数据结构
数据结构
程序
程序计数器决定着程序的流程。
CPU每执行一个指令,程序计数器的值就会自动加1。
程序的流程分为顺序执行、条件分支和循环三种
- 顺序执行是指按照地址内容的顺序执行指令。
- 条件分支是指根据条件执行任意地址的指令。
- 循环是指重复执行同一地址的指令。
-
顺序执行的情况比较简单,每执行一个指令程序计数器的值就自动加1。
-
但若程序中存在条件分支和循环,机器语言的指令就可以将程序计数器的值设定为任意地址(不是+1)。这样一来,程序便可以返回到上一个地址来重复执行同一个指令,或者跳转到任意地址。
-
条件分支和循环中使用的跳转指令,会参照当前执行的运算结果来判断是否跳转。
函数的调用机制
函数调用处理也是通过把程序计数器的值设定成函数的存储地址来实现的。不过,这和条件分支、循环的机制有所不同,因为单纯的跳转指令无法实现函数的调用。
函数的调用需要在完成函数内部的处理后,处理流程再返回到函数调用点(函数调用指令的下一个地址)。
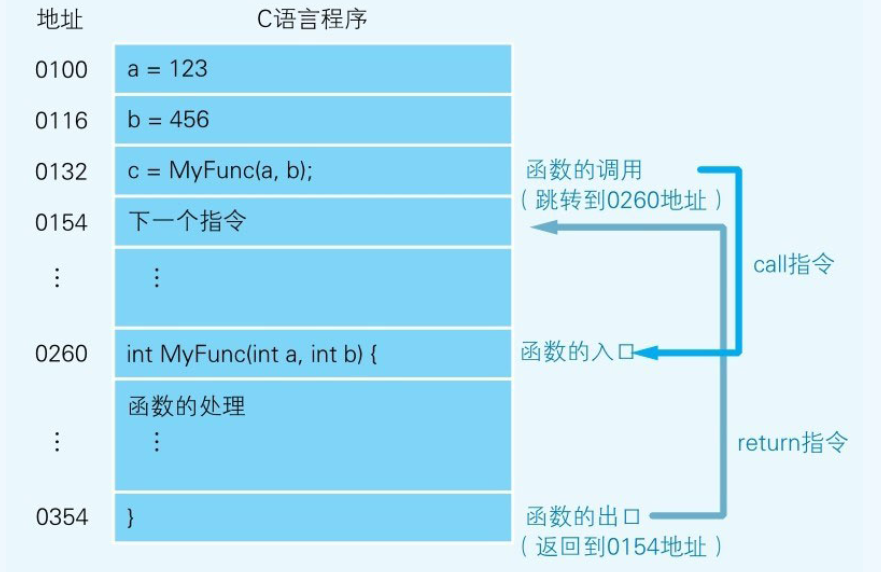
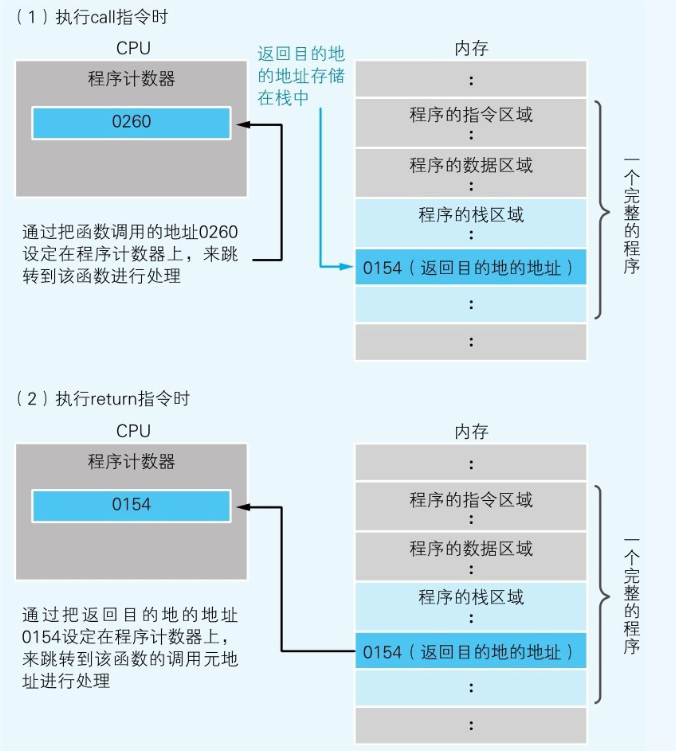
函数调用使用的是call指令,而不是跳转指令。在将函数的入口地址设定到程序计数器之前,call指令会把调用函数后要执行的指令地址存储在名为栈的主存内。函数处理完毕后,再通过函数的出口来执行return命令。return命令的功能是把保存在栈中的地址设定到程序计数器中。
数组数据结构的基础
栈和队列
栈和队列,都可以不通过指定地址和索引来对数组的元素进行读写。
需要临时保存计算过程中的数据、连接在计算机上的设备或者输入输出的数据时,都可以通过这些方法来使用内存。
当我们需要暂时舍弃当前的数据,随后再原貌还原时,会使用栈。
排队指的是买车票时在自动售票机前等候的队列等。排队时,站在最前面的乘客先买票,购买后率先从队列中走出来。当随机前来的购票乘客数量和自动售票机的处理速度不相符时,排队能起到很好的缓冲作用。程序中也是如此,为了协调好数据输入和处理时机间的关系,采用类似于排队的机制是很方便的。
当我们需要处理通讯中发送的数据时,或由同时运行的多个程序所发送过来的数据时,会用到这种对队列中存储的不规则数据进行处理的方法。
队列一般是以环状缓冲区(ring buffer)的方式来实现的,从数组的起始位置开始有序地存储数据,然后再按照存储时的顺序把数据读出。在数组的末尾写入数据后,后一个数据就会被写入数组的起始位置(此时数据已经被读出所以该位置是空的),数组的末尾就和开头连接了起来,数据的写入和读出也就循环起来了
链表使元素的追加和删除更容易
数据的值和下一个元素的索引组合在一起,就构成了数组的一个元素。
数组的各个元素中,除了数据的值之外,通过为其附带上下一个元素的索引,即可实现链表。
在需要追加或删除数据的情况下,使用链表是很高效的。
二叉查找树使数据搜索更有效
二叉查找树是指在链表的基础上往数组中追加元素时,考虑到数据的大小关系,将其分成左右两个方向的表现形式。
假设我们事先把50这个值保存到了数组中。那么,如果接下来的值比先前保存的数值大的话,就要将其放到右边,反之如果小的话就放在左边。但实际的内存并不会分成两个方向,这是在程序逻辑上实现的。
二叉查找树的实现,数组的每个元素中只要有数据的值和两个索引信息就可以了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号