

Python 爬虫 - Scrapy框架原理
Python 爬虫包含两个重要的部分:正则表达式和Scrapy框架的运用, 正则表达式对于所有语言都是通用的,网络上可以找到各种资源。
如下是手绘Scrapy框架原理图,帮助理解
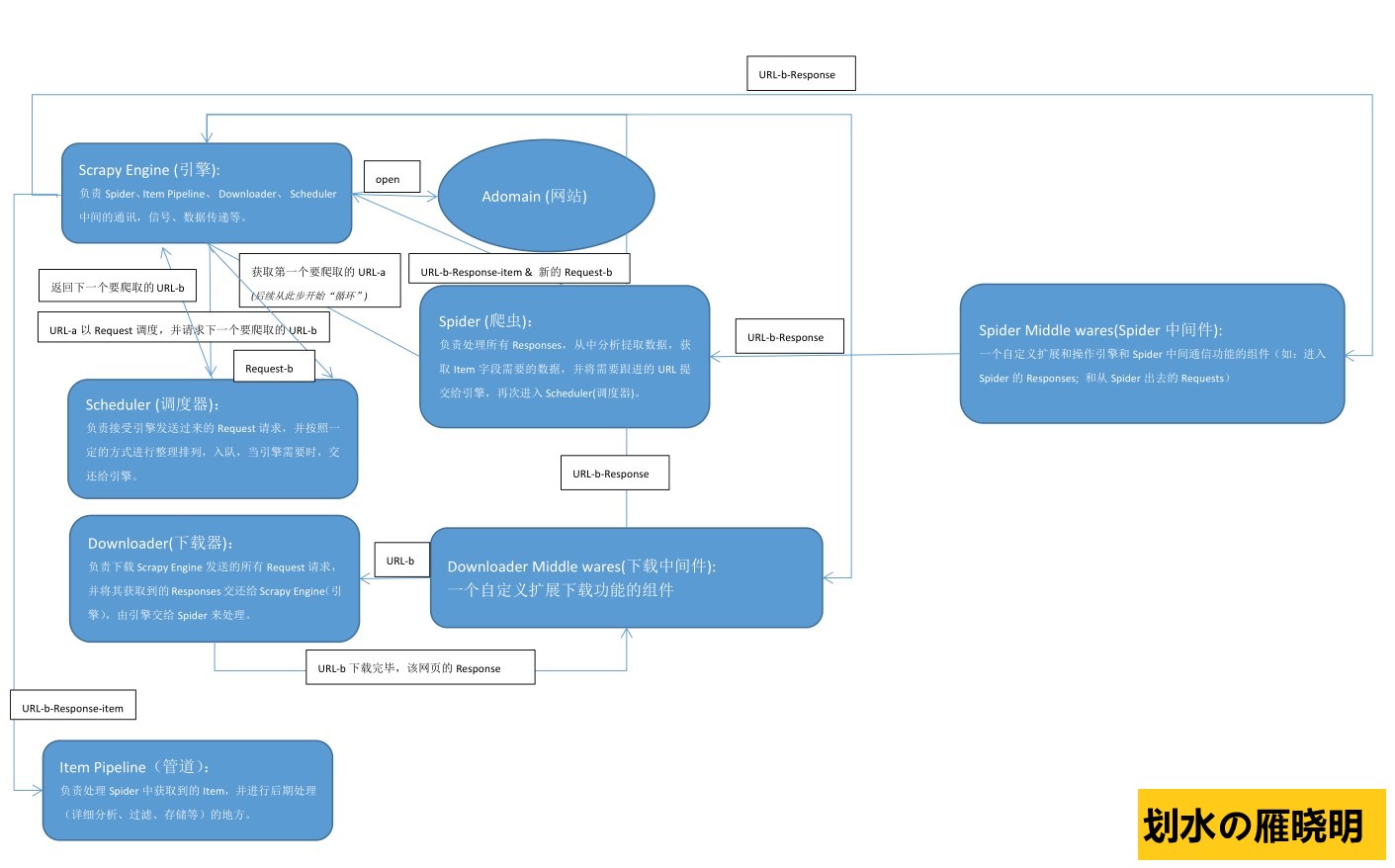
如下是一段运用Scrapy创建的spider:使用了内置的crawl模板,以利用Scrapy库的CrawlSpider。相对于简单的爬取爬虫来说,Scrapy的CrawlSpider拥有一些网络爬取时可用的特殊属性和方法:
$ scrapy genspider country_or_district example.python-scrapying.com--template=crawl
运行genspider命令后,下面的代码将会在example/spiders/country_or_district.py中自动生成。


1 # -*- coding: utf-8 -*-
2 import scrapy
3 from scrapy.linkextractors import LinkExtractor
4 from scrapy.spiders import CrawlSpider, Rule
5 from example.items import CountryOrDistrictItem
6
7
8 class CountryOrDistrictSpider(CrawlSpider):
9 name = 'country_or_district'
10 allowed_domains = ['example.python-scraping.com']
11 start_urls = ['http://example.python-scraping.com/']
12
13 rules = (
14 Rule(LinkExtractor(allow=r'/index/', deny=r'/user/'),
15 follow=True),
16 Rule(LinkExtractor(allow=r'/view/', deny=r'/user/'),
17 callback='parse_item'),
18 )
19
20 def parse_item(self, response):
21 item = CountryOrDistrictItem()
22 name_css = 'tr#places_country_or_district__row td.w2p_fw::text'
23 item['name'] = response.css(name_css).extract()
24 pop_xpath = '//tr[@id="places_population__row"]/td[@class="w2p_fw"]/text()'
25 item['population'] = response.xpath(pop_xpath).extract()
26 return item
爬虫类包括的属性:
- name: 识别爬虫的字符串。
- allowed_domains: 可以爬取的域名列表。如果没有设置该属性,则表示可以爬取任何域名。
- start_urls: 爬虫起始URL列表。
- rules: 该属性为一个通过正则表达式定义的Rule对象元组,用于告知爬虫需要跟踪哪些链接以及哪些链接包含抓取的有用内容。
参考:
1. 正则表达式:《Python 爬虫 - 正则表达式》
2. 其他Python爬虫实践:
-
- 视频代码如下:
# 获取页面所有热点
import urllib.request
import json
from csv import DictWriter
import requests
import pandas as pd
#编辑循环:
docs = list()
for i in range(0,200):
template_url = 'https://准备浏览的地址'%(i)
req = urllib.request.Request(template_url)
#获取URL
NewsHtml= urllib.request.urlopen(template_url)
NewsJSON = json.loads(NewsHtml.read())
if len(NewsJSON["data"]['list']) != 0:
#print(template_url)
doc = NewsJSON["data"]['list']
docs.append(doc)
else:
print ("END")
break # 跳出当前循环
#写入本地
#列表
新闻名称 = list()
for i in range(0,len(docs)):
for a in range(0,len(docs[i])):
title = docs[i][a]['title']
新闻名称.append(title)
#表格
df = pd.DataFrame(columns = ["新闻名称"])
df['新闻名称'] = 新闻名称
#写入
df.to_csv('~/data/news2021Today.csv')
记录有用的信息和数据,并分享!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号