
实用指南:Java学习day_14之API(正则表达式)
Java正则表达式是一种用于匹配、查找或操作字符串的强大工具,基于java.util.regex包实现。其核心类包括Pattern(编译正则表达式)和Matcher(执行匹配操作)。
一、检验字符串是否满足规则
字符类(只匹配一个字符)
| [abc] | 只能是abc |
|---|---|
| [^abc] | 除abc之外的任何字符 |
| [a-zA-Z] | a到z A到Z |
| [a-dm-p] | a到d,或m到p |
| [a-z&&[def]] | a-z和def的交集 |
| [a-z&&[^bc]] | a-z与非bc的交集 [ad-z] |
| [a-z&&[^m-p]] | a-z和除了m到p的交集 [a-lq-z] |
public class RegexDemo2 {
public static void main(String[] args) {
//只匹配一个字符
//[abc]
System.out.println("----------1-----------");
System.out.println("a".matches("[abc]"));//true
System.out.println("z".matches("[abc]"));//false
System.out.println("ab".matches("[abc]"));//false
//[^abc]
System.out.println("----------2-----------");
System.out.println("a".matches("[^abc]"));//false
System.out.println("d".matches("[^abc]"));//true
System.out.println("de".matches("[^abc]"));//false
System.out.println("de".matches("[^abc][^abc]"));//true
//a到z A到Z
System.out.println("----------3-----------");
System.out.println("A".matches("[a-zA-Z]"));//true
System.out.println("a".matches("[a-zA-Z]"));//true
System.out.println("0".matches("[a-zA-Z]"));//false
System.out.println("zz".matches("[a-zA-Z][a-zA-Z]"));//true
//a到d,或m到p
System.out.println("----------4-----------");
System.out.println("a".matches("[a-dm-p]"));//true
System.out.println("d".matches("[a-dm-p]"));//true
System.out.println("m".matches("[a-dm-p]"));//true
System.out.println("p".matches("[a-dm-p]"));//true
System.out.println("e".matches("[a-dm-p]"));//false
//a-z和def的交集 [a-z&&[def]]
System.out.println("----------5-----------");
System.out.println("a".matches("[a-z&&[def]]"));//false
System.out.println("d".matches("[a-z&&[def]]"));//true
System.out.println("z".matches("[a-z&&[def]]"));//false
//a-z与非bc的交集 [a-z&&[^bc]]== [ad-z]
System.out.println("----------6-----------");
System.out.println("a".matches("[a-z&&[^bc]]"));//true
System.out.println("b".matches("[a-z&&[^bc]]"));//false
System.out.println("z".matches("[a-z&&[^bc]]"));//true
//a-z和除了m到p的交集[a-z&&[^m-p]] == [a-lq-z]
System.out.println("----------7-----------");
System.out.println("a".matches("[a-z&&[^m-p]]"));//true
System.out.println("l".matches("[a-z&&[^m-p]]"));//true
System.out.println("m".matches("[a-z&&[^m-p]]"));//false
System.out.println("q".matches("[a-z&&[^m-p]]"));//true
}
}预定义字符(只匹配一个字符)
| . | 任何字符 |
|---|---|
| \d | 一个数字:[0-9] |
| \D | 非数字 :[^0-9 |
| \s | 一个空白字符:[\t\n\x0B\f\r] |
| \S | 非空白字符:[^\s] |
| \w | [a-zA-Z_0-9] 英文、数字、下划线 |
| \W | [^\w]一个非单词字符 |
数量词
| X? | X,一次或0次 |
|---|---|
| X* | X,0次或多次 |
| X+ | X,一次或多次 |
| X{n} | X,正好n次 |
| X{n,} | X,至少n次 |
| X{n,m} | X,至少n但不超过m次 |
public class RegexDemo3 {
public static void main(String[] args) {
// .表示任意一个字符
System.out.println("--------------1-------------");
System.out.println("你".matches(".."));//false
System.out.println("你".matches("."));//true
// \\d只能是任意一个数字
System.out.println("--------------2-------------");
System.out.println("a".matches("\\d"));//false
System.out.println("3".matches("\\d"));//true
System.out.println("aa".matches("\\d"));//false
// \\w只能是一位单词字符 [a-zA-Z_0-9]
System.out.println("--------------3-------------");
System.out.println("z".matches("\\w"));//true
System.out.println("2".matches("\\w"));//true
System.out.println("_".matches("\\w"));//true
System.out.println("你".matches("\\w"));//false
// 非单词字符
System.out.println("--------------4-------------");
System.out.println("你".matches("\\W"));//true
//多个字符
//必须是数字 字母 下划线 至少6位
System.out.println("2442_fsfsfs".matches("\\w{6,}"));//true
System.out.println("2442".matches("\\w{6,}"));//false
//必须是数字和字符 必须4位
System.out.println("23df".matches("[a-zA-Z0-9]{4}"));//true
System.out.println("23_f".matches("[a-zA-Z0-9]{4}"));//false
System.out.println("23dF".matches("[\\w&&[^_]]{4}"));//true
System.out.println("23_f".matches("[\\w&&[^_]]{4}"));//false
}
}注:
| 符号 | 含义 |
|---|---|
| [] | 里面的内容出现一次 |
| () | 分组 |
| ^ | 取反 |
| && | 交集 |
| I | 并集,写在方括号外 |
二、在一段文本中查找满足要求的内容
实现思路
- 定义目标文本:包含多个 Java 版本信息的字符串
- 创建正则表达式规则
- 获取正则表达式对象(Pattern):通过编译正则表达式得到
- 获取文本匹配器对象(Matcher):关联正则表达式和目标文本
- 循环查找匹配内容:
使用find()方法从文本中查找下一个符合规则的子串
使用group()方法获取当前找到的匹配内容
打印输出所有找到的匹配结果
public class RegexDemo1 {
public static void main(String[] args) {
/*
有如下文本,请按照要求爬取数据
Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,
因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不就Java17也会逐渐登上历史舞台。
要求:找出里面所以的JavaXX
*/
String str = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11," +
" 因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不就Java17也会逐渐登上历史舞台。";
//Pattern:表示正则表达式
//Matcher:文本匹配器,作用按照正则表达式的规则去读取字符串,从头开始读取 从大串中去找符合匹配规则的子串
//1.获取正则表达式对象
Pattern p = Pattern.compile("Java\\d{0,2}");
//2.获取文本匹配器对象
//拿着m去读取str,找符合p规则的子串
Matcher m = p.matcher(str);
//3.利用循环获取
while (m.find()){
String s = m.group();
System.out.println(s);
}
}
}
三、有条件爬取、贪婪爬取、非贪婪爬取
有条件爬取
public class RegexDemo1 {
public static void main(String[] args) {
//有条件爬取
/*
需求1:爬取版本号为8,11,17的Java文本,但是只要Java,不显示版本号
需求2:爬取版本号为8,11,17的Java文本,正确爬取结果为:Java8,Java11,Java17,Java17
需求3:爬取除了版本号为8,11,17的Java文本
*/
String str = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11," +
" 因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不就Java17也会逐渐登上历史舞台。";
//1.定义正则表达式
/*
? 理解为前面的数据Java
= 表示在Java后面要跟随的数据
但是在获取的时候只获取前半部分
*/
//需求1
String regex1 = "Java(?=8|11|17)";
//需求2
String regex2 = "Java(?:8|11|17)";
String regex3 = "Java(8|11|17)";
//需求3
String regex4 = "Java(?!8|11|17)";
Pattern p = Pattern.compile(regex1);
Matcher m = p.matcher(str);
while (m.find()){
System.out.println(m.group());
}
}
}贪婪、非贪婪爬取
public class RegexDemo2 {
public static void main(String[] args) {
//贪婪和非贪婪爬取
//+ * 为贪婪爬取 ,Java默认
//非贪婪爬取 +? *?
String str = "abbbbbbbbbbbbbbbbbbbbadad";
String regex = "ab+";//abbbbbbbbbbbbbbbbbbbb
String regex1 = "ab+?";//ab
Pattern p = Pattern.compile(regex1);
Matcher m = p.matcher(str);
while (m.find()){
System.out.println(m.group());
}
}
}四、方法补充
| 方法名 | 说明 |
|---|---|
| public String[] matches(String regex) | 判断字符串是否满足正则表达式的规则 |
| public String replaceAll(String regex,String newStr) | 按照正则表达式的规则进行替换 |
| public String[] split(String regex) | 按照正则表达式的规则切割字符串 |
public class RegexDemo3 {
public static void main(String[] args) {
/*
有一段字符串:小诗诗asdakdaskldasda小丹丹djaskdasd小慧慧
要求1:把字符串中三个姓名之间的字母替换为vs
要求2:把字符串中的三个姓名切割出来
*/
String str = "小诗诗asdakdasklda1sda2小丹丹djaskd23asd小慧慧";
String regex1 = "[\\w&&[^_]]+";
String newStr = str.replaceAll(regex1,"vs");
System.out.println(newStr);
String[] arr = str.split(regex1);
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
}
五、捕获分组与非捕获分组
捕获分组:
后续还要继续使用本组的数据
正则内部使用:\组号
正则外部使用:$组号
public class RegexDemo1 {
public static void main(String[] args) {
//捕获分组
/*
需求:
将字符串:我要学学编编编编程程程程程程
转换为:我要学编程
*/
String str = "我要学学编编编编程程程程程程";
/*
学学 -- 学
编编编编 -- 编
程程程程程程 -- 程
*/
/*
(.) 表示把重复内容的第一个字符看做一组
\\1 表示第一个字符再次出现
+ 至少一次
$1 表示把正则表达式中第一组的内容,再拿出来用
*/
String result = str.replaceAll("(.)\\1+","$1");
System.out.println(result);
}
}
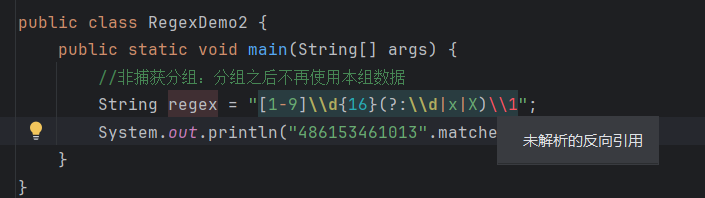
非捕获分组:
分组之后不需要再用本组数据,仅仅是把数据括起来
| 符号 | 含义 |
|---|---|
| (?: 正则) | 获取所有 |
| (?= 正则) | 获取前面部分 |
| (?! 正则) | 获取不是指定内容的前面部分 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号