


变革性的网络手艺-RDMA
我将深入技术细节,全面剖析RDMA这项对现代数据中心和AI基础设施至关重要的技巧。
一、 RDMA技术原理深度解析
RDMA的核心思想是彻底颠覆传统的网络通信模型,构建"数据直达内存"。
1. 传统网络通信的瓶颈:内核开销与数据拷贝
在传统的TCP/IP网络中,一次数据发送需要经历:
- 用户态到内核态拷贝:应用数据从用户空间缓冲区拷贝到内核的Socket缓冲区。
- 协议栈处理:内核进行TCP分段、IP封装,加入各层报头。
- 内核态到网卡拷贝:封装好的数据包被拷贝到网卡的发送缓冲区。
- 接收端反向操作:上述过程在接收端完全反向执行一次。
根本问题:
- 多次数据拷贝:消耗内存带宽和CPU周期。
- 上下文切换:用户态与内核态的频繁切换带来巨大CPU开销和高延迟。
- CPU参与度高:CPU忙于"搬运数据",而非执行核心计算任务。
2. RDMA的工作原理:内核旁路与零拷贝
RDMA凭借以下机制解决了上述瓶颈:
A. 核心运行模型
RDMA定义了三种基本操作,所有这些操作都绕过远程节点的CPU:
| 操作类型 | 功能描述 | 类比 |
|---|---|---|
| Send/Recv | 发送端发送消息,接收端需提前发布接收请求。 | 类似传统Socket,但零拷贝。 |
| Write | 发送端直接将数据写入远程节点的指定内存地址。 | 像直接向别人内存里"写"东西。 |
| Read | 发送端直接从远程节点的指定内存地址读取数据。 | 像直接从别人内存里"读"东西。 |
B. 关键抽象与核心组件
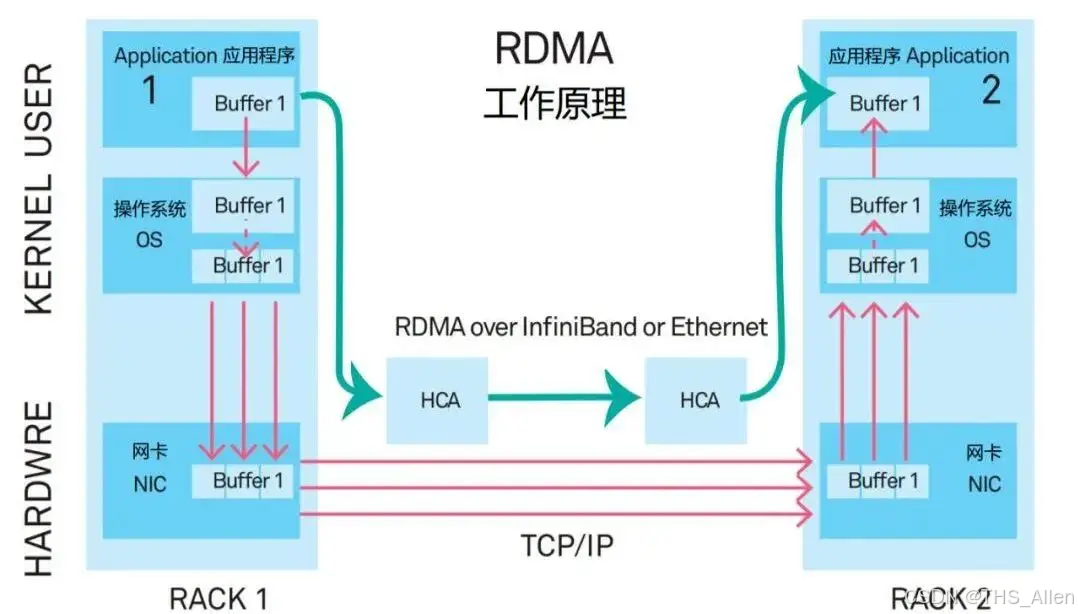
要理解RDMA如何工作,必须掌握其核心软件架构,下图清晰地展示了应用与RNIC交互的关键组件和数据流:
- 队列对:如图中
E部分所示,这是RDMA通信的核心抽象。每个QP由发送队列 和接收队列组成。应用将工作请求放入队列,RNIC异步处理。WR中包含了指向数据缓冲区的指针、大小、操作类型等。 - 内存区域:如图中
G部分所示,应用必须先将要用于RDMA通信的内存注册到RNIC。这个过程会:- 锁定物理内存页(防止被换出)。
- 将虚拟地址与物理地址映射关系告知RNIC。
- 返回一个远程密钥,作为远程节点访问此块内存的"钥匙"。
- 完成队列:如图中
D部分所示,当RNIC处理完一个WR后,会在CQ中放置一个完成条目。应用通过轮询CQ来确认操作是否完成,这是RDMA低延迟的关键之一。
C. 通信建立流程
- 本地准备:双方应用各自注册MR,创建QP、CQ等资源。
- 资源交换:通过一个带外通道,双方交换连接信息,包括:
- GID:全局标识。
- QP号。
- MR的虚拟地址和rkey。
- 状态迁移:将QP状态机迁移到Ready to Send状态。
- RDMA通信:应用将WR放入QP,RNIC直接与远程内存进行数据传输,双方CPU不再参与。
二、 RDMA的三种完成方式与技巧对比
RDMA是一个规范,有三种主流搭建:
| 特性 | InfiniBand | RoCEv2 | iWARP |
|---|---|---|---|
| 物理网络 | 专属网络(交换机、线缆、HCA) | 标准以太网 | 标准以太网 |
| 传输层 | 原生IB传输层 | UDP/IP | TCP/IP |
| 协议封装 | 原生 | IB传输头 + UDP + IP | iWARP头 + TCP + IP |
| 优势 | 性能最高、延迟最低、工艺最成熟 | 在无损以太网上达到近IB性能、部署灵活 | 可在广域网路由、对网络要求较低 |
| 劣势 | 需要独立的物理网络,成本高 | 对网络丢包极度敏感 | TCP协议栈稍复杂,延迟和CPU开销高于RoCE |
| 适用场景 | 超算中心、极致性能的AI集群 | 现代云数据中心、AI训练、存储 | 跨数据中心的存储同步 |
结论:RoCEv2是目前在通用以太网数据中心中实现RDMA的主流和最佳选择,在性能、成本和部署便利性上取得了最佳平衡。
三、 RDMA的核心应用场景
RDMA的价值在以下场景中无可替代:
分布式AI训练(核心驱动力)
- 场景:千亿参数大模型训练,数千GPU卡需频繁同步梯度(All-Reduce操作)。
- 价值:
- 极低延迟:将GPU间通信延迟从毫秒级降至微秒级,大幅缩短训练时间。
- 高带宽:充分利用100/200/400Gbps网络带宽。
- 解放CPU:CPU专注于任务调度和数据处理,而非网络通信。
高性能存储
- 场景:NVMe-of协议,实现存储与计算分离。
- 价值:NVMe-of over RoCE是事实标准。它让应用凭借网络访问远程NVMe SSD时,获得接近本地SSD的延迟和带宽,是构建云原生存储、超融合基础设施的基石。
高性能计算
- 场景:科学计算(如气象模拟、基因测序)中节点间的紧密通信。
- 价值:MPI等并行计算框架通过RDMA获得极高的通信效率,加速整体计算任务。
金融交易系统
- 场景:高频交易。
- 价值:微秒级的延迟优势直接转化为交易竞争力。
四、 注意事项与最佳实践:实战中的"雷区"与对策
RDMA十分强大,但也非常"娇贵"。错误配置会导致性能灾难。
无损网络是RoCEv2的生命线
- 问题:RoCEv2基于无损传输模型,对丢包零容忍。极低的丢包率(如0.01%)就可能导致吞吐量下降超过50%。
- 解决方案:
- 启用PFC:在交换机端口上为RoCE流量(通常优先级3或4)启用PFC。当缓冲区达到阈值时,向发送端发送暂停帧,实现"零丢包"。
- 启用ECN:与PFC协同工作,进行端到端的拥塞控制,避免PFC的"暂停帧风暴"。
- DCQCN:在大型网络中,使用像DCQCN这样的增强拥塞控制算法,能更精细地管理网络拥塞。
内存管理的复杂性与开销
- 问题:内存注册和注销是重量级操作,耗时较多。注册过多内存会消耗大量系统资源。
- 解决方案:
- 内存池:在应用初始化时,注册一大块内存池,在应用生命周期内重复使用。
- 准注册:使用像
mlx5dv_reg_mr这样的高级函数,可以显著提升注册速度。
编程复杂性与生态
- 问题:RDMA编程模型(Verbs API)比Socket编程复杂得多,需要深入理解其架构。
- 解决方案:
- 使用高层库:除非你是底层开发者,否则应使用基于RDMA封装的高层库,如:
- NCCL:用于GPU间的集体通信。
- Libfabric:一个通用的底层通信API。
- 存储SDK:如各大厂商供应的NVMe-of Target/Initiator库。
- 使用高层库:除非你是底层开发者,否则应使用基于RDMA封装的高层库,如:
网络隔离与QoS
- 问题:大规模的TCP/IP流量(如数据备份)会冲击RDMA的微突发流量。
- 解决方案:
- 流量隔离:为RDMA流量划分独立的VLAN或使用不同的IP网段。
- 严格的QoS策略:在交换机上确保RDMA流量拥有最高优先级,并限制其他流量对高优先级队列的使用。
监控与排障
- 关键指标:
- 交换机:PFC暂停帧计数、ECN标记计数、端口错误计数。
- 主机:
ethtool -S <interface>查看丢包和错误统计;perfquery命令查询RNIC的计数器。
- 工具:利用厂商提供的工具(如NVIDIA的
show_gids,perfquery)和标准Linux工具进行深度诊断。
- 关键指标:
总结
RDMA是一项变革性的网络技术,它依据内核旁路和零拷贝机制,实现了微秒级延迟和极低的CPU开销,是支撑现代AI基础设施、高性能存储和计算的关键基石。
其核心价值在于极致性能,但代价是极高的部署和运维复杂度。成功运用RDMA,需要网络团队、环境团队和应用开发者的紧密协作,以及对无损网络、内存管理和底层API的深刻理解。对于追求极致效率的数据中心而言,掌握RDMA是一项不可或缺的核心竞争力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号