传给服务器的数据,加到body中
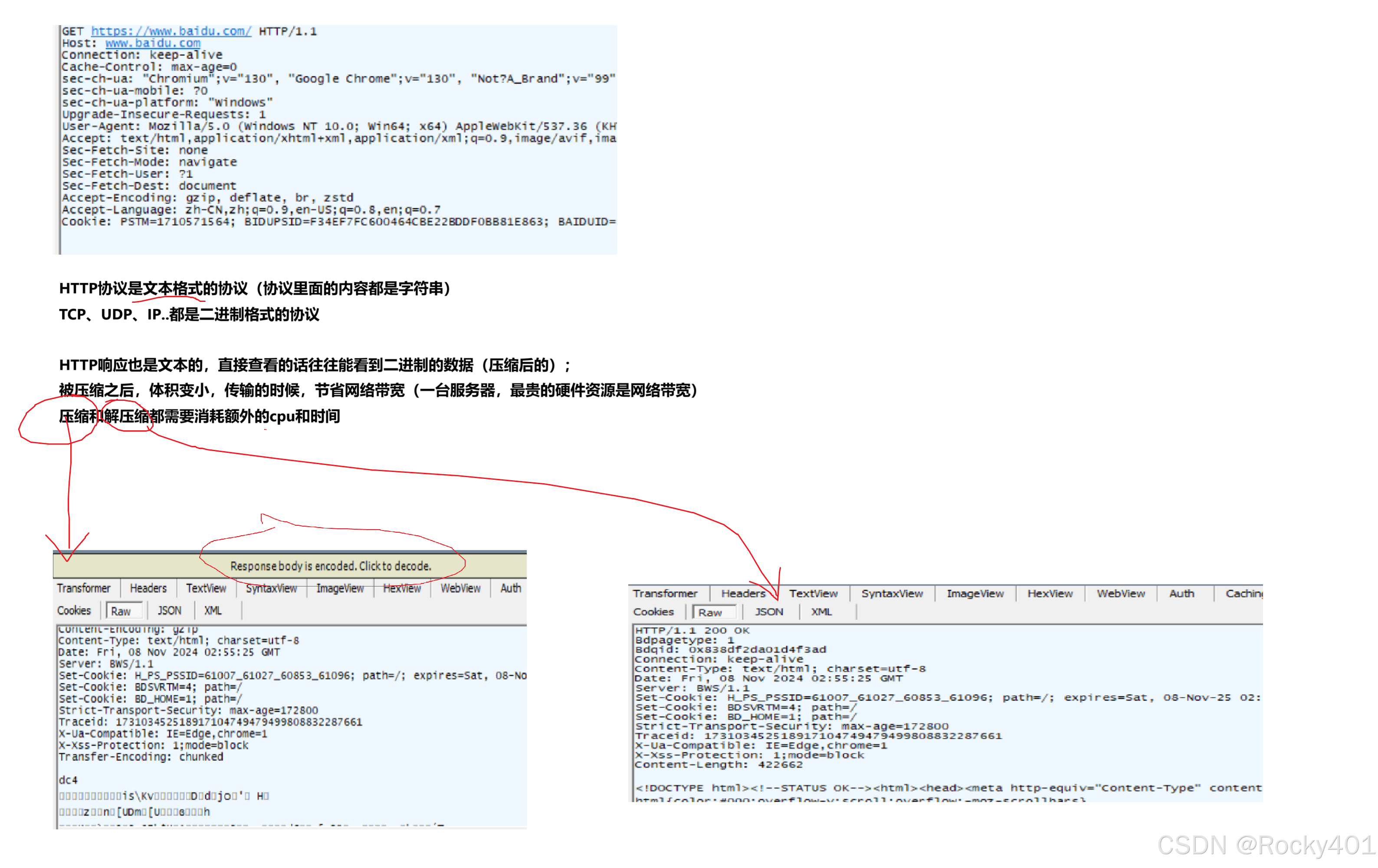
蓝色字体,是获取到网页(得到html的响应)
一开始没有抓到返回页面的请求,是因为命中了浏览器的缓存
浏览器显示的网页,是从服务器下载的html。
html内容可能比较多,体积可能比较大。通过网络加载,消耗的时间可能比较多。
浏览器一般都会自己带有缓存,就会把之前加载过的页面,保存到本地的硬盘,下次访问直接读取本地硬盘的资料即可。
当我们上传头像时,
body就是图片本体
图片本身是二进制数据
把图片放到http请求中,往往要进行base64转码。
(针对二进制数据重新编码(转义), 确保编码之后的数据是纯文本的数据)
GET和POST的区别
本质上,没有区别;
习惯上,存在差异
1.GET常常把传递给服务器的素材放到query string中;
POST经常放到body中
(并非绝对)
2.语义上的差异。
GET大多数还是用来获取数据
POST大多数还是用来提交数据(登录和上传)
GET和POST相关说法的判断
1.GET请求能传递的数据量有上限,POST传递的数据量没有上限。(X)
通过RFC标准文档并没有明确规定URL有多长,目前的浏览器和服务器的实现过程中,URL是允许很长的。(甚至能够用URL来传递一些图片这样的素材)
2.GET请求传递数据不安全,POST请求传递数据更安全(X)
如果用GET请求来实现登录,点击登录就会把账号和密码放到url中,进一步表明到浏览器地址栏中,就被别人看见了。
假设用POST请求来建立登录,账号和密码则是在body中,不会显现出来,所以更安全。
其实并不是这样,安全性首要在于加密!!!!!!
3.GET只能给服务器传输文本数据 , POST许可给服务器传输文本和二进制素材(X)
通过 1)GET能够使用body(body能够直接放二进制)
2)GET也可以把二进制的数据进行base64转码,放到url的query string中
1.GET请求是幂等的,POST请求不是幂等的。(不够准确,但不完全错)
GET和POST具体是否是幂等的,取决于代码的实现。
GET是否幂等,不绝对。
只是RFC标准文档上,建议GET请求实现成幂等。
eg:
吃进去的是草,挤出来的是奶
幂等的就是要是任何时候吃草,挤出来的是奶,就
幂等的就是如果吃草之后,不同时候挤出来的东西不一样,就不
GET不幂等的情况:
广告数据就是通过GET请求获取到的。这些GET请求设计的时候一定是不幂等的。
哪些广告,广告的顺序
2.GET请求可以被浏览器缓存,POST不许可被缓存(√)
(幂等性的延续。如果请求是幂等,自然许可被缓存)
3.GET请求行被浏览器收藏夹收藏,POST则不能(收藏的时候可能会丢失body)(√)
Header
Host:
![]()
在url中也存在
在采用代理的情况下,Host的内容可能和url中的内容不同
Content-Length:body中内容的长度
Content-Type:body中数据的格式
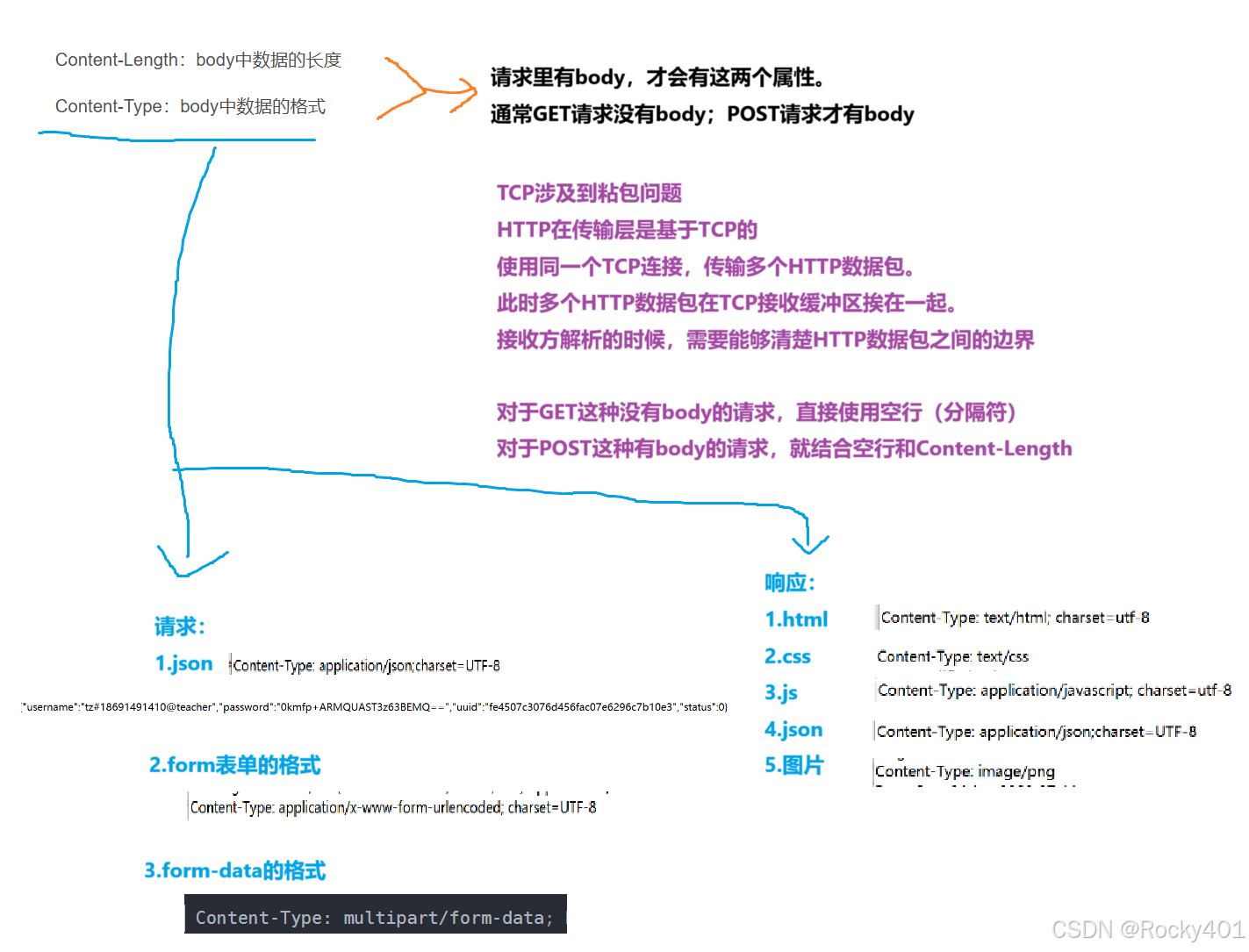
服务器提交给请求,不同的Content-Type,服务器处理数据的逻辑不同;
服务器返回给浏览器,也需要设置合适的Content-Type。
浏览器会根据不同的Content-Type做出不同的处理
User-Agent(简称UA)

一开始主导用于是否要兼容旧版本的浏览器
可以用User-Agent来区分
UA记录了浏览器的版本,哪个版本的浏览器支撑哪些特性
现在浏览器差异变小,关键用于区分PC端还是移动端
做区分是为了进行统计,而不会返回不同版本的页面。
现在前端开发,有”响应式网页“编程技术,同一个html可以很好兼容不同的设备
从哪个页面跳转过来的就是Referer描述了当前页面

假设是直接在地址栏中输入url(或者点击收藏夹中的按钮)都是没有Referer
广告主可以在百度等平台投放广告
通过来自搜狗就是广告主的服务器能够根据Referer来区分,哪些请求是来自百度,哪些请求
![]()
HTTP最大的问题在于”明文传输“,明文传输容易被第三方获取并篡改。
HTTPS针对HTTP数据进行加密(header和body都进行了加密)
第三方要想获取和篡改,就不容易。
通过HTTPS,可以有用遏制运营商劫持的情况。
响应状态码
表示这次请求对应的响应,是啥样的状态(成功、失败,其它的情况)
1. 2xx表示成功
2. 3xx表示重定向
很多时候,页面跳转,可以通过重定向实现。
有时候,某个网站,服务器迁移了(IP/域名变了)
就许可给旧的地址挂一个重定向响应。
访问旧的地址的用户会自动跳转到新的地址
3. 500(代码有bug)
4. 404 Not Found
请求中访问的资源,在服务器上不存在
同时在body中也许可返回一个指定的错误页面。
5. Forbidden
表示访问的资源没有权限
6. 特殊的状态码:418
无实际意义,只是"开个玩笑"。
项目中不要开玩笑!!!!
7. 5xx表示服务器出错了,看到这个说明服务器挂了。
如何让客户端构造一个HTTP请求
浏览器
1.直接在浏览器地址栏输入一个url,此时构造了一个GET请求。
2.html中,一些特殊的html标签,可能会触发GET请求
eg:img,a,link,script
3.通过form表单来触发GET/POST请求
一个HTML标签就是form本质上
HTML、CSS、JS也是编程语言,不过是运行在浏览器上。
不像C需要安装VS,java需要安装JDK,只需要浏览器就行。
4.ajax
5.postman(图形化界面)构造请求
HTTPS
在HTTP的基础上,HTTP引入了"加密"的机制,防止数据被黑客篡改。(反针对运营商劫持)
采用密钥(yue四声?yao四声?shi二声?)加密
1.对称加密
加密和解密,使用的密钥,是同一个密钥。
设密钥为key
明文+key =>密文
密文+key =>明文
2.非对称加密
有两个密钥,一个是"公钥",一个是"私钥"。(公钥是许可公开的,私钥是藏好的)
明文+公钥 => 密文
密文+私钥 => 明文
或者
明文+私钥 => 密文
密文+公钥 => 明文
eg:下去楼下的邮箱
提供一把锁(公钥,给邮递员)和一把钥匙(私钥,自己私有)
邮递员把信锁到信箱中(使用公钥加密)
我拿着钥匙开锁,拿到信(运用私钥解密)
锁和钥匙是配对的(公钥和私钥也是配对的)
HTTPS的工作过程
针对HTTP这里的header和body进行加密
1.先引入对称加密
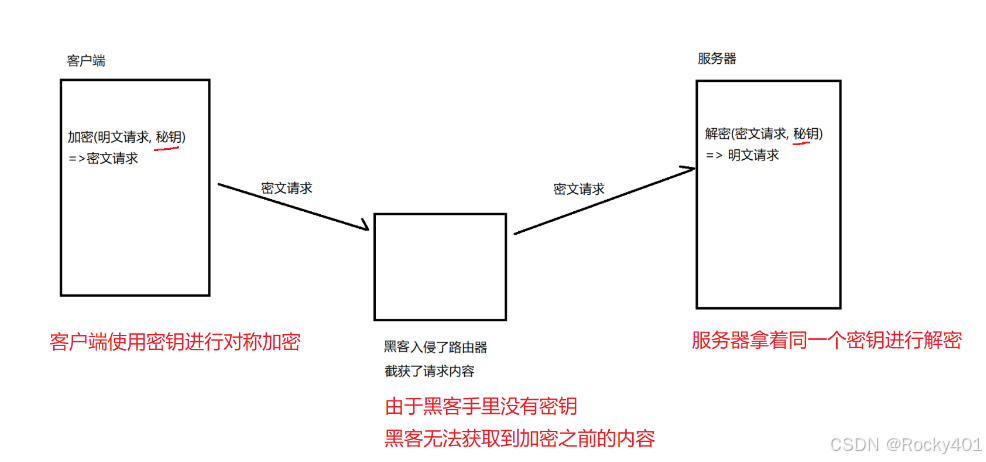
比较安全(不存在绝对安全)
当服务器和多个客户端通信的时候,每个客户端的密钥都不同
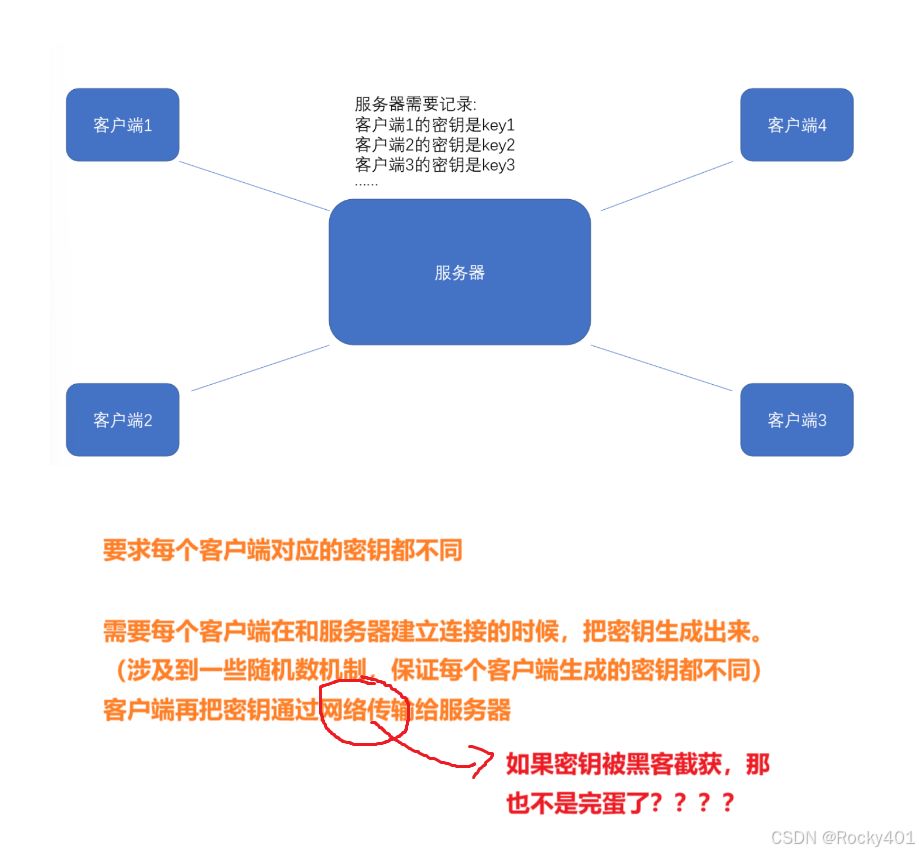
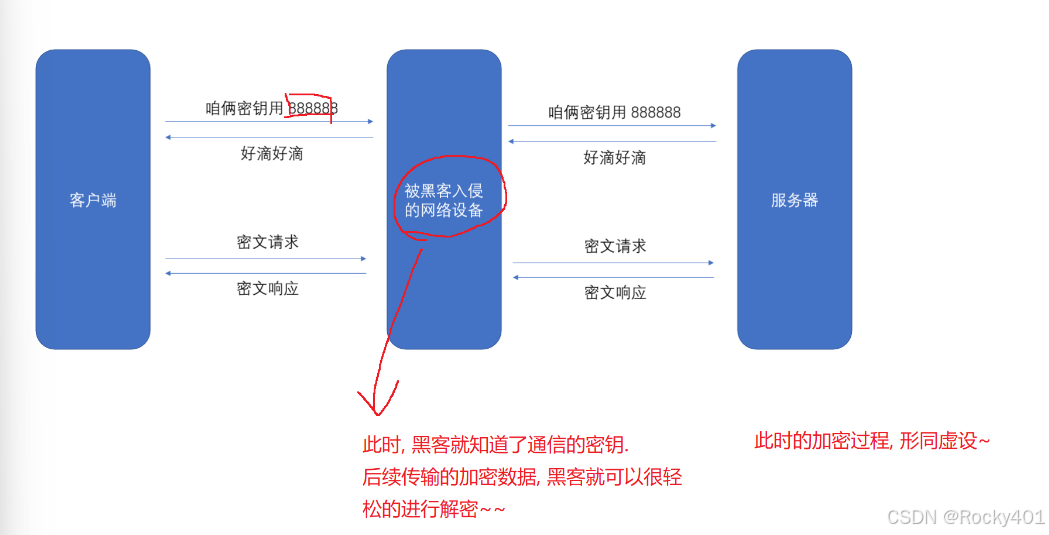
2.因而我们需要对密钥进行加密,引入了"非对称加密"
非对称加密,有一对密钥:公钥和密钥
可以使用公钥加密,私钥解密;
或者采用私钥加密,公钥解密。
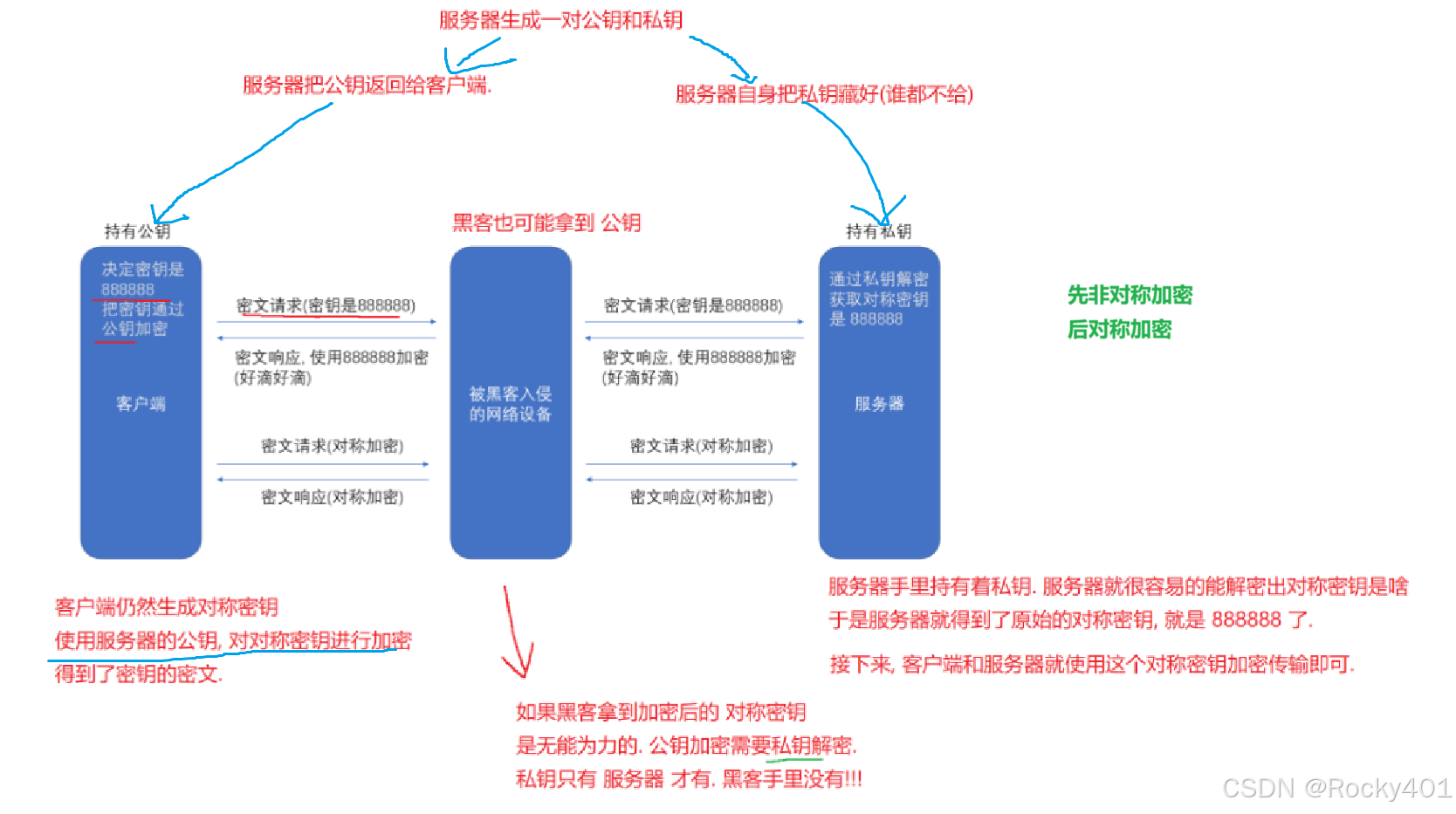
使用非对称加密,成本高,传输效率低;
使用对称加密,成本低,传输效率高。
所以非对称仅仅用来传输密钥,大量业务素材都是用对称加密。
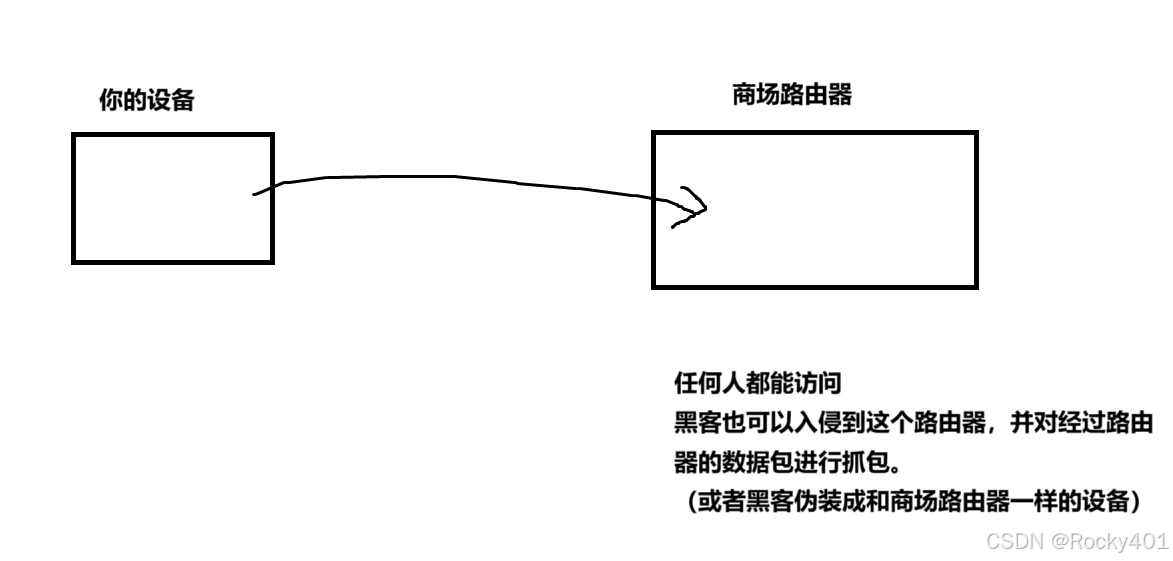
3.中间人攻击问题
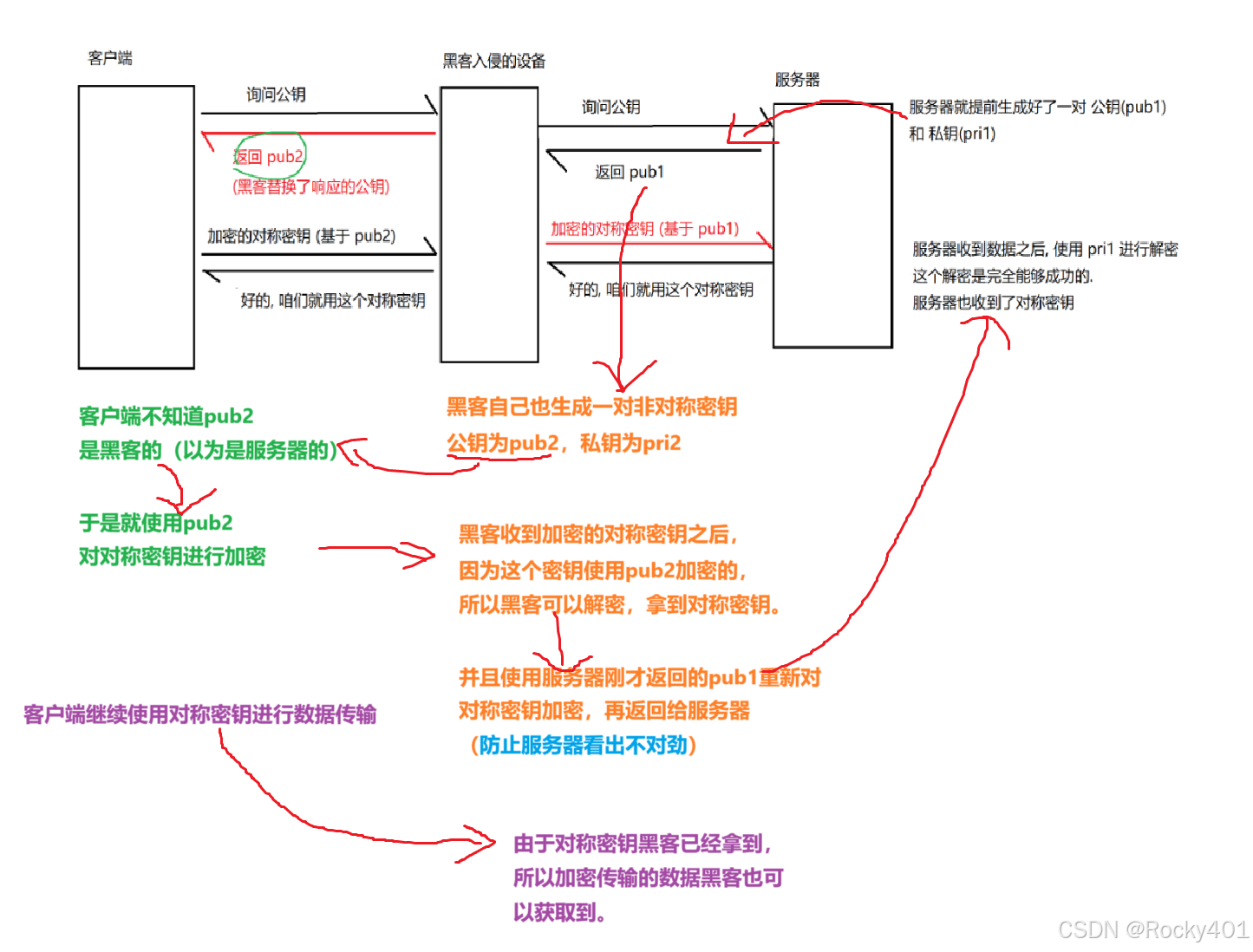
如何应对中间人攻击障碍呢?
由于客户端没有'分辨能力',所以引入了第三方大家都信任的'公证机构'。
被伪造的,就可以信任。就是公证机构说这个公钥是正确的,不

 浙公网安备 33010602011771号
浙公网安备 33010602011771号