


Python基础2 列表、字典、集合
1、列表
#1.1 切片 names = ["zhangsan","lisi","wangwu","zhuqi"] print(names[0],names[2]) #取第1个和第3个 print(names[0:3]) # 切片 取前三个 print(names[:3]) # 切片 取前三个 print(names[-1]) #取最后一个 print(names[-3:-1]) #切片 取倒数第3和倒数第2个 print(names[-3:]) #切片 取倒数1,2,3
print(names[0:-1:2]) #切片 步长为2
#1.2插入 names = ["zhangsan","lisi","wangwu","zhuqi"] names.append("新加入成员") #追加到最后 names.insert(2,"insert插入") #插入到2这个位置其他后移
#1.3修改 names = ["zhangsan","lisi","wangwu","zhuqi"] names[1] = "bobo" #将第二个成员改为bobo
#1.4删除 names = ["zhangsan","lisi","wangwu","zhuqi","wangba"] del names[1] #删除下标为1的成员 names.remove("wangwu") #删除指定成员,无返回 names.pop() #删除最后一个,返回删除成员 names.pop(1) #删除下标为1的成员 print(names)
#1.5 获取元素位置 names = ["zhangsan","lisi","wangwu","zhuqi","wangba"] names.index("lisi") #返回1
#1.6 扩展 >>> names = ["zhangsan","lisi","wangwu","zhuqi","wangba"] >>> names2 = [1,2,3] >>> names.extend(names2) >>> names ['zhangsan', 'lisi', 'wangwu', 'zhuqi', 'wangba', 1, 2, 3]
#1.7 排序 >>> names = ["zhangsan","lisi","wangwu","zhuqi","wangba"] >>> names2 = [3,5,4,2,1] >>> names.sort(reverse=True) #降序 >>> names2.sort() #升序,默认reverse=False >>> names ['zhuqi', 'zhangsan', 'wangwu', 'wangba', 'lisi'] >>> names2 [1, 2, 3, 4, 5]
#1.8 copy 浅copy和深copy >>> names = ["zhangsan","lisi","wangwu",[1,2,3],"zhuqi"] >>> names2 = names.copy() #等同names2=names[:] 或 names2 = copy.copy(names)或 names2 = list(names) 浅copy >>> names ['zhangsan', 'lisi', 'wangwu', [1, 2, 3], 'zhuqi'] >>> names2 ['zhangsan', 'lisi', 'wangwu', [1, 2, 3], 'zhuqi'] >>> names[2]="香蕉" >>> names[3][0]="苹果" >>> names ['zhangsan', 'lisi', '香蕉', ['苹果', 2, 3], 'zhuqi'] >>> names2 ['zhangsan', 'lisi', 'wangwu', ['苹果', 2, 3], 'zhuqi'] #深copy 完全独立 import copy names = ["zhangsan","lisi","wangwu",[1,2,3],"zhuqi","wangba"] names2 = copy.deepcopy(names) print(names) print(names2) names[2]="香蕉" names[3][0] = "苹果" print(names) print(names2)
#1.9 count函数 >>> names = ["zhangsan","lisi","lisi"] >>> names.count("lisi") 2
#1.10 列表条件选择 a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] l = [i for i in a if i%2==1] print(l)
2、元组
一旦创建,便不能再修改,可以理解成只读列表
>>> names = ("zhangsan","lisi","wangwu") >>> names[0] 'zhangsan' >>> names.index("lisi") 1 >>> names.count("wangwu") 1 >>>
它只有2个方法,一个是count,一个是index
3、字典
字典一种key:value 的数据类型
语法:
>>> dict={"s1":"zhangsan","s2":"lisi","s3":"wangwu"} #创建
>>> dict
{'s1': 'zhangsan', 's2': 'lisi', 's3': 'wangwu'}
>>> dict["s2"] #查看
'lisi'
>>>s2 in dict
>>>True
>>>dict.get("s2")
>>>"lisi"
>>> dict["s2"]="wangba" #修改
>>> dict
{'s1': 'zhangsan', 's2': 'wangba', 's3': 'wangwu'}
>>> dict["s4"]="new_s" #增加
>>> dict
{'s1': 'zhangsan', 's2': 'wangba', 's3': 'wangwu', 's4': 'new_s'}
>>> del dict["s1"] #删除
>>> dict
{'s2': 'wangba', 's3': 'wangwu', 's4': 'new_s'}
>>> dict.pop("s2") #删除
'wangba'
>>> dict
{'s3': 'wangwu', 's4': 'new_s'}
字典循环
info = { 's1': "zhangsan", 's2': "lisi", 's3': "wangwu", } for key in info: #建议 print(key,info[key]) for k,v in info.items(): #不建议,效率低 print(k,v)
4、集合
集合是一个无序的,不重复的数据组合,它的主要作用如下:
去重,把一个列表变成集合,就自动去重了
关系测试,测试两组数据之前的交集、差集、并集等关系
>>> s = set([3,5,9,10]) >>> s {9, 10, 3, 5} >>> t = set("Hello") >>> t {'l', 'H', 'o', 'e'}
#基本操作 a = t | s # t 和 s的并集 b = t & s # t 和 s的交集 c = t – s # 求差集(项在t中,但不在s中) d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中) 基本操作: t.add('x') # 添加一项 s.update([10,37,42]) # 在s中添加多项 使用remove()可以删除一项: t.remove('H') #无该项会报错
t.discard('H') #无该项pass len(s) set 的长度 x in s 测试 x 是否是 s 的成员 x not in s 测试 x 是否不是 s 的成员 s.issubset(t) s <= t 测试是否 s 中的每一个元素都在 t 中 s.issuperset(t) s >= t 测试是否 t 中的每一个元素都在 s 中 s.union(t) s | t 返回一个新的 set 包含 s 和 t 中的每一个元素 s.intersection(t) s & t 返回一个新的 set 包含 s 和 t 中的公共元素 s.difference(t) s - t 返回一个新的 set 包含 s 中有但是 t 中没有的元素 s.symmetric_difference(t) s ^ t 返回一个新的 set 包含 s 和 t 中不重复的元素 s.copy() 返回 set “s”的一个浅复制
五、文件操作
#读写基本操作
f = open("file1",'r+',encoding="utf-8") #文件句柄 f.write("CCCCCC\n") f.write("DDDDDD\n") # for i in range(5): #低效 # print(f.readline()) # # for line in f.readlines(): #低效 # print(line.strip()) #最高效方法,忘记其他 for line in f: print(line.strip()) f.close()
打开文件的模式有: r,只读模式(默认)。 w,只写模式。【不可读;不存在则创建;存在则删除内容;】 a,追加模式。【可读; 不存在则创建;存在则只追加内容;】 "+" 表示可以同时读写某个文件 r+,可读写文件。【可读;可写;可追加】 w+,写读 a+,同a "U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用) rU r+U "b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注) rb wb ab
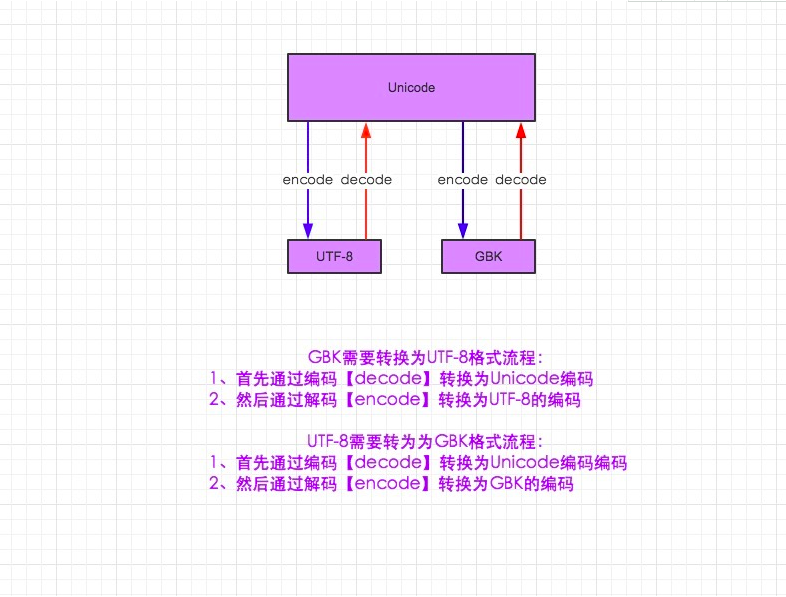
6、字符编码与转码
需知:
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
import sys print(sys.getdefaultencoding()) msg = "我爱北京天安门" #msg_gb2312 = msg.decode("utf-8").encode("gb2312") msg_gb2312 = msg.encode("gb2312") #默认就是unicode,不用再decode gb2312_to_unicode = msg_gb2312.decode("gb2312") gb2312_to_utf8 = msg_gb2312.decode("gb2312").encode("utf-8") print(msg) print(msg_gb2312) print(gb2312_to_unicode) print(gb2312_to_utf8)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号