

cpca库实战应用
问题场景:
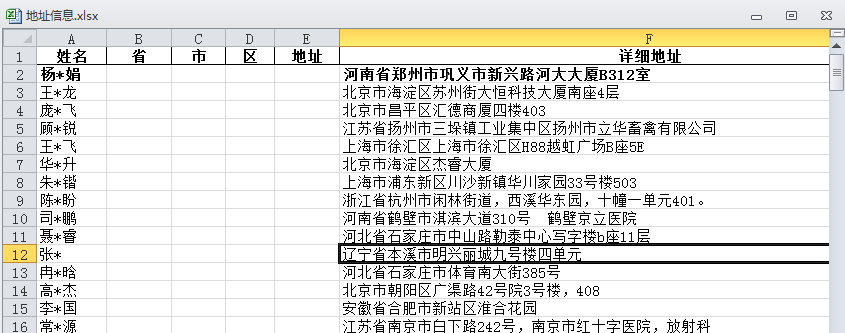
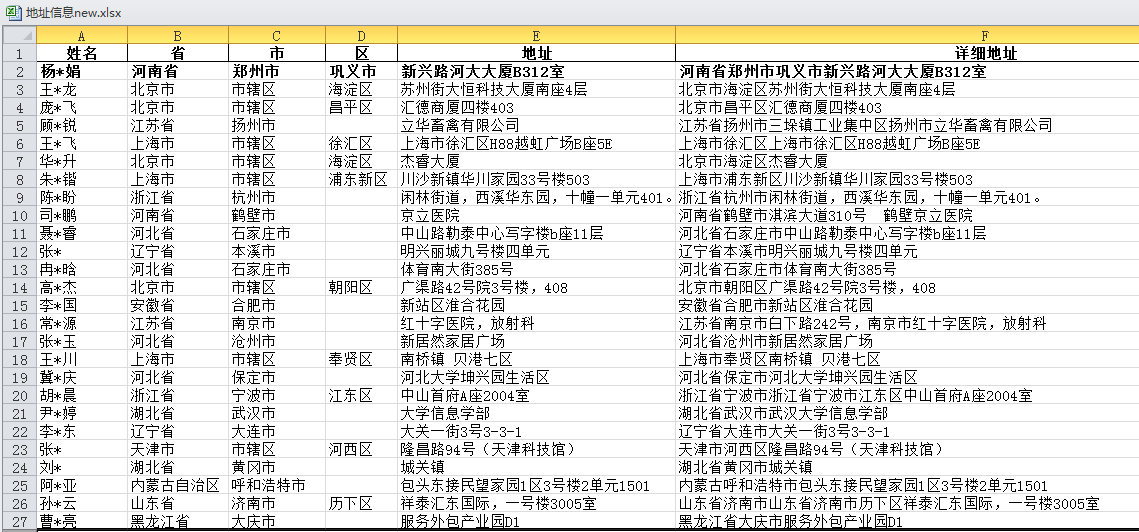
领导给了一个excel表格,里面有公司几百号员工的资料(如图),要根据详细地址分别统计出来,每个员工所属的省、市、区和具体地址,根据这个地址给每位员家属寄送一份中秋节礼品,表达公司心意,整理后的表格如下图:
整理前:

整理后:
解决思路:
1.在原表格中插入列:省、市、区、地址
2.按照excel表格 用for 循环遍历每一行
3.利用三方库cpca提取出来 省、市、区、地址
4.把省、市、区、地址 写入到excel表格对应的位置
5.保存输入表格
代码:
from openpyxl import load_workbook wb=load_workbook('地址信息.xlsx') ws=wb.active for row in range(2,ws.max_row+1): cell=ws.cell(row=row,column=6) localtion_str=[cell.value] df = cpca.transform(localtion_str) ws.cell(row=row,column=2).value=df.iat[0,0] ws.cell(row=row,column=3).value=df.iat[0,1] ws.cell(row=row,column=4).value=df.iat[0,2] ws.cell(row=row,column=5).value=df.iat[0,3] wb.save('地址信息new.xlsx')
看看新生成的表格:大功告成!cpca库很给力!
知识点:
cpca.transform(location_strs, index=None, pos_sensitive=False, umap={})
将地址描述字符串转换以"省","市","区"信息为列的DataFrame表格
Args:
locations:地址描述字符集合,可以是list, Series等任意可以进行for in循环的集合
比如:["徐汇区虹漕路461号58号楼5楼", "泉州市洛江区万安塘西工业区"]
index:可以通过这个参数指定输出的DataFrame的index,默认情况下是range(len(data))
pos_sensitive:如果为True则会多返回三列,分别提取出的省市区在字符串中的位置,如果字符串中不存在的话则显示-1
umap: 当只有区的信息时, 且该区存在同名时, 指定该区具体是哪一个,字典的 key 为区名,value 为 adcode, 比如 {"朝阳区": "110105"}
Returns:
一个Pandas的DataFrame类型的表格,如下:
|省 |市 |区 |地址 |adcode |
|上海市|市辖区|徐汇区|虹漕路461号58号楼5楼 |310104 |
|福建省|泉州市|洛江区|万安塘西工业区 |350504 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号