前三次作业总结
一、 前言
前三次的作业都是关于设计一个答题程序,进行题目的迭代。三次题目的知识点主要包括正则表达式,类的设计以及类间关系等。题量不大,一次只有一道,除第一道题外题目相较困难,需要花费大量时间进行设计与测试。
二、作业过程总结
1. 作业考察的主要知识,及作业间的迭代
第一次作业主要对Java的类的设计、函数调用、正则表达式、if else语句、循环结构for循环、whille循环以及数据、数组进行了考察。整体难度不算大。
第二次作业在第一次作业的基础上加上了试卷类与答卷类,需要按相应的试卷号、题号进行输出。主要对类的设计、类间关系的设计、对象、数据处理、函数方法的调用,以及第一题已考查过的内容进行了考察。
第三次作业作业在第二次的基础上增加了许多内容,除了类的增加,还有对于不同情况不同地输出,内容变得更加复杂。主要对类的设计、函数的调用、对象传值与调用、正则表达式、数据处理等进行了考察。
2. 从面向过程到面向对象
面向对象设计基本原则:
每个对象都有自己专属的属性,先有类后有对象,每个对象都有自己专属的方法,外部对象若要调用方法,可以通过对象调用或直接调用静态方法,类可继承,对象的内容也可继承。
从C语言的学习到Java的学习,这不仅是从C的语言体系到Java的语言体系的转变,更重要的还是从面向过程思想到面向对象思想的转变,即床建类,运用类,定义对象,使用对象。
3.遵循Java的七大基本原则
Java的七大设计原则是:
A.单一职责原则(Single Responsibility Principle, SRP)。一个类应该只有一个引起变化的原因,即一个类应该只负责一个职责。
B.开闭原则(Open/Closed Principle)。软件实体(如类、模块等)应对扩展开放,对修改关闭,即在不修改已有代码的情况下,可以添加新功能。
C.里氏替换原则(Liskov Substitution Principle, LSP)。在继承体系中,父类的对象可以被其子类的对象替换,而不会影响程序的正确性。
D.接口隔离原则(Interface Segregation Principle, ISP)。客户端不应该依赖它们不需要的接口,即一个类对另一个类的依赖应该建立在最小的接口上。
E.迪米特原则(Demeter Principle)。一个对象应尽可能地少了解其他对象,以降低耦合和提高系统的可维护性。
F.依赖倒转原则(Dependence Inversion Principle, DIP)。高层模块不应依赖于低层模块,两者都应依赖于抽象;抽象不应依赖于细节,细节应依赖于抽象。
G.组合/聚合复用原则(Composite Reuse Principle, CRP)。优先使用组合和聚合关系来实现代码复用,而不是使用继承。
三、设计与分析
1.答题判题程序-1(第一次作业)
题目内容:
设计实现答题程序,模拟一个小型的测试,要求输入题目信息和答题信息,根据输入题目信息中的标准答案判断答题的结果。
输入格式:
程序输入信息分三部分:
1、题目数量
格式:整数数值,若超过1位最高位不能为0,
样例:34
2、题目内容
一行为一道题,可以输入多行数据。
格式:"#N:"+题号+" "+"#Q:"+题目内容+" "#A:"+标准答案
格式约束:题目的输入顺序与题号不相关,不一定按题号顺序从小到大输入。
样例:#N:1 #Q:1+1= #A:2
#N:2 #Q:2+2= #A:4
3、答题信息
答题信息按行输入,每一行为一组答案,每组答案包含第2部分所有题目的解题答案,答案的顺序号与题目题号相对应。
格式:"#A:"+答案内容
格式约束:答案数量与第2部分题目的数量相同,答案之间以英文空格分隔。
样例:#A:2 #A:78
2是题号为1的题目的答案 78是题号为2的题目的答案答题信息以一行"end"标记结束,"end"之后的信息忽略。
输出格式:
1、题目数量
格式:整数数值,若超过1位最高位不能为0,
样例:34
2、答题信息
一行为一道题的答题信息,根据题目的数量输出多行数据。
格式:题目内容+" ~"+答案
样例:1+1=~2
2+2= ~4
3、判题信息
判题信息为一行数据,一条答题记录每个答案的判断结果,答案的先后顺序与题目题号相对应。
格式:判题结果+" "+判题结果
格式约束:
1、判题结果输出只能是true或者false, 2、判题信息的顺序与输入答题信息中的顺序相同样例:true false true
输出格式:
1、题目数量
格式:整数数值,若超过1位最高位不能为0,
样例:34
2、答题信息
一行为一道题的答题信息,根据题目的数量输出多行数据。
格式:题目内容+" ~"+答案
样例:1+1=~2
2+2= ~4
3、判题信息
判题信息为一行数据,一条答题记录每个答案的判断结果,答案的先后顺序与题目题号相对应。
格式:判题结果+" "+判题结果
格式约束:
1、判题结果输出只能是true或者false, 2、判题信息的顺序与输入答题信息中的顺序相同样例:true false true
输入样例1:
单个题目。例如:
1
N:1 #Q:1+1= #A:2
A:2
end
输出样例1:
在这里给出相应的输出。例如:
1+1=~2
true
输入样例2:
单个题目。例如:
1
N:1 #Q:1+1= #A:2
A:4
end
输出样例2:
在这里给出相应的输出。例如:
1+1=~4
false
输入样例3:
多个题目。例如:
2
N:1 #Q:1+1= #A:2
N:2 #Q:2+2= #A:4
A:2 #A:4
end
输出样例3:
在这里给出相应的输出。例如:
1+1=~2
2+2=~4
true true
输入样例4:
多个题目。例如:
2
N:1 #Q:1+1= #A:2
N:2 #Q:2+2= #A:4
A:2 #A:2
end
输出样例4:
在这里给出相应的输出。例如:
1+1=~2
2+2=~2
true false
输入样例5:
多个题目,题号顺序与输入顺序不同。例如:
2
N:2 #Q:1+1= #A:2
N:1 #Q:5+5= #A:10
A:10 #A:2
end
输出样例5:
在这里给出相应的输出。例如:
5+5=~10
1+1=~2
true true
输入样例6:
含多余的空格符。例如:
1
N:1 #Q: The starting point of the Long March is #A:ruijin
A:ruijin
end
输出样例6:
在这里给出相应的输出。例如:
The starting point of the Long March is~ruijin
true
输入样例7:
含多余的空格符。例如:
1
N: 1 #Q: 5 +5= #A:10
A:10
end
输出样例7:
在这里给出相应的输出。例如:
5 +5=~10
true
第一道题由于刚接触,显得有些无从下手。还未从C语言的思维中脱离,习惯性地一个类走天下,因此做题目时没有考虑要进行类的设计,整串代码从始至终只有一个主类,一个主函数,代码看起来十分混乱,这使得在进行代码的测试时,经常弄混数据,为代码的编写带来了一定的阻碍。
主函数中主要分为三个部分,一是数据的输入,二是数据的处理,三是结果的输出。
-
[UML图 ]
UML图如下:
-
[SourceMontor的生成报表 ]
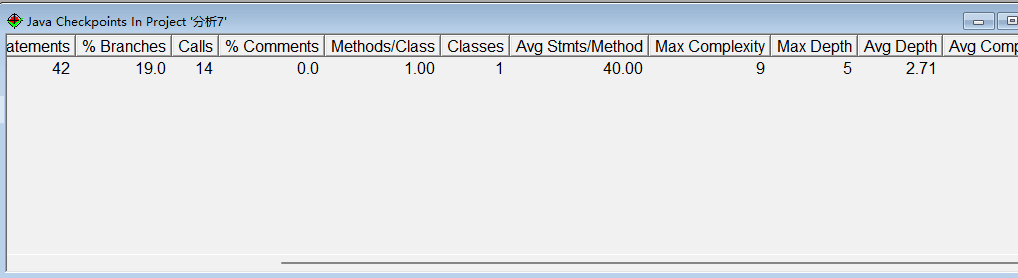
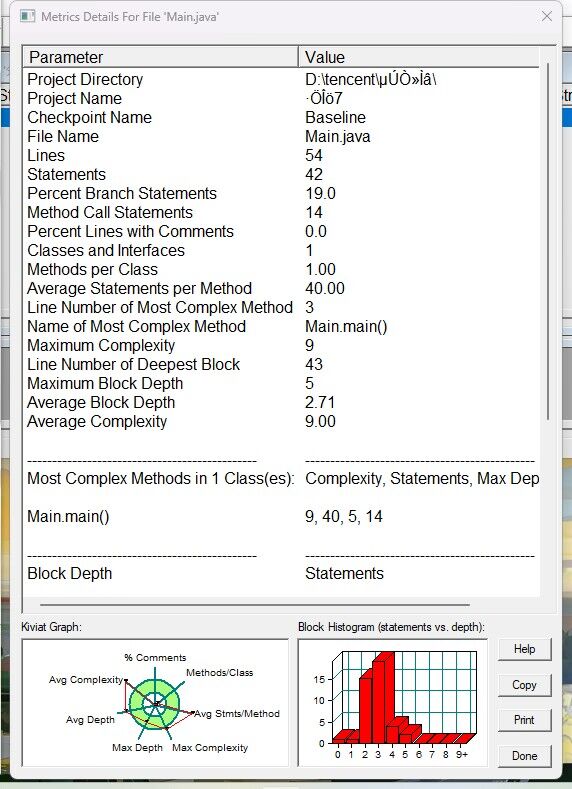
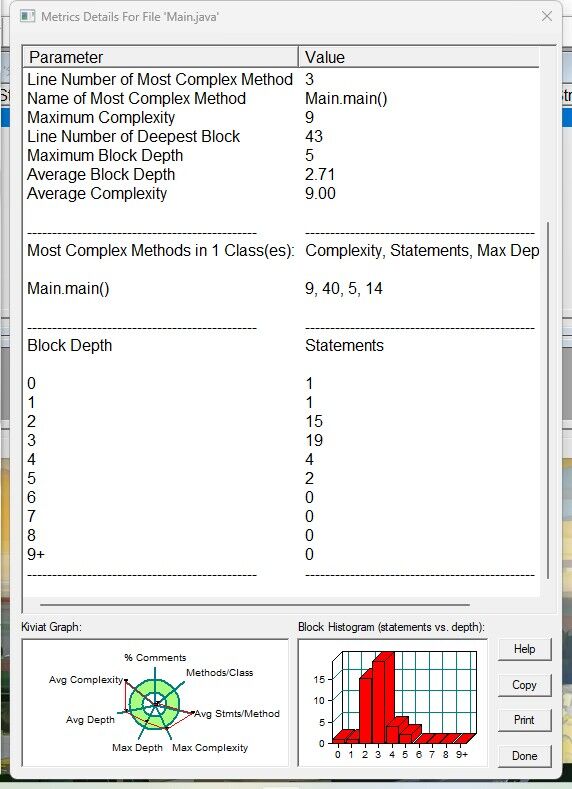
-
[数据的输入 ]
使用while循环输入字符串,并使用str_list.add()函数将字符组成一个List型。
如下图:
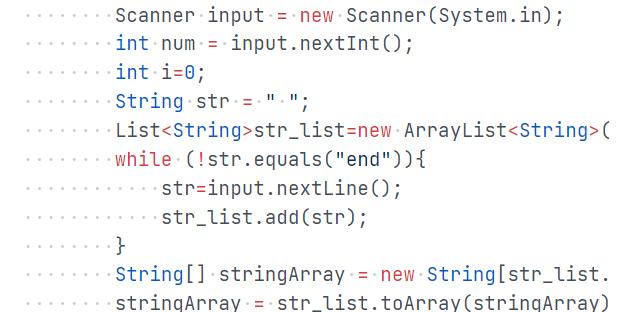
-
[数据的处理 ]
对List使用toArray()函数转化为字符串数组(现在想来多此一举),在编写的过程中,因为不熟悉正则表达式,多次尝试无果后选择了split函数对字符串进行处理切割,将各个部分放入不同的不同的字符串数组中。
如下图:
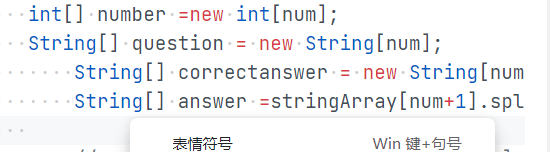
-
[结果的输出]
由于题目数据较为简单,直接使用for循环对题目与答案进行按序输出并判定正确与否即可。
2. 答题判题程序-2(第二次作业)
题目内容:
设计实现答题程序,模拟一个小型的测试,以下粗体字显示的是在答题判题程序-1基础上增补或者修改的内容。
要求输入题目信息、试卷信息和答题信息,根据输入题目信息中的标准答案判断答题的结果。
输入格式:
程序输入信息分三种,三种信息可能会打乱顺序混合输入:
1、题目信息
一行为一道题,可输入多行数据(多道题)。
格式:"#N:"+题目编号+" "+"#Q:"+题目内容+" "#A:"+标准答案
格式约束:
1、题目的输入顺序与题号不相关,不一定按题号顺序从小到大输入。 2、允许题目编号有缺失,例如:所有输入的题号为1、2、5,缺少其中的3号题。此种情况视为正常。样例:#N:1 #Q:1+1= #A:2
#N:2 #Q:2+2= #A:4
2、试卷信息
一行为一张试卷,可输入多行数据(多张卷)。
格式:"#T:"+试卷号+" "+题目编号+"-"+题目分值
题目编号应与题目信息中的编号对应。
一行信息中可有多项题目编号与分值。样例:#T:1 3-5 4-8 5-2
3、答卷信息
答卷信息按行输入,每一行为一张答卷的答案,每组答案包含某个试卷信息中的题目的解题答案,答案的顺序与试卷信息中的题目顺序相对应。
格式:"#S:"+试卷号+" "+"#A:"+答案内容
格式约束:答案数量可以不等于试卷信息中题目的数量,没有答案的题目计0分,多余的答案直接忽略,答案之间以英文空格分隔。
样例:#S:1 #A:5 #A:22
1是试卷号
5是1号试卷的顺序第1题的题目答案
22是1号试卷的顺序第2题的题目答案答题信息以一行"end"标记结束,"end"之后的信息忽略。
输出格式:
1、试卷总分警示
该部分仅当一张试卷的总分分值不等于100分时作提示之用,试卷依然属于正常试卷,可用于后面的答题。如果总分等于100分,该部分忽略,不输出。
格式:"alert: full score of test paper"+试卷号+" is not 100 points"
样例:alert: full score of test paper2 is not 100 points
2、答卷信息
一行为一道题的答题信息,根据试卷的题目的数量输出多行数据。
格式:题目内容+""+答案++""+判题结果(true/false)
约束:如果输入的答案信息少于试卷的题目数量,答案的题目要输"answer is null"
样例:3+2=5true
4+6=22false.
answer is null3、判分信息
判分信息为一行数据,是一条答题记录所对应试卷的每道小题的计分以及总分,计分输出的先后顺序与题目题号相对应。
格式:题目得分+" "+....+题目得分+"~"+总分
格式约束:
1、没有输入答案的题目计0分
2、判题信息的顺序与输入答题信息中的顺序相同
样例:5 8 0~13
根据输入的答卷的数量以上2、3项答卷信息与判分信息将重复输出。
4、提示错误的试卷号
如果答案信息中试卷的编号找不到,则输出”the test paper number does not exist”,参见样例9。
设计建议:
参考答题判题程序-1,建议增加答题类,类的内容以及类之间的关联自行设计。
输入样例1:
一张试卷一张答卷。试卷满分不等于100。例如:
N:1 #Q:1+1= #A:2
N:2 #Q:2+2= #A:4
T:1 1-5 2-8
S:1 #A:5 #A:22
end
输出样例1:
在这里给出相应的输出。例如:
alert: full score of test paper1 is not 100 points
1+1=5false
2+2=22false
0 0~0
输入样例2:
一张试卷一张答卷。试卷满分不等于100。例如:
N:1 #Q:1+1= #A:2
N:2 #Q:2+2= #A:4
T:1 1-70 2-30
S:1 #A:5 #A:22
end
输出样例2:
在这里给出相应的输出。例如:
1+1=5false
2+2=22false
0 0~0
输入样例3:
一张试卷、一张答卷。各类信息混合输入。例如:
N:1 #Q:1+1= #A:2
N:2 #Q:2+2= #A:4
T:1 1-70 2-30
N:3 #Q:3+2= #A:5
S:1 #A:5 #A:4
end
输出样例:
在这里给出相应的输出。例如:
1+1=5false
2+2=4true
0 30~30
输入样例4:
试卷题目的顺序与题号不一致。例如:
N:1 #Q:1+1= #A:2
N:2 #Q:2+2= #A:4
T:1 2-70 1-30
N:3 #Q:3+2= #A:5
S:1 #A:5 #A:22
end
输出样例:
在这里给出相应的输出。例如:
2+2=5false
1+1=22false
0 0~0
输入样例5:
乱序输入。例如:
N:3 #Q:3+2= #A:5
N:2 #Q:2+2= #A:4
T:1 3-70 2-30
S:1 #A:5 #A:22
N:1 #Q:1+1= #A:2
end
输出样例:
在这里给出相应的输出。例如:
3+2=5true
2+2=22false
70 0~70
输入样例6:
乱序输入+两份答卷。例如:
N:3 #Q:3+2= #A:5
N:2 #Q:2+2= #A:4
T:1 3-70 2-30
S:1 #A:5 #A:22
N:1 #Q:1+1= #A:2
S:1 #A:5 #A:4
end
输出样例:
在这里给出相应的输出。例如:
3+2=5true
2+2=22false
70 0~70
3+2=5true
2+2=4true
70 30~100
输入样例7:
乱序输入+分值不足100+两份答卷。例如:
N:3 #Q:3+2= #A:5
N:2 #Q:2+2= #A:4
T:1 3-7 2-6
S:1 #A:5 #A:22
N:1 #Q:1+1= #A:2
S:1 #A:5 #A:4
end
输出样例:
在这里给出相应的输出。例如:
alert: full score of test paper1 is not 100 points
3+2=5true
2+2=22false
7 0~7
3+2=5true
2+2=4true
7 6~13
输入样例8:
乱序输入+分值不足100+两份答卷+答卷缺失部分答案。例如:
N:3 #Q:3+2= #A:5
N:2 #Q:2+2= #A:4
T:1 3-7 2-6
S:1 #A:5 #A:22
N:1 #Q:1+1= #A:2
T:2 2-5 1-3 3-2
S:2 #A:5 #A:4
end
输出样例:
在这里给出相应的输出。例如:
alert: full score of test paper1 is not 100 points
alert: full score of test paper2 is not 100 points
3+2=5true
2+2=22false
7 0~7
2+2=5false
1+1=4false
answer is null
0 0 0~0
输入样例9:
乱序输入+分值不足100+两份答卷+无效的试卷号。例如:
N:3 #Q:3+2= #A:5
N:2 #Q:2+2= #A:4
T:1 3-7 2-6
S:3 #A:5 #A:4
end
输出样例:
在这里给出相应的输出。例如:
alert: full score of test paper1 is not 100 points
The test paper number does not exist
第二道题相较于第一道题多了试卷信息,以及输入格式中三种信息打乱顺序混合输入的要求。
但由于开始做的时间太晚,没有认真去思考各种信息之间的联系,导致有些样例中的测试点都没有过,而且输入数据的处理与存储没有做好,一旦乱序输入,答案就会发生错误。
有了第一次作业的教训,本次题目我采用了四个类,题目类、试卷类、答题类、以及主类(后面发现缺少了一个控制类,用来储存方法,降低类之间的耦合性)。
-
[ UML图]
UML图如下:
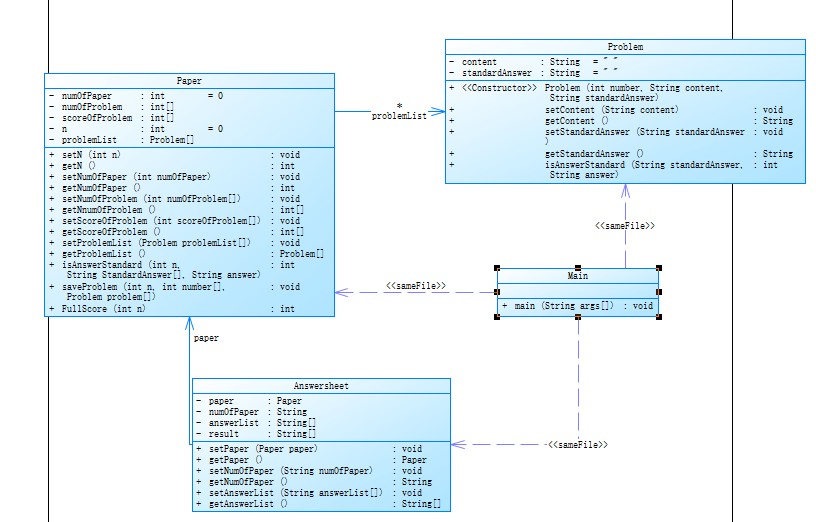
-
[SourceMontor的生成报表 ]

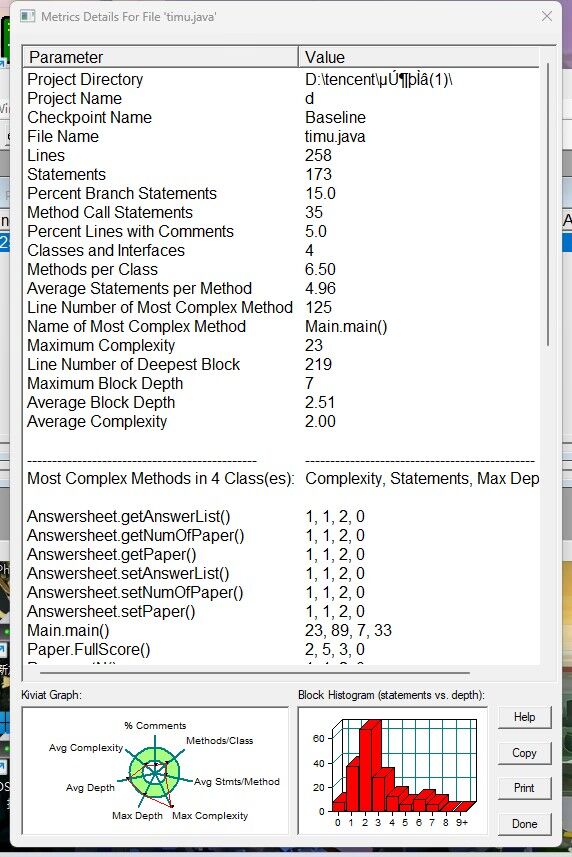
第二道题没过的测试点就有点多了:
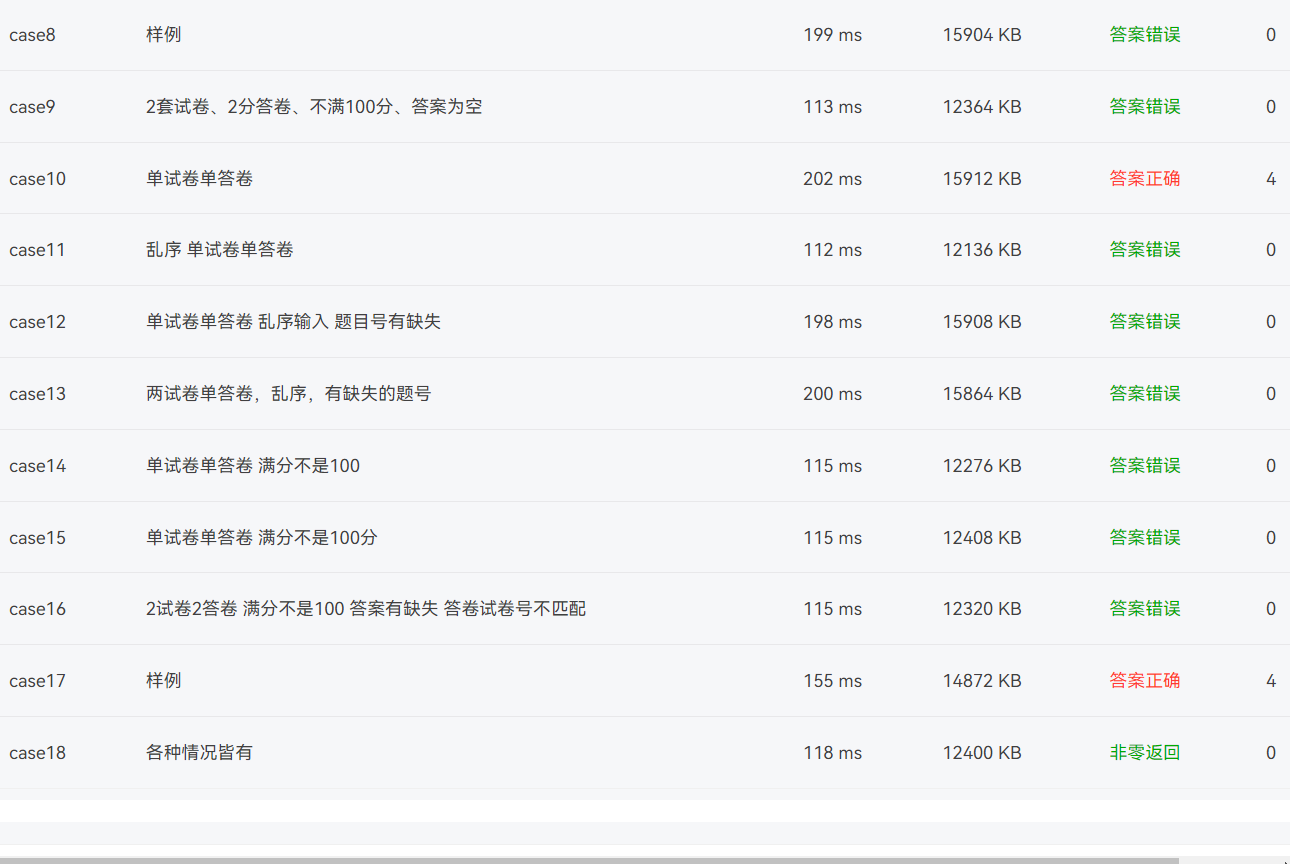
3.答题判题程序-3
题目内容:
设计实现答题程序,模拟一个小型的测试,以下粗体字显示的是在答题判题程序-2基础上增补或者修改的内容,要求输入题目信息、试卷信息、答题信息、学生信息、删除题目信息,根据输入题目信息中的标准答案判断答题的结果。
输入格式:
程序输入信息分五种,信息可能会打乱顺序混合输入。
1、题目信息
题目信息为独行输入,一行为一道题,多道题可分多行输入。
格式:"#N:"+题目编号+" "+"#Q:"+题目内容+" "#A:"+标准答案
格式约束:
1、题目的输入顺序与题号不相关,不一定按题号顺序从小到大输入。
2、允许题目编号有缺失,例如:所有输入的题号为1、2、5,缺少其中的3号题。此种情况视为正常。
样例:#N:1 #Q:1+1= #A:2
#N:2 #Q:2+2= #A:42、试卷信息
试卷信息为独行输入,一行为一张试卷,多张卷可分多行输入数据。
格式:"#T:"+试卷号+" "+题目编号+"-"+题目分值+" "+题目编号+"-"+题目分值+...
格式约束:
题目编号应与题目信息中的编号对应。
一行信息中可有多项题目编号与分值。
样例:#T:1 3-5 4-8 5-23、学生信息
学生信息只输入一行,一行中包括所有学生的信息,每个学生的信息包括学号和姓名,格式如下。
格式:"#X:"+学号+" "+姓名+"-"+学号+" "+姓名....+"-"+学号+" "+姓名
格式约束:
答案数量可以不等于试卷信息中题目的数量,没有答案的题目计0分,多余的答案直接忽略,答案之间以英文空格分隔。
样例:
#S:1 #A:5 #A:22
1是试卷号
5是1号试卷的顺序第1题的题目答案
4、答卷信息
答卷信息按行输入,每一行为一张答卷的答案,每组答案包含某个试卷信息中的题目的解题答案,答案的顺序号与试 卷信息中的题目顺序相对应。答卷中:
格式:"#S:"+试卷号+" "+学号+" "+"#A:"+试卷题目的顺序号+"-"+答案内容+...
格式约束:
答案数量可以不等于试卷信息中题目的数量,没有答案的题目计0分,多余的答案直接忽略,答案之间以英文空格分隔。
答案内容可以为空,即””。
答案内容中如果首尾有多余的空格,应去除后再进行判断。
样例:
#T:1 1-5 3-2 2-5 6-9 4-10 7-3
#S:1 20201103 #A:2-5 #A:6-4
1是试卷号
20201103是学号
2-5中的2是试卷中顺序号,5是试卷第2题的答案,即T中3-2的答案
6-4中的6是试卷中顺序号,4是试卷第6题的答案,即T中7-3的答案
注意:不要混淆顺序号与题号
5、删除题目信息
删除题目信息为独行输入,每一行为一条删除信息,多条删除信息可分多行输入。该信息用于删除一道题目信息,题目被删除之后,引用该题目的试卷依然有效,但被删除的题目将以0分计,同时在输出答案时,题目内容与答案改为一条失效提示,例如:”the question 2 invalid~0”
格式:"#D:N-"+题目号
格式约束:
题目号与第一项”题目信息”中的题号相对应,不是试卷中的题目顺序号。
本题暂不考虑删除的题号不存在的情况。样例:
N:1 #Q:1+1= #A:2
N:2 #Q:2+2= #A:4
T:1 1-5 2-8
X:20201103 Tom-20201104 Jack
S:1 20201103 #A:1-5 #A:2-4
D:N-2
end
输出
alert: full score of test paper1 is not 100 points
1+1=5false
the question 2 invalid~0
20201103 Tom: 0 0~0
答题信息以一行"end"标记结束,"end"之后的信息忽略。
输出格式:
1、试卷总分警示
该部分仅当一张试卷的总分分值不等于100分时作提示之用,试卷依然属于正常试卷,可用于后面的答题。如果总分等于100 分,该部分忽略,不输出。
格式:"alert: full score of test paper"+试卷号+" is not 100 points"
样例:alert: full score of test paper2 is not 100 points
2、答卷信息
一行为一道题的答题信息,根据试卷的题目的数量输出多行数据。
格式:题目内容+""+答案++""+判题结果(true/false)
约束:如果输入的答案信息少于试卷的题目数量,答案的题目要输"answer is null"
样例:
3+2=5true
4+6=22false.
answer is null
3、判分信息
判分信息为一行数据,是一条答题记录所对应试卷的每道小题的计分以及总分,计分输出的先后顺序与题目题号相对应。
格式:**学号+" "+姓名+": "**+题目得分+" "+....+题目得分+"~"+总分
格式约束:
1、没有输入答案的题目、被删除的题目、答案错误的题目计0分 2、判题信息的顺序与输入答题信息中的顺序相同 样例:20201103 Tom: 0 0~0
根据输入的答卷的数量以上2、3项答卷信息与判分信息将重复输出。4、被删除的题目提示信息
当某题目被试卷引用,同时被删除时,答案中输出提示信息。样例见第5种输入信息“删除题目信息”。
5、题目引用错误提示信息
试卷错误地引用了一道不存在题号的试题,在输出学生答案时,提示”non-existent question~”加答案。例如:
输入:
N:1 #Q:1+1= #A:2
T:1 3-8
X:20201103 Tom-20201104 Jack-20201105 Www
S:1 20201103 #A:1-4
end
输出:
alert: full score of test paper1 is not 100 points
non-existent question~0
20201103 Tom: 0~0
如果答案输出时,一道题目同时出现答案不存在、引用错误题号、题目被删除,只提示一种信息,答案不存在的优先级最高,例如:
输入:N:1 #Q:1+1= #A:2
T:1 3-8
X:20201103 Tom-20201104 Jack-20201105 Www
S:1 20201103
end
输出:
alert: full score of test paper1 is not 100 points
answer is null
20201103 Tom: 0~0
6、格式错误提示信息
输入信息只要不符合格式要求,均输出”wrong format:”+信息内容。
例如:wrong format:2 #Q:2+2= #47、试卷号引用错误提示输出
如果答卷信息中试卷的编号找不到,则输出”the test paper number does not exist”,答卷中的答案不用输出,参见样例8。
8、学号引用错误提示信息
如果答卷中的学号信息不在学生列表中,答案照常输出,判分时提示错误。参见样例9。
本题暂不考虑出现多张答卷的信息的情况。
输入样例1:
简单输入,不含删除题目信息。例如:
N:1 #Q:1+1= #A:2
T:1 1-5
X:20201103 Tom
S:1 20201103 #A:1-5
end
输出样例1:
在这里给出相应的输出。例如:
alert: full score of test paper1 is not 100 points
1+1=5false
20201103 Tom: 0~0
输入样例2:
简单输入,答卷中含多余题目信息(忽略不计)。例如:
N:1 #Q:1+1= #A:2
T:1 1-5
X:20201103 Tom
S:1 20201103 #A:1-2 #A:2-3
end
输出样例3
简单测试,含删除题目信息。例如:
alert: full score of test paper1 is not 100 points
1+1=2true
20201103 Tom: 5~5
输入样例3:
简单测试,含删除题目信息。例如:
N:1 #Q:1+1= #A:2
N:2 #Q:2+2= #A:4
T:1 1-5 2-8
X:20201103 Tom-20201104 Jack-20201105 Www
S:1 20201103 #A:1-5 #A:2-4
D:N-2
end
输出样例3:
在这里给出相应的输出,第二题由于被删除,输出题目失效提示。例如:
alert: full score of test paper1 is not 100 points
1+1=5false
the question 2 invalid~0
20201103 Tom: 0 0~0
输入样例4:
简单测试,含试卷无效题目的引用信息以及删除题目信息(由于题目本身无效,忽略)。例如:
N:1 #Q:1+1= #A:2
N:2 #Q:2+2= #A:4
T:1 1-5 3-8
X:20201103 Tom-20201104 Jack-20201105 Www
S:1 20201103 #A:1-5 #A:2-4
D:N-2
end
输出样例4:
输出不存在的题目提示信息。例如:
alert: full score of test paper1 is not 100 points
1+1=5false
non-existent question~0
20201103 Tom: 0 0~0
输入样例5:
综合测试,含错误格式输入、有效删除以及无效题目引用信息。例如:
N:1 +1= #A:2
N:2 #Q:2+2= #A:4
T:1 1-5 2-8
X:20201103 Tom-20201104 Jack-20201105 Www
S:1 20201103 #A:1-5 #A:2-4
D:N-2
end
输出样例5:
在这里给出相应的输出。例如:
wrong format:#N:1 +1= #A:2
alert: full score of test paper1 is not 100 points
non-existent question~0
the question 2 invalid~0
20201103 Tom: 0 0~0
输入样例6:
综合测试,含错误格式输入、有效删除、无效题目引用信息以及答案没有输入的情况。例如:
N:1 +1= #A:2
N:2 #Q:2+2= #A:4
T:1 1-5 2-8
X:20201103 Tom-20201104 Jack-20201105 Www
S:1 20201103 #A:1-5
D:N-2
end
输出样例6:
答案没有输入的优先级最高。例如:
wrong format:#N:1 +1= #A:2
alert: full score of test paper1 is not 100 points
non-existent question~0
answer is null
20201103 Tom: 0 0~0
输入样例7:
综合测试,正常输入,含删除信息。例如:
N:2 #Q:2+2= #A:4
N:1 #Q:1+1= #A:2
T:1 1-5 2-8
X:20201103 Tom-20201104 Jack-20201105 Www
S:1 20201103 #A:2-4 #A:1-5
D:N-2
end
输出样例7:
例如:
alert: full score of test paper1 is not 100 points
1+1=5false
the question 2 invalid~0
20201103 Tom: 0 0~0
输入样例8:
综合测试,无效的试卷引用。例如:
N:1 #Q:1+1= #A:2
T:1 1-5
X:20201103 Tom
S:2 20201103 #A:1-5 #A:2-4
end
输出样例8:
例如:
alert: full score of test paper1 is not 100 points
The test paper number does not exist
输入样例9:
无效的学号引用。例如:
N:1 #Q:1+1= #A:2
T:1 1-5
X:20201106 Tom
S:1 20201103 #A:1-5 #A:2-4
end
输出样例9:
答案照常输出,判分时提示错误。例如:
alert: full score of test paper1 is not 100 points
1+1=5false
20201103 not found
输入样例10:
信息可打乱顺序输入:序号不是按大小排列,各类信息交错输入。但本题不考虑引用的题目在被引用的信息之后出现的情况(如试卷引用的所有题目应该在试卷信息之前输入),所有引用的数据应该在被引用的信息之前给出。例如:
N:3 #Q:中国第一颗原子弹的爆炸时间 #A:1964.10.16
N:1 #Q:1+1= #A:2
X:20201103 Tom-20201104 Jack-20201105 Www
T:1 1-5 3-8
N:2 #Q:2+2= #A:4
S:1 20201103 #A:1-5 #A:2-4
end
输出样例10:
答案按试卷中的题目顺序输出。例如:
alert: full score of test paper1 is not 100 points
1+1=5false
中国第一颗原子弹的爆炸时间4false
20201103 Tom: 0 0~0
第三道题对比前两道题目难度大幅提升,除了信息种类增加的原因外,其主要原因还在于输出情况太多,过于复杂,难以理清其中的先后主次关系,需要联合题目和大量样例来理解。我在做这道题时,花了差不多有三四天的时间来理解题目,在草稿纸上写下自己的解题思路,每一步应该怎么做,当然,写出来的不一定正确,需要用多个实例进行推演,修改,来定下最终的方案(个人认为这种做题过程很有效,比一拿到题就开始写代码效率要高的多)。
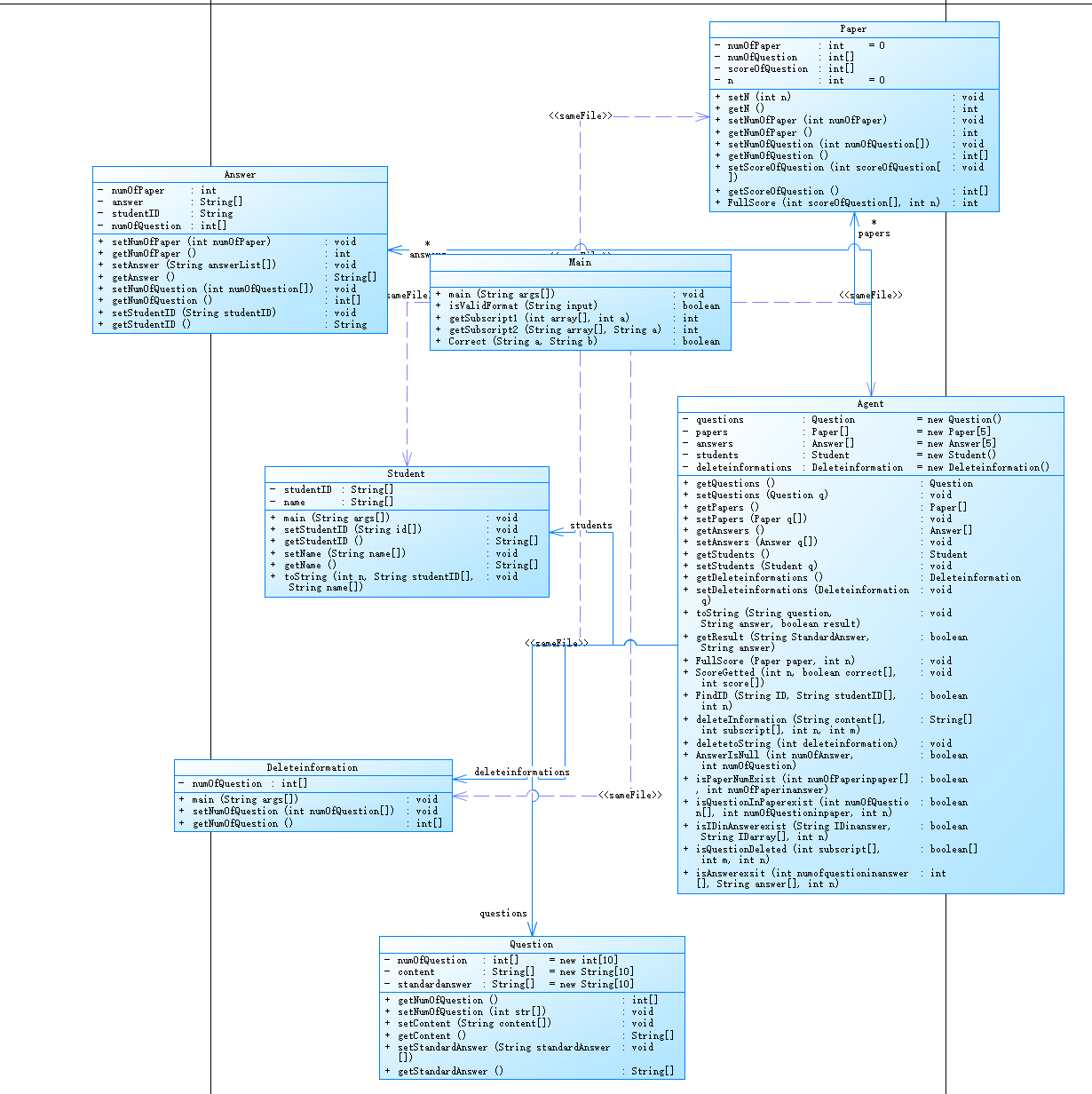
吸取了前两次的教训,这道题相对于更加符合题目的要求,但仍然有许多地方需要改进。我总共设置了七个类,分别是题目类、答卷类、试卷类、学生类、删除信息类、控制类、以及主类。
-
[UML图 ]
UML图如下:
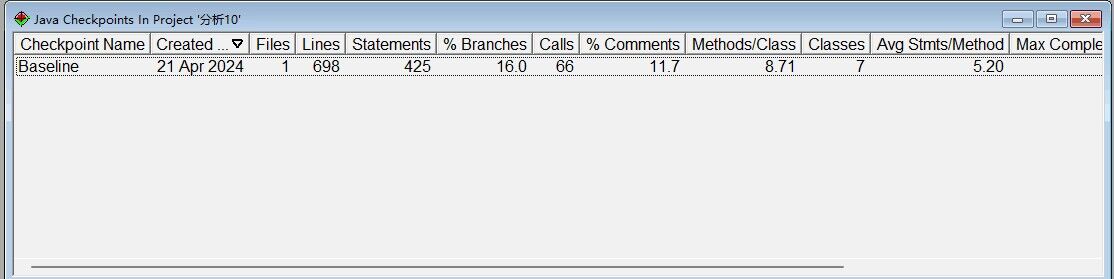
-
[SourceMontor的生成报表 ]
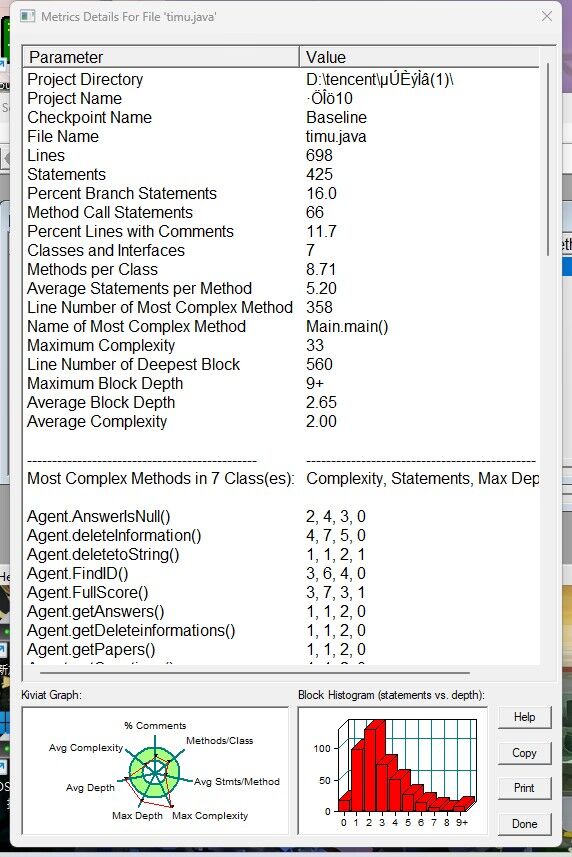
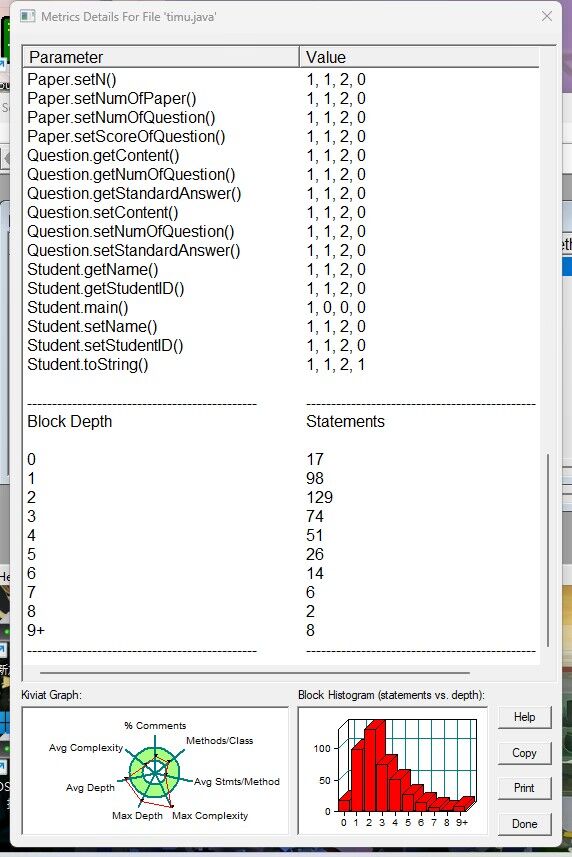
还有后面六个测试点没过,错误原因为答案错误和非零返回。
(希望有哪个大佬能够指点一下)
第三道题在分割字符串的过程中,我仍然选择了使用了Split函数,但是不太推荐这种方法,因为很容易造成非零返回,需要一个步骤一个步骤地进行测试查看数据,比较麻烦,还是比较推荐使用正则表达式,即Pattern和Matcher的方法。
除此以外,还是建议多建立几个相关的方法,要不然主函数中代码太多,容易变得混乱,而且这样也能够应对后续的题目迭代,减少修改次数。
注释在做题时也是非常有用的,因为数据太多,可能很容易弄混,加上注释之后就很容易找了。
四、总结
这三道题,在做的时候确实感觉很痛苦,天天想着这个,觉也睡不好。但是做完之后,再去回顾,感觉却又没有那么难,甚至还能针对自己写出的代码想出一些改进措施,来运用到下一次的作业中,这种感觉倒是还挺不错的。
经过这三周的作业练习,我学习到了许多。从一开始的建多个类都要上网查怎么做,认为很麻烦,到现在的习惯性建类,并且其中的方法越多越好,从一开始的连正则表达式是什么都不知道,到现在的能够使用它(虽然还不太熟悉,不过可以多加练习),还有有了该如何做作业的经验。
我认为对于类的设计,代码的整体设计还是比较重要的,这方面很重要,并且需要进一步地学习研究。
五、对课程的建议
对于课堂方面,希望能够讲解一下PTA或写过的作业,因为做过的题目,大家都知道有哪些地方不懂,讲解一遍的话可以解开同学们的疑惑。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号