
Flink集群基础知识
Flink集群架构分析
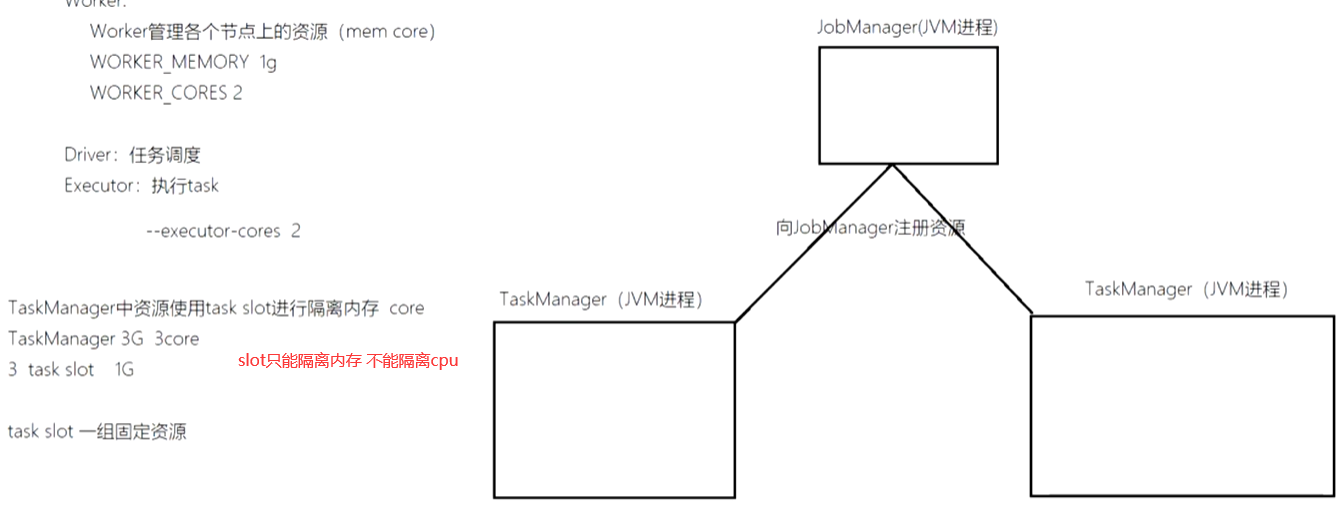
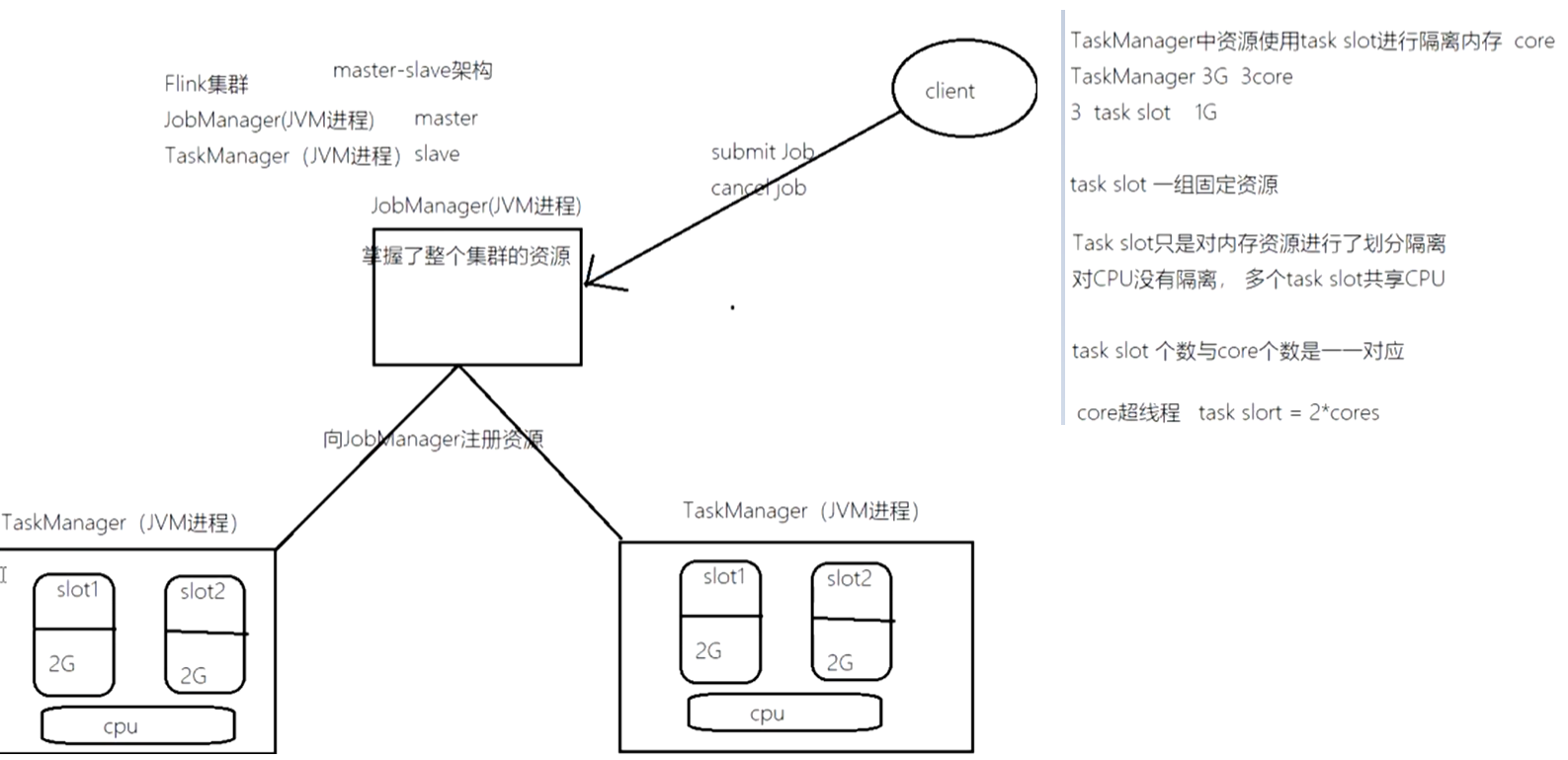
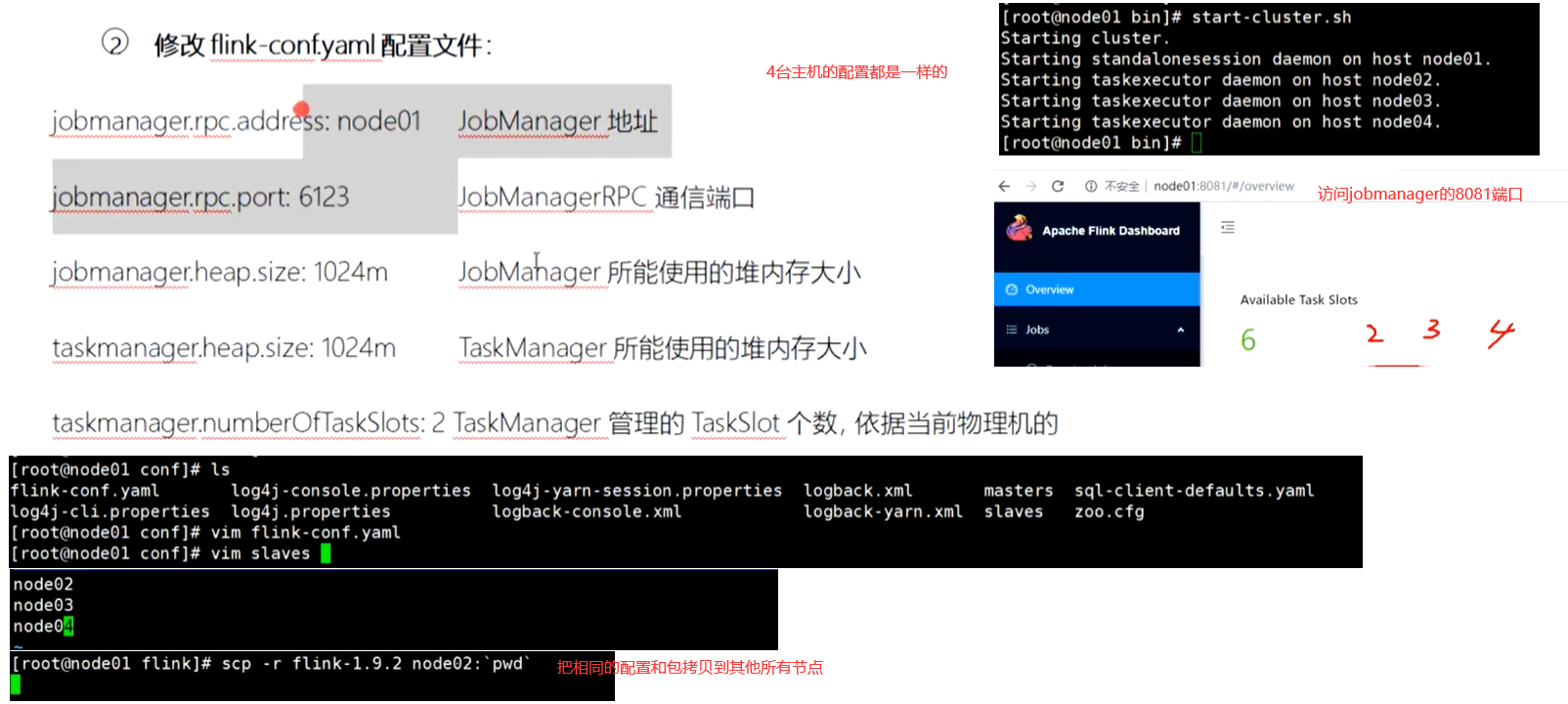
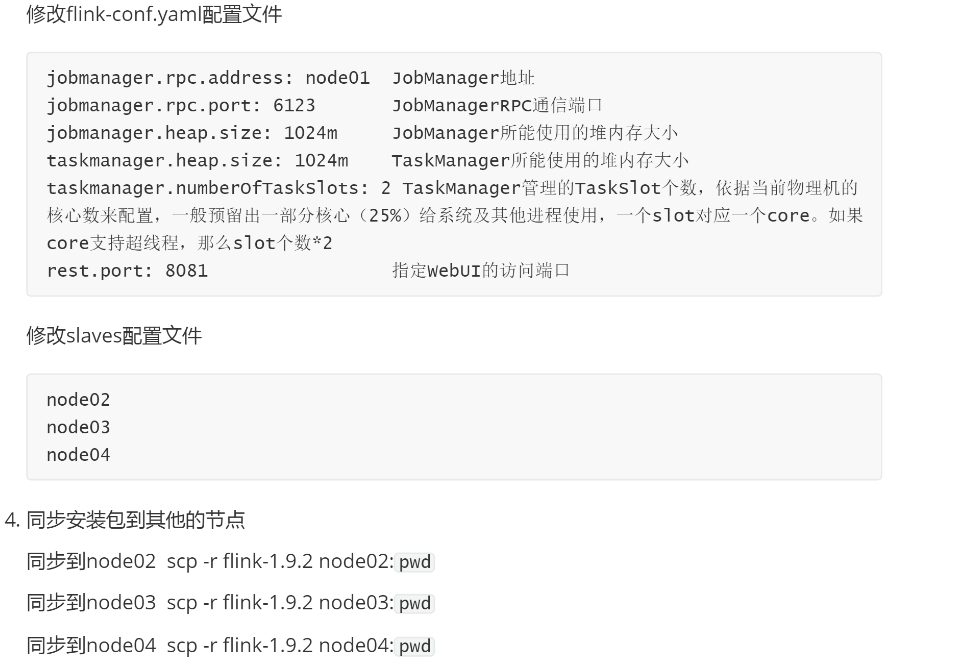
Flink独立部署模式

Flink HA部署模式


Flink on Yarn部署

Flink TaskManager自动宕机

flink taskmanager进程shutdown的日志,从日志里能够看到,进程shutdown的缘由是在中止job的时候该taskmanager上运行的某个task180多秒都没有响应中止指令,所以taskmanager本身把本身杀死了
在编写可能会阻塞的flink算子时,应该考虑job被cancle时的线程中断问题.例如,使用带超时的api,超时后线程能够返回并检查是否中断,若是中断了就跳出阻塞等待,使得task执行线程有机会处理cancle,避免taskmanager杀死本身
在standalone cluster模式下taskmanager杀死后,jobmanager是没法启动它的,这会致使其余job被重启,集群slot变少也可能会致使job没法启动.相比之下,flink on yarn会好一点,而且single-job模式至关于每一个job都有一个集群,job间隔离比较好,job中止的时候taskmanager和jobmanager的进程都退出了.而standalone cluster模式进程是没有中止的,也就是说job若是开启了线程,在standalone cluster模式下必定要在job中止的时候终止这些线程,不然,线程不会随job中止而中止,他会一直存在,因为线程栈是gc root,线程引用的内存资源也没法释放,形成泄漏
本文来自博客园,作者:不懂123,转载请注明原文链接:https://www.cnblogs.com/yxh168/p/15310889.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号