


深入解析:PyTorch张量切片的陷阱:视图与副本
问题导入:
在使用PyTorch框架开发中,你是否也也遇到过这样的问题,就是明明获取了张量的切片,却发现修改了原张量后,切片的结果也跟着变!
我今天训练一个一个做下游mask完形填空任务的语言模型,
在书写整理函数是,我是这样写的:
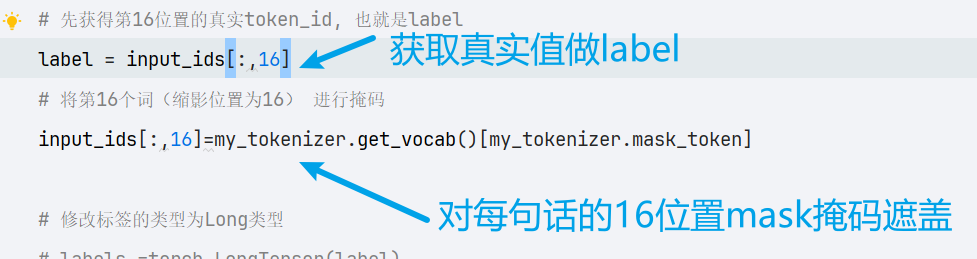
然后正常训练模型
过程中发现我的训练指标一下就变得非常好看

损失值下降非常快,正确率可以用飙升来形容。
我觉得不可思议,所以决定把训练好的模型,去加载出来做测试
可是测试结果就是:
无论我预测什么句子,结果都是:
[MASK]
可问题出在哪里呢? 我检查了几遍代码,确定逻辑没有问题的,那为题出在哪??
没错!就是前面在获取正式标签时,没有做拷贝,只是用了切片。
一起看看看

使得模型训练时,只要将第16位置的值预测为[MASK]就可以将损失值降到最低,从而得到虚高的
训练指标,但是本质模型值学会了,预测为[MASK] ,任何句子都是将16位置预测为[MASK]
原因解析
这里我先写一段测试代码
import torch
arr =[
[1,2,3,4,5],
[4,5,6,7,8]
]
arr = torch.tensor(arr)
result = arr[:,3]
print(result) # tensor([4,7])
arr[:,3]=8
print(result) # tensor([8,8])这里可以发现,改变原始张量,通过切片获取的值也发生了改变、
但是这时候,可能很多朋友们回想为什么?
直觉告诉我们result应该保存修改前的值[4,7],但实际输出却是修改后的值[8,8]。这与 Python 列表的行为截然不同:
在看看列表
# Python列表的行为
arr = [
[1,2,3,4,5],
[4,5,6,7,8]
]
result = [row[3] for row in arr] # 列表推导式获取第3列
for row in arr:
row[3] = 8
print(result) # 输出:[4, 7](保持原始值)为什么会有这种差异?
答案就藏在 "视图" 与 "副本" 的区别中。
核心原理:视图(View)不是副本(Copy)
PyTorch 中,张量的切片操作返回的是视图(view) 而非副本(copy):
视图:只是原张量数据的一个引用,不占用额外内存,与原张量共享同一块数据存储空间
副本:是原数据的完整复制,占用独立的内存空间,与原张量互不影响
这种设计是为了提高计算效率 —— 在处理大型张量时,频繁复制数据会导致内存浪费和性能下降。PyTorch 默认采用视图方式,避免了不必要的数据复制。
在我们的例子中:
result = arr[:,3]创建了一个视图,指向arr第 3 列的内存地址arr[:,3] = 8修改了这块内存中的值- 因此
result也会显示修改后的值
如何解决
获取真正的副本如果需要获取不受原张量影响的独立切片,可使用.clone()方法显式创建副本:
import torch
arr = torch.tensor([
[1,2,3,4,5],
[4,5,6,7,8]
])
result = arr[:,3].clone() # 创建副本而非视图
arr[:,3] = 8
print(result) # 输出:tensor([4, 7])(保持原始值).clone()会创建一个全新的张量,拥有独立的内存空间,后续对原张量的修改不会影响副本。
所以之前我的获取label值的代码应该改为:

总结:
哪些操作返回视图,哪些返回副本?
PyTorch 中常见的返回视图的操作:
- 基本切片操作(如
arr[:, 3]、arr[1:3, :]) .view()方法(重塑张量形状).transpose()和.permute()(维度转换)
返回副本的操作:
.clone()(显式复制).detach()(在计算图中分离并复制)- 某些高级索引操作(如使用列表索引
arr[[0,2], :])
注意:注意:高级索引(如arr[[0,1], [2,3]])通常返回副本,但具体行为可能因情况而异,建议通过.clone()确保获得副本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号