常用卷积神经网络精炼总结(复习用)
本文总结了目前依然常用常见的卷积神经网络的特点,仅作为复习使用,具体细节建议阅读原论文
①Resnet

1. 拟合残差,网络退化或者消失的主要原因是多个非线性层无法构建恒等映射,解决方法之一就是引入残差。让模型内部至少有恒等映射的能力。
2. resent可以看作是路径的集合,类似集成模型,从输入到输出存在许多不同长度的路径。(让模型自身结构选择更加灵活)
3. 引入有效路径,加强前后层信息融合;且有效路径都是短路径,不是让梯度流通整个网络,而是在深层引入传输梯度的短路径。
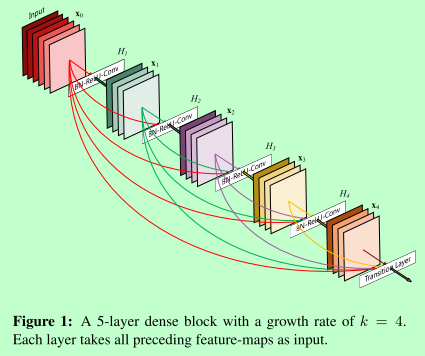
②Densenet
一句话:跳跃连接的极致,将所有层的状态全部保存到集体知识中,加强特征的传递。
1. 密集连接,减轻梯度消失
2. 每层的维度减少,减少参数量,类似正则化,减少过拟合的风险
3. 加强feature map的传递,更高效利用feature
③Inception系列
一句话:密集的块结构来近似最优的稀疏结构
V1:
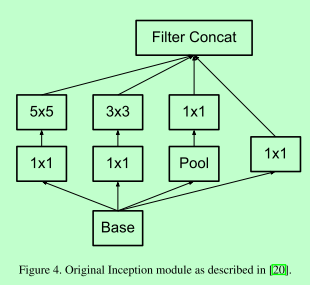
1. 多个小卷积核代替大卷积核,参数少;同时获取多种感受野
2. 1*1卷积降维,跨通道信息融合;避免表示瓶颈,最大池化前进行升维
3. 辅助softmax,将有用的梯度注入模型低层(对抗梯度消失)
V2:
Batch normliazation
V3:
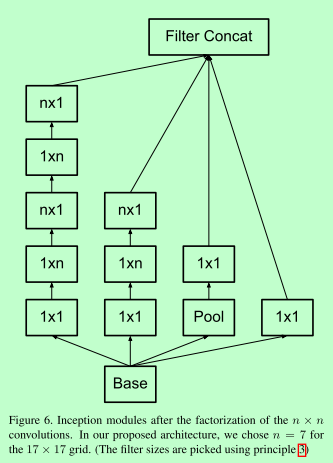
1. 避免表示瓶颈,对应pool,特征图尺寸应该从输入到输出缓慢减小
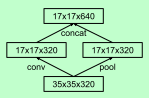
2. 空间聚合可以在低维进行,3*3之前的降维
3. (核心)高维特征更容易局部处理,使用稀疏表示,对应串行不对称卷积(中高层特征图适用)7*7 -> 1*7,7*1,减少计算量
4. 平衡深度和宽度
tricks:
Label smoothing , 通过权重调节,改变真实标签分布,达到正则化效果,阻止最大的Logit过于自信,增强泛化能力。
④Xception

1. 基于inception的假设,特征图的跨通道相关性与空间相关性已充分解耦合,不需要联合映射。
2. 极限的inception,把空间卷积与通道卷积分离,参数量和计算量大大减小
计算量:
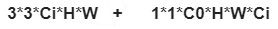
⑤SEnet

一句话:通道注意力机制,显示地建模特征通道之间的相互依赖关系,选择性的强调部分特征,抑制其他特征
1. Squeeze, 把每个通道信息压缩生成通道描述符,使用gap。
2. Excitation, 对通道信息建模生成权重
3. 加权输出新的feature
存在一个bottleneck

⑥cbam
同时进行通道注意力机制以及空间注意力机制,采用maxpooling与averpooling一起做gap
空间注意力机制,即在一个像素点的位置所有通道内的点进行gap。
⑦MoblieNet系列, 记好论文题目
V1: efficient cnn for moble
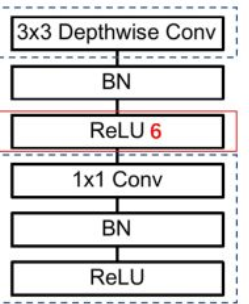
1. 使用深度可分离卷积,参数和计算量少
2. Relu6 (低精度下鲁棒性高)
Dw -> bn -> relu6 -> 1*1 conv -> bn -> relu
引入一个减少参数量的超参数:
所有层的 通道数乘以 α 参数,模型大小近似下降到原来的 α 2 倍,计算量下降到原来的 α 2 倍
V2: inverted residuals and liner bottlenecks

1. 引入残差连接
2. 引入倒置瓶颈结构(与resnet相反),因为维度过低导致特征提取不充分,故先升维后降维。
升维1*1 -> bn -> relu6 -> dw -> bn -> relu6 -> 降维 1*1
3. 替换relu6为线性连接 (relu在低维的时候容易破坏特征)
v3: serching for mb3
1. 使用mnasnet作为基础的模块(nas搜索出来的资源受限的网络结构)
2. 引入senet,通道注意力机制,对某些特征重点关注
3. 使用h-swish(reLu实现),替换swish的复杂操作(适配更多硬件),使用hard形式逼近swish的函数曲线。
swish函数,nas搜索得到

只在后半网络使用, 因网络加深,使用非线性激活函数的计算量越小
网络开销主要在卷积计算上,轻量级网络主要是1*1卷积,1*1卷积不需要Img2col,更快。
⑧shuffleNet

a. 输入通道与输出通道相同的时候,mac会在flops相同的情况下减少,特征图以及卷积核参数量是mac
(输入特征图存储hwc1,输出特征图存储hwc2,以及权重存储1*1*c1*c2)

推导关键是令c2这一步,化简之后可以根据a+b>=2*sqrt(ab)得到,c1=c2时最小
b. 过量使用组卷积会增加mac,分组数要选好
c. 碎片化网络会降低并行度,影响速度(inception, 多路结构)
d. 注意元素级操作,add操作等
⑨Efficient-net
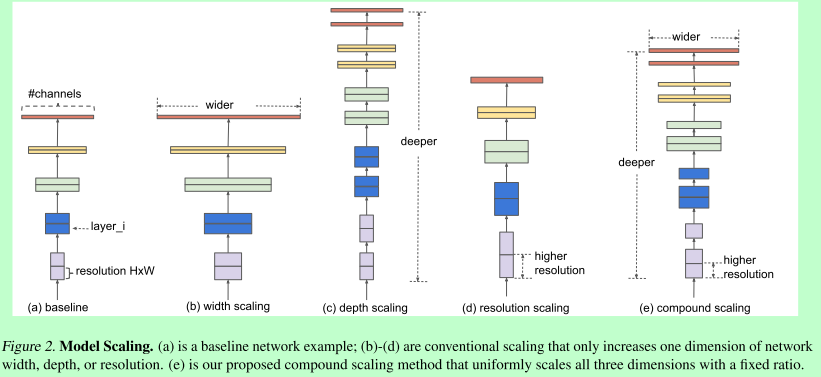
1. 优化目标,基础结构不变例如k,s

2. 复合扩张方法, 根据算力改变缩放系数即可

3. 求解方式:

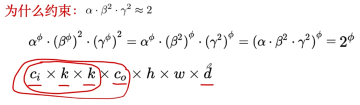
缩放的核心在于2的次方,次方是1的时候代表算力是B0的2倍,后续例如算力提升10倍,2的3.3次方等于10,那么缩放系数就是3
但是缺点是推理速度不快:相同的flops,element-wise能处理更多的数据量,通过处理更多的数据量来贴合给你精度,但是大量数据读取受限于gpu带宽,导致推理速度慢。如果利用相同的数据量训练,逐元素卷积在精度上比普通卷积低。
⑩Dilated conv
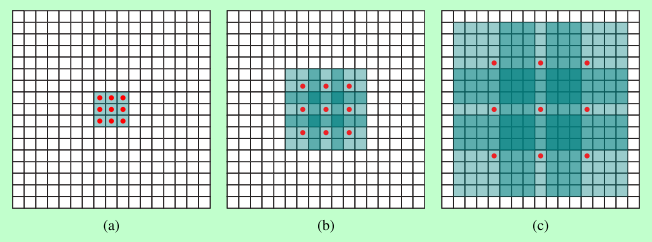
1. 在避免使用down sampling 时增大感受野, 实现方式是在普通卷积核中插入0,atros为多少就插入几个0
2. 感受野计算方式:(r*s)+ (k-s) , 带洞卷积感受野计算就先算出模拟多大卷积核(k+d*(k+1)),然后带入公式即可
3. 缺点,使用单一尺度的dilated conv不能同时处理不同大小物体的关系,故转向多级的形式,如aspp
附:多尺度语义分割的形式:①image pyramid ② unet类 ③ASPP ④SPP(不同尺度池化,然后拉成一维,拼接起来,固定维度)
带来棋盘效应,解决方法:去掉最开始的池化;渐进式的空洞卷积;去掉残差
⑩①DCN
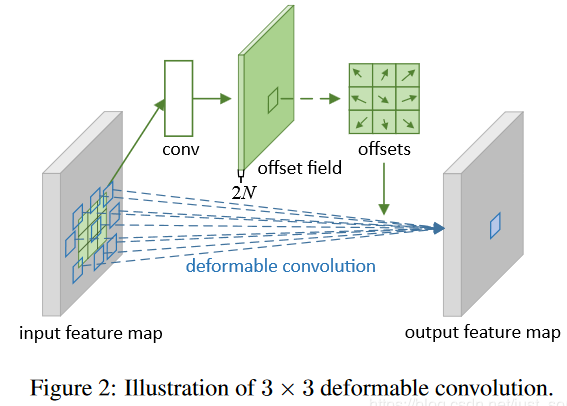
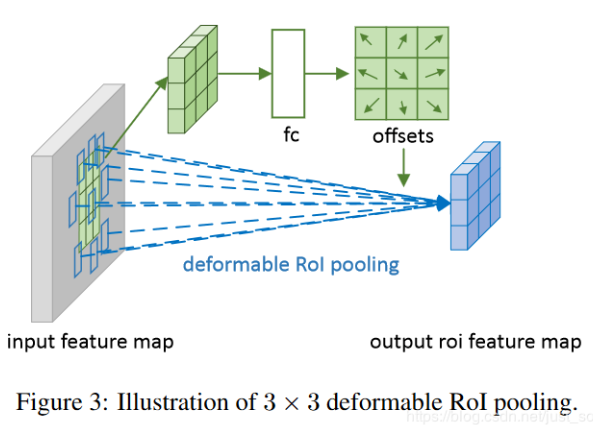
出发点:图像中目标的尺寸形状变化不一
一句话:使网络在提取特征的时候把注意力聚焦在训练目标上,覆盖不同形状尺寸的目标,动态调整感受野。
1. 可形变卷积
两层结构,上层通过卷积学习到offset(卷积核个数2*k*k,对应每个位置的x,y偏置),下层根据offset先调整位置,再使用卷积提取特征
2. 可形变ROI POOLING
两层结构,上层提取ROI通过FC学习到offset(FC输出节点2*bin个数), 下层根据offset先调整位置,再使用Roi pooling
⑩②SKNET
split -> fuse -> select
1.首先使用不同的卷积核对原图进行卷积
下面就是split attention的步骤:
2.逐元素相加不同特征图,gap->fc->softmax,学习每个通道占的比重(与senet一样,先gap再压缩维度,在扩展到原维度)
3.比重乘回原通道,各个组直接相加。
⑩③ResNest
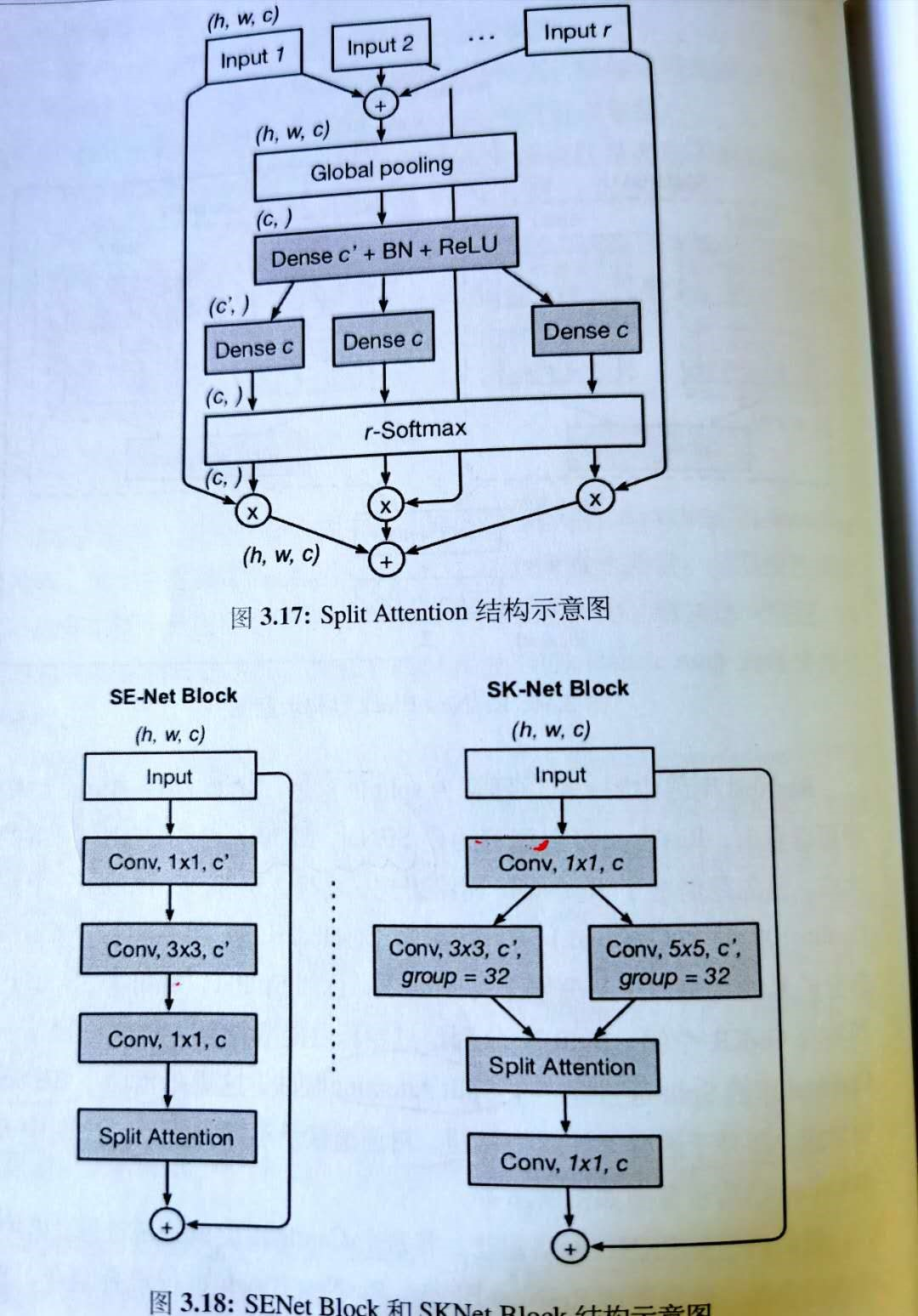
可以认为是senet、sknet、resnext的集大成。
1. 先resnext类似,分成大组(减小计算量)
2. 把每个大组,借鉴sknet,分成几个分支(可选核分支,模型灵活性,多感受野)
3. 再用sknet的合并,split attendion, 先得到每个分支的通道权重(senet),分别相乘后再相加
4. 最后 concat 每个大组
使用的Mixup数据增强方法: 把两张图片按权重线性相加,一张图片中出现两张图片的目标
⑩④CSPnet
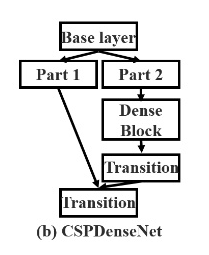
提出原因:发现大量重复的梯度信息被用来更新不同密集层的权重。 这将导致不同的密集层重复学习相同梯度信息
cspnet使得网络结构能够实现更加丰富的梯度组合信息,同时减小计算量。
通过将基础的特征图划分成两部分,(同一个特征图送入两个不同的卷积,两个卷积输出的通道数减半)然后通过提出的跨阶段层次结果将他们融合。主要概念是截断梯度流,截断后加一个过渡层,使梯度流通过不同的网络路径传播,防止不同的层学习重复的梯度信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号